管理者メニュー#
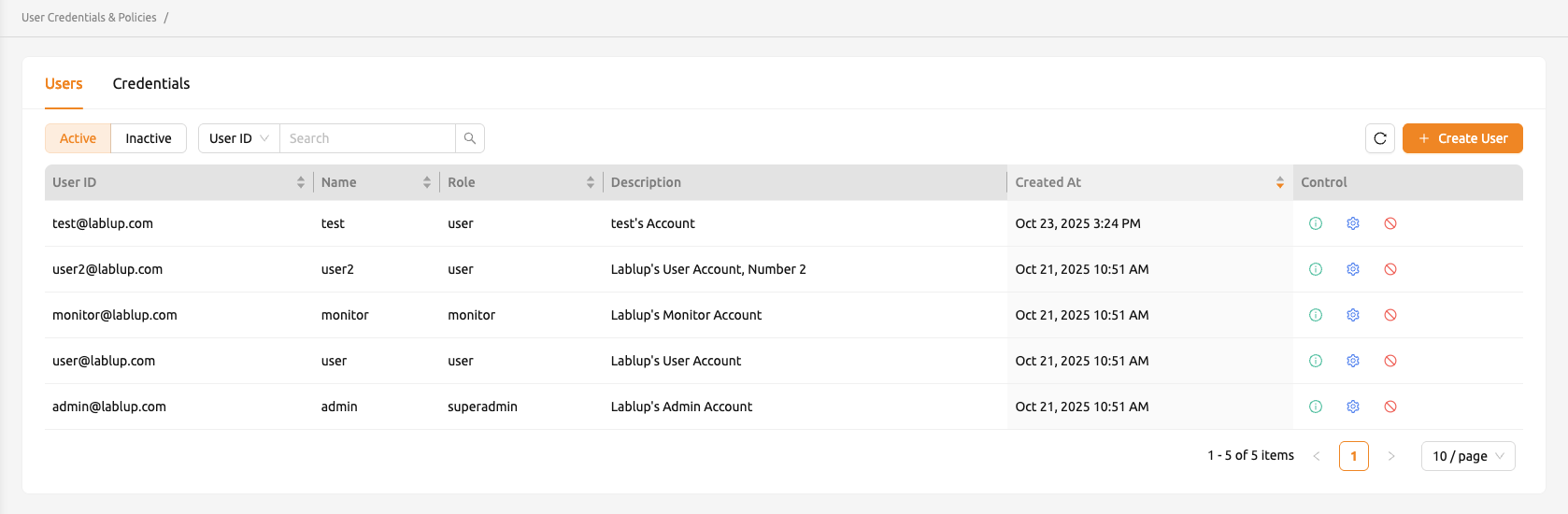
管理者アカウントでログインすると、サイドバー左下に追加のAdministrationメニューが表示されます。 Backend.AIに登録されたユーザー情報は、Usersタブに一覧表示されます。 スーパー管理者のロールを持つユーザーは、すべてのユーザーの情報を確認し、ユーザーを作成および無効化できます。
ユーザーID(メールアドレス)、名前(ユーザー名)、ロール、説明(ユーザーの説明)は、各カラムヘッダーの 検索ボックスにテキストを入力することでフィルタリングできます。
ユーザーの作成と更新#
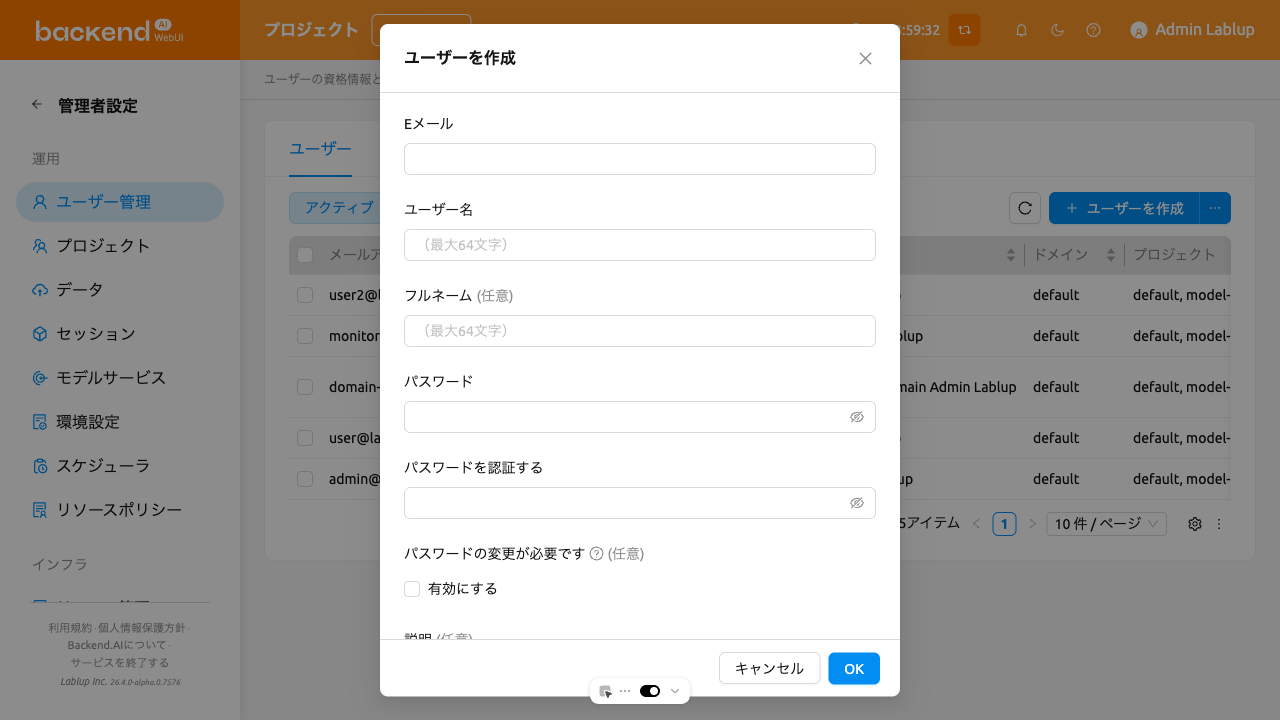
「+ ユーザーを作成」ボタンをクリックしてユーザーを作成できます。パスワードは8文字以上で、アルファベット、特殊文字、数字をそれぞれ1つ以上含む必要があります。メールアドレス、ユーザー名、フルネームの最大長は64文字です。
同じメールアドレスまたはユーザー名のユーザーが既に存在する場合、ユーザーアカウントを作成することはできません。他のメールアドレスとユーザー名を試してください。
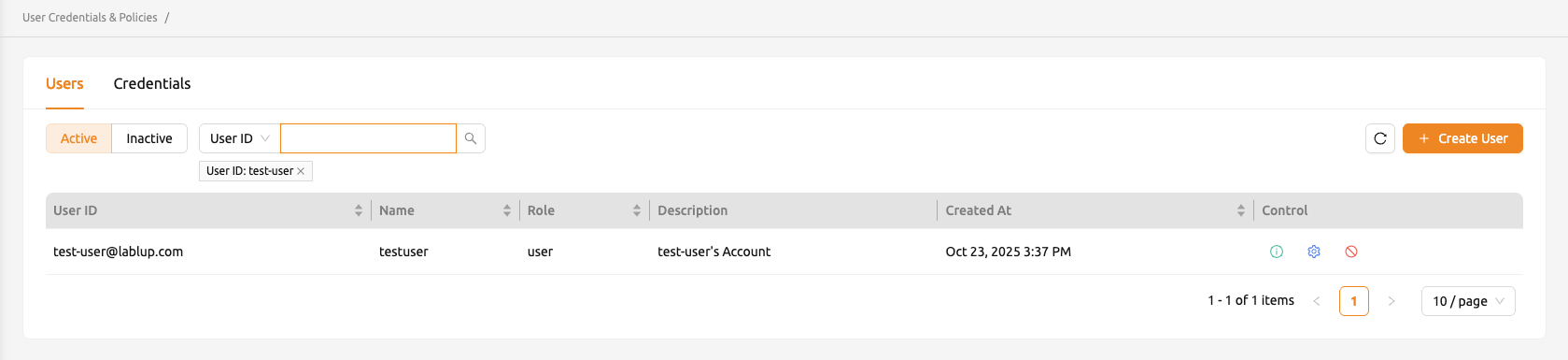
ユーザーが作成されたことを確認します。
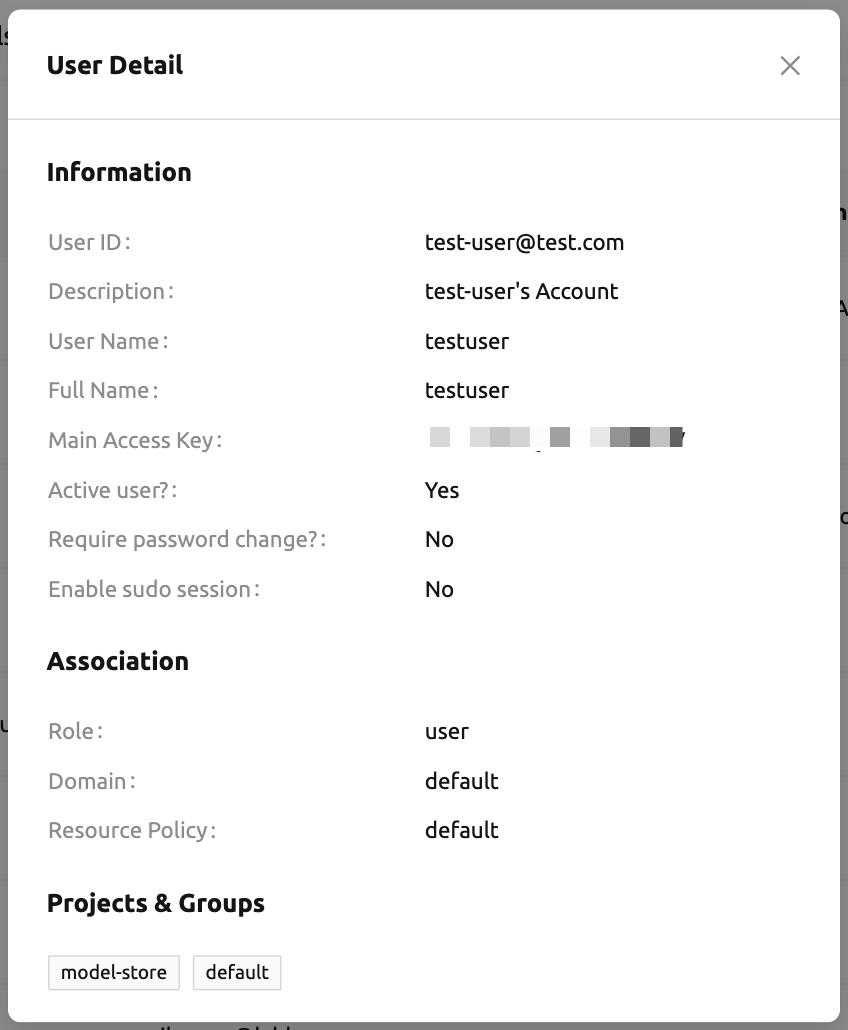
「コントロール」列の緑色のボタンをクリックすると、より詳細なユーザー情報を確認できます。ユーザーが所属するドメインやプロジェクトの情報も確認できます。
「コントロール」列の「設定」ボタンをクリックすると、既存のユーザー情報を更新できます。ユーザー名、パスワード、有効化状態などを変更できます。ユーザーID(メールアドレス)は変更できません。
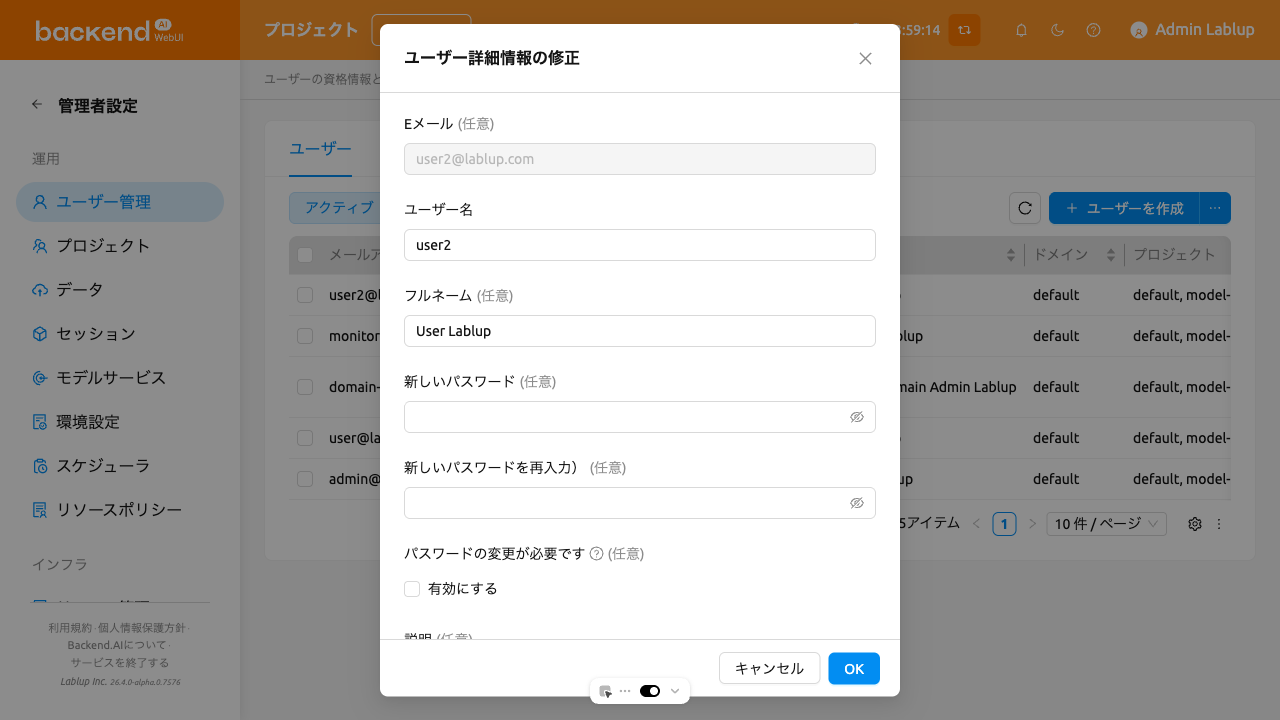
ユーザー作成/更新ダイアログには、以下のフィールドが含まれています。
Eメール: ユーザーのメールアドレスで、ログインIDとして使用されます。作成後は変更できません。
ユーザー名: ユーザーの一意の識別子です(最大64文字)。
フルネーム: ユーザーの表示名です(最大64文字)。
パスワード: 8文字以上で、アルファベット、特殊文字、数字をそれぞれ1つ以上含む必要があります。
説明: ユーザーに関するオプションの説明です(最大500文字)。
ユーザーステータス: ユーザーの状態を示します。Inactiveユーザーはログインできません。Before Verificationは、メール認証や管理者の承認など、アカウントを有効化するための追加手順が必要な状態を示します。Inactiveユーザーは別途Inactiveタブに表示されます。
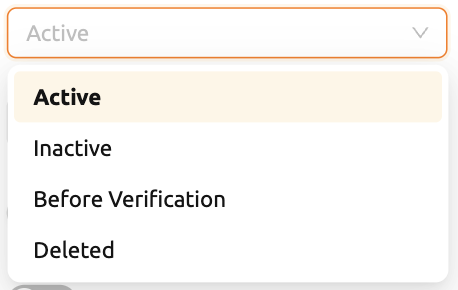
図 25.6 役割: ユーザーの役割(user、admin、superadmin)。現在のユーザーの権限によって選択可能なオプションが異なります。
ドメイン: ユーザーが所属するドメインです。ユーザーの作成時と更新時の両方で設定できます。
プロジェクト: ユーザーが所属するプロジェクトを1つ以上選択します。選択したドメインによって利用可能なプロジェクトが異なります。
パスワードの変更が必要: 管理者がユーザーを一括作成する際にランダムパスワードを選択した場合、このフィールドをONに設定してパスワード変更が必要であることを示せます。ユーザーにはパスワードの更新を促すトップバーが表示されますが、これは説明的なフラグであり、実際の使用には影響しません。
sudoセッションを有効にする: ユーザーがコンピュートセッションでsudoを使用できるようにします。ユーザーがroot権限を必要とするパッケージのインストールやコマンドの実行時に便利です。ただし、セキュリティ上の問題を引き起こす可能性があるため、すべてのユーザーに対してこのオプションを有効にすることは推奨されません。
2要素認証が有効: ユーザーが二要素認証を使用しているかどうかを示すフラグです。二要素認証を使用している場合、ユーザーはログイン時に追加でOTPコードの入力が必要です。管理者は他のユーザーの二要素認証のみを無効化できます。
リソースポリシー: Backend.AIバージョン24.09から、ユーザーが所属するユーザーリソースポリシーを選択できます。ユーザーリソースポリシーの詳細については、ユーザーリソースポリシーセクションを参照してください。
許可されたクライアントIP: このユーザーアカウントでシステムにアクセスできるIPアドレスを制限します。IPアドレスまたはCIDR表記で入力します(例:
10.20.30.40、10.20.30.0/24)。空の場合、すべてのIPからのアクセスが許可されます。コンテナUID: コンテナ内のプロセスに割り当てられる数値ユーザーIDです。ファイル権限の目的でコンテナが特定のUIDと一致する必要がある場合に便利です。
コンテナGID: コンテナ内のプロセスに割り当てられるデフォルトの数値グループIDです。
補助GID: コンテナプロセスに割り当てられる追加の数値グループIDです。複数のGIDをカンマで区切って入力します。
メインアクセスキー: (編集時のみ)ユーザーのキーペアの中からAPI認証に使用するメインアクセスキーを選択します。
ユーザー一括作成#
この機能は、Backend.AI Manager バージョン 26.2.0 以降でのみ利用できます。
複数のユーザーアカウントを一度に作成する必要がある場合、ユーザー一括作成機能を使用
できます。Manager 26.2.0 以降では、Users ページのユーザーを作成ボタンの横に
省略記号(...)ドロップダウンボタンが表示されます。このドロップダウンボタンを
クリックし、ユーザー一括作成を選択すると、一括作成ダイアログが開きます。
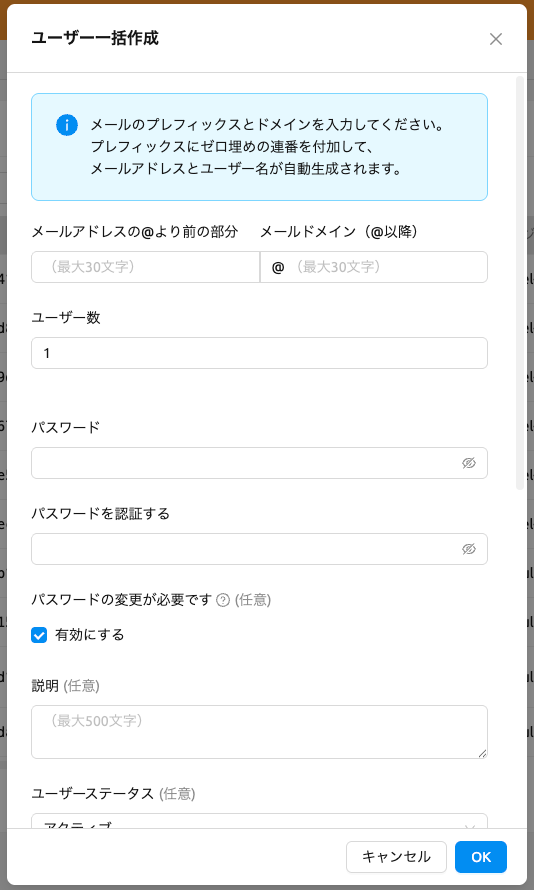
一括作成ダイアログには以下のフィールドがあります。ダイアログ上部の案内バナーに、 プレフィックスの後にゼロ埋めの連番が付加され、メールアドレスとユーザー名が自動生成 されるという説明が表示されます。
- メールアドレスの@より前の部分: 自動生成されるメールアドレスのプレフィックス部分 です。文字、数字、ドット、ハイフン、アンダースコアのみ使用可能です(最大30文字)。
- メールドメイン(@以降): 自動生成されるメールアドレスのドメイン部分です。
このフィールドには
@プレフィックスが自動的に表示されます(最大30文字)。 - ユーザー数: 作成するユーザーアカウントの数です(1~100)。このフィールドの下に、
生成されるメールアドレスのリアルタイムプレビューが表示されます。4人以下の場合は
すべてのメールが表示され、5人以上の場合は最初の2つ、省略記号、最後のメールが表示
されます(例:
student01@example.com, student02@example.com ... student10@example.com)。 - パスワード: 作成されるすべてのユーザーの共有初期パスワードです。単一ユーザー 作成と同じパスワードルールが適用されます(8文字以上、英字・特殊文字・数字を 各1つ以上含む)。
- パスワードの変更が必要です: 一括作成時はデフォルトでONに設定されます。 有効にすると、各ユーザーは初回ログイン時にパスワードの変更を求められます。
- ドメイン: 作成されたユーザーが所属するドメインです。
- ロール、ステータス、リソースポリシー、プロジェクトなどのその他の フィールドは、単一ユーザー作成と同じです。
ユーザー名とメールアドレスは、入力したプレフィックスとサフィックスに基づいて自動生成
されます。例えば、メールプレフィックスを student、メールサフィックスを
example.com、ユーザー数を 10 に設定すると、以下のアカウントが作成されます:
| ユーザー名 | メールアドレス |
|---|---|
student01 |
student01@example.com |
student02 |
student02@example.com |
| ... | ... |
student10 |
student10@example.com |
連番はユーザーの総数に基づいてゼロ埋めされます。例えば、3人の場合は
student1 から student3、10人の場合は student01 から student10、100人の場合は
student001 から student100 となります。
生成されたユーザー名やメールアドレスの一部が既に存在する場合、操作は部分的に成功する ことがあります。警告メッセージに、正常に作成されたユーザー数と失敗したユーザー数が 表示されます。
ユーザーアカウントの無効化#
ユーザーごとの使用統計を追跡し、メトリクスの保持および誤ってアカウントを失うことを 防ぐため、スーパー管理者であってもユーザーアカウントの削除は許可されていません。 代わりに、管理者はユーザーアカウントを無効化してログインを禁止できます。 コントロールパネルの削除アイコンをクリックしてください。確認を求めるポップオーバーが 表示され、「無効化」ボタンをクリックすることでユーザーを無効化できます。
ユーザーを再度有効化するには、Users - Inactiveタブに移動し、対象ユーザーのステータスを
Activeに変更してください。
ユーザーアカウントは複数のキーペアを持つことができ、どのキーペアを再度有効化すべきかを 判断することが難しいため、ユーザーの無効化または再有効化を行っても、ユーザーの 認証情報は変更されない点にご注意ください。
ユーザーのキーペア管理#
各ユーザーアカウントは通常、1つ以上のキーペアを持ちます。キーペアは、ユーザーがログインした後、 Backend.AIサーバーに対するAPI認証に使用されます。ログインにはユーザーのメールアドレスと パスワードによる認証が必要ですが、ユーザーがサーバーに送信するすべてのリクエストは、 キーペアに基づいて認証されます。
ユーザーは複数のキーペアを持つことができますが、キーペア管理の負担を軽減するため、現在は ユーザーのキーペアのうち1つだけを使用してリクエストを送信しています。また、新しい ユーザーを作成する際にキーペアは自動的に作成されるため、ほとんどの場合、手動でキーペアを 作成して割り当てる必要はありません。
キーペアは、Usersページの「Credentials」タブで一覧表示できます。アクティブなキーペアは すぐに表示され、非アクティブなキーペアを確認するには、下部の「Inactive」パネルを クリックしてください。
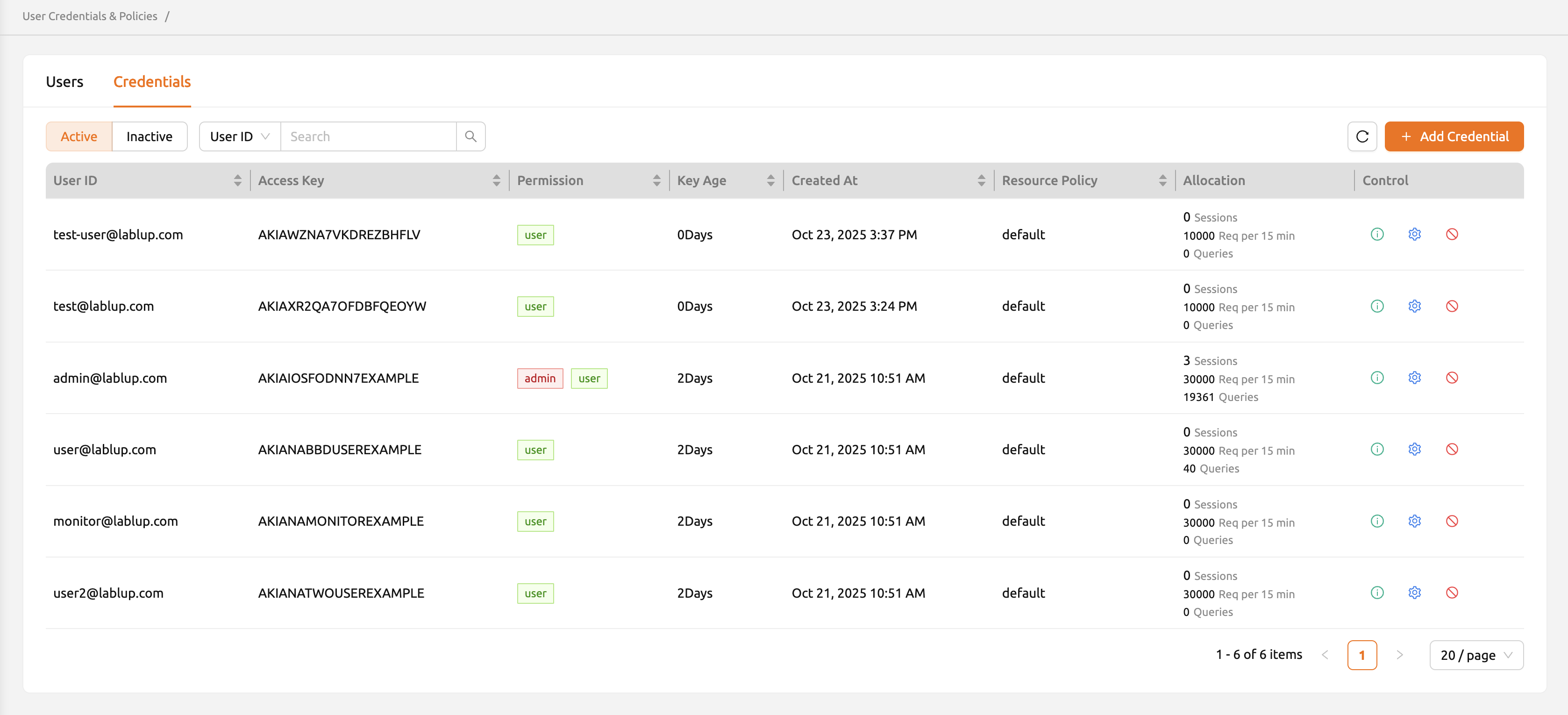
Usersタブと同様に、コントロールパネルのボタンを使用してキーペアの詳細を表示したり 更新したりできます。緑色の情報アイコンボタンをクリックすると、キーペアの詳細情報を 確認できます。必要に応じて、コピーボタンをクリックしてシークレットキーをコピーできます。
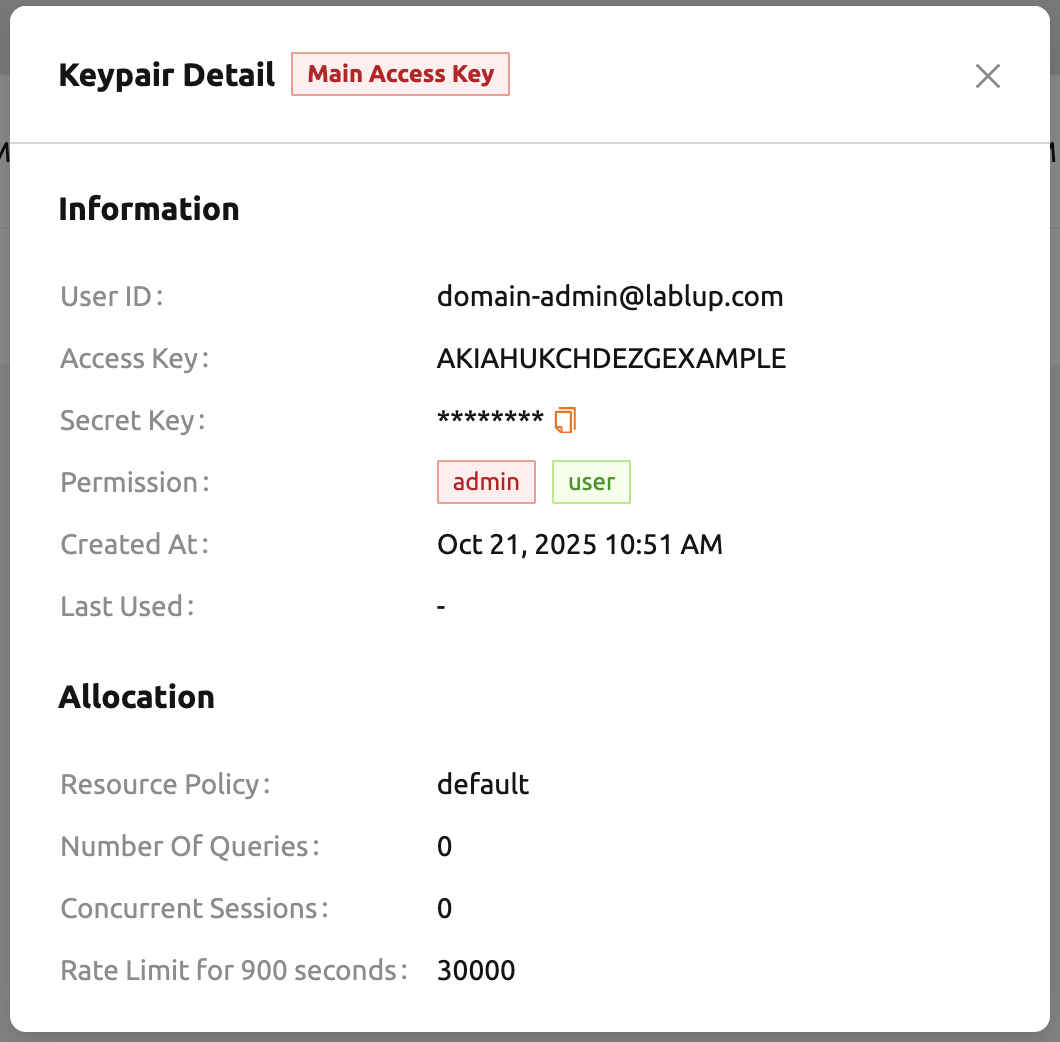
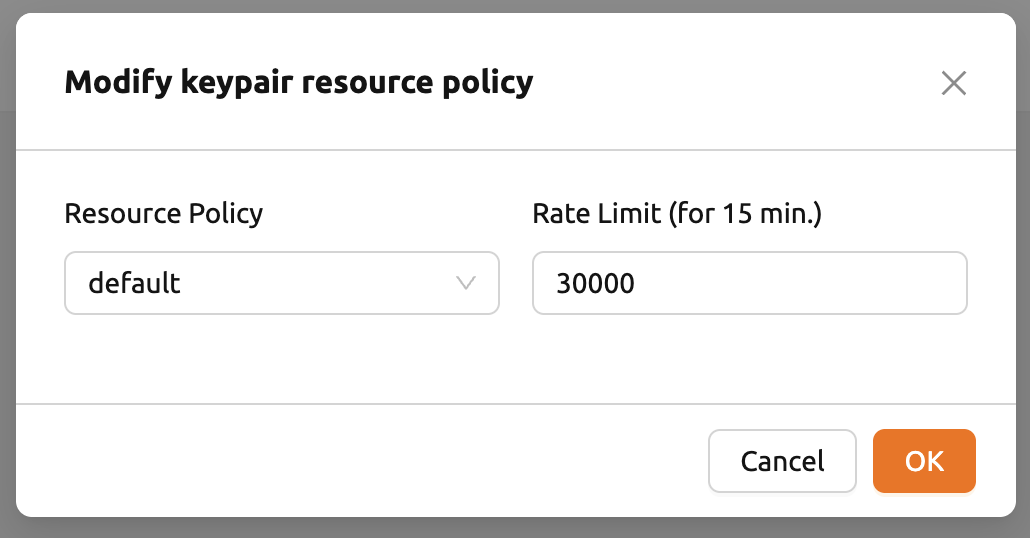
青色の「設定(歯車)」ボタンをクリックすると、キーペアのリソースポリシーおよびレート制限を 変更できます。「Rate Limit」の値が小さいと、ログインなどのAPI操作がブロックされる 可能性がある点にご注意ください。
「コントロール」列の赤色の「Deactivate」ボタンまたは黒色の「Activate」ボタンをクリックすると、 キーペアを無効化または再有効化することもできます。Userタブとは異なり、Inactiveタブでは キーペアを完全に削除できます。ただし、キーペアがユーザーのメインアクセスキーとして現在 使用されている場合は、完全に削除することはできません。
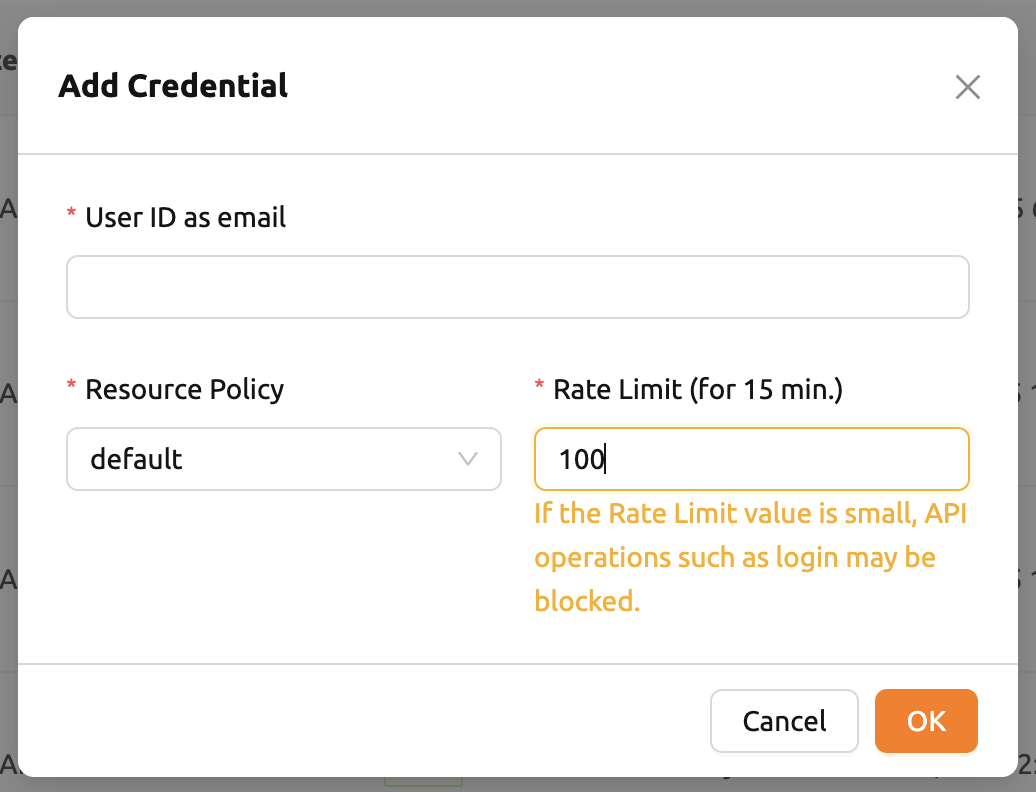
誤ってキーペアを削除してしまった場合は、右上の「+ ADD CREDENTIAL」ボタンをクリックして、 ユーザーのキーペアを再作成できます。
「Rate Limit」フィールドでは、15分以内にBackend.AIサーバーに送信できるリクエストの 最大数を指定します。例えば1000に設定した場合、キーペアが15分以内に1000を超えるAPI リクエストを送信すると、サーバーがエラーを返してリクエストを受け付けません。デフォルト値の 使用を推奨し、ユーザーの利用パターンに応じてAPIリクエストの頻度が高まった場合にのみ 値を増やすことを推奨します。
プロジェクトメンバーとプロジェクトストレージフォルダを共有する#
Backend.AIはユーザー独自のストレージフォルダに加えて、プロジェクト用のストレージフォルダを 提供します。プロジェクトストレージフォルダは、特定のユーザーではなく特定のプロジェクトに 属するフォルダであり、そのプロジェクトのすべてのユーザーがアクセスできます。
プロジェクトフォルダは管理者のみが作成できます。一般ユーザーは、管理者が作成した プロジェクトフォルダの内容にアクセスすることのみ可能です。システム設定によっては、 プロジェクトフォルダが許可されない場合があります。
まず、管理者アカウントでログインし、プロジェクトフォルダを作成します。Dataページに 移動してから、「Create Folder」をクリックしてフォルダ作成ダイアログを開きます。 フォルダ名を入力し、TypeをProjectに設定します。TypeがProjectに設定されると、ヘッダーの プロジェクトセレクタで選択されているプロジェクトに自動的に割り当てられます。 権限はRead-Onlyに設定されます。
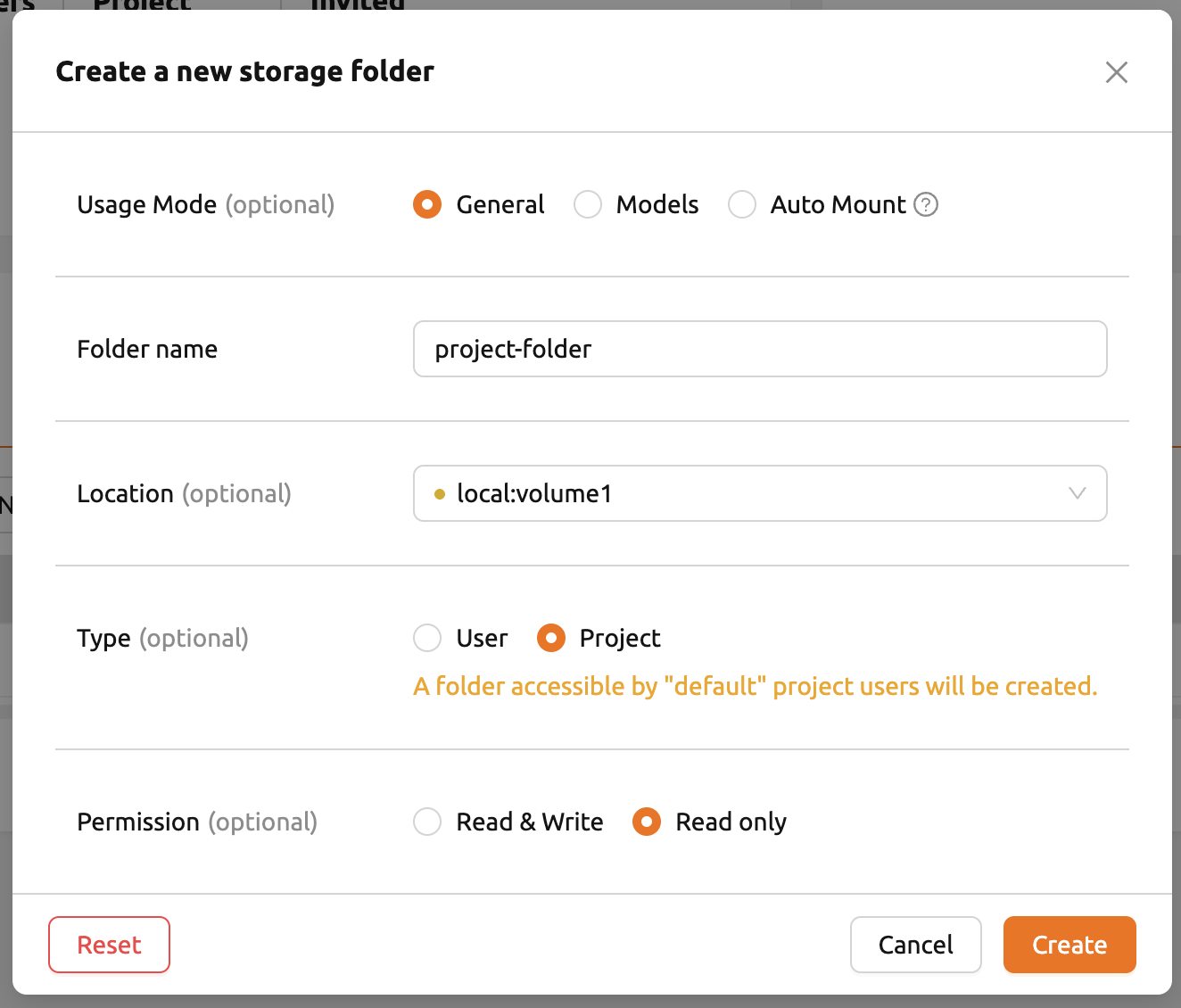
フォルダが作成されたことを確認した後、ユーザーBのアカウントでログインし、Data & Storageページに招待手続きなしで作成したばかりのプロジェクトフォルダが表示されることを 確認します。Permissionパネルに R(Read Only)が表示されていることも確認できます。
モデルカードの管理#
モデルストアのモデルカードは、管理者モデルストア管理 インターフェースを通じて作成・管理します。各モデルカードは、実際のモデルファイルが格納されたストレージフォルダー(vfolder)と紐づけられます。
モデルストアフォルダーのセットアップ#
Hugging FaceのGatedモデルを使用する場合は、ダウンロード前に該当モデルへのアクセス権限をリクエストする必要があります。詳細については、Gated models を参照してください。
まず、プロジェクトを model-store に設定します。
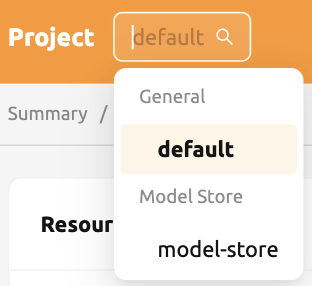
データページに移動し、フォルダ作成 ボタンをクリックします。フォルダを以下のように設定します:
- 使用方式: Model
- タイプ: Project
- 権限: Read-Write
フォルダを作成したら、モデルファイルをフォルダにダウンロードします。セッション作成時にモデルフォルダをマウントし、huggingface-cli などのツールを使用してモデルの重みをダウンロードできます。
モデルファイルは手動でフォルダにダウンロードする必要があります。Hugging Faceからのダウンロード方法については、Downloading models を参照してください。
フォルダとモデルファイルが準備できたら、管理者モデルストア管理 インターフェースでモデルカードを作成し、そのフォルダーと紐づけます。
モデル定義ファイル(高度な設定 — カスタムランタイム)#
Custom ランタイムバリアントを使用する場合、モデルフォルダーに model-definition.yaml ファイルをオプションで配置できます。このファイルは、サービング時に推論サーバーをどのように起動・運用するかを Backend.AI に伝えます — 起動コマンド、ヘルスチェック設定、モデルの重みのダウンロードなどの起動前アクションが含まれます。
vLLM、SGLang、NVIDIA NIM、Modular MAX などのランタイムバリアントでは、model-definition.yaml ファイルは不要です。これらのバリアントは、選択した設定に基づいてモデル構成を自動的に処理します。
以下は、Custom バリアントで vLLM サーバーを起動する model-definition.yaml の例です:
models:
- name: "Llama-3.1-8B-Instruct"
model_path: "/models/Llama-3.1-8B-Instruct"
service:
pre_start_actions:
- action: run_command
args:
command:
- huggingface-cli
- download
- --local-dir
- /models/Llama-3.1-8B-Instruct
- --token
- hf_****
- meta-llama/Llama-3.1-8B-Instruct
start_command:
- /usr/bin/python
- -m
- vllm.entrypoints.openai.api_server
- --model
- /models/Llama-3.1-8B-Instruct
- --served-model-name
- Llama-3.1-8B-Instruct
- --tensor-parallel-size
- "1"
- --host
- "0.0.0.0"
- --port
- "8000"
- --max-model-len
- "4096"
port: 8000
health_check:
path: /v1/models
max_retries: 500モデル定義ファイルの形式の詳細については、モデルサービスドキュメントの モデル定義ガイド を参照してください。
モデルストアでモデルカードの Deploy ボタンを有効にするには、紐づけられたフォルダーに service-definition.toml を含めてください。model-definition.yaml は Custom ランタイムバリアントを使用する場合にのみ追加で必要であり、vLLM、SGLang、NVIDIA NIM、Modular MAX などのプリセットランタイムバリアントでは不要です。サービス定義ファイルの詳細については、モデルサービスドキュメントの サービス定義ファイル セクションを参照してください。
管理者機能#
管理者サービングページ#
管理者およびスーパー管理者は、すべてのプロジェクトのエンドポイントを表示できる管理者サービングページにアクセスできます。このページには、標準のエンドポイント一覧列に加えてプロジェクト列が表示され、管理者がすべてのプロジェクトのサービスを管理できます。
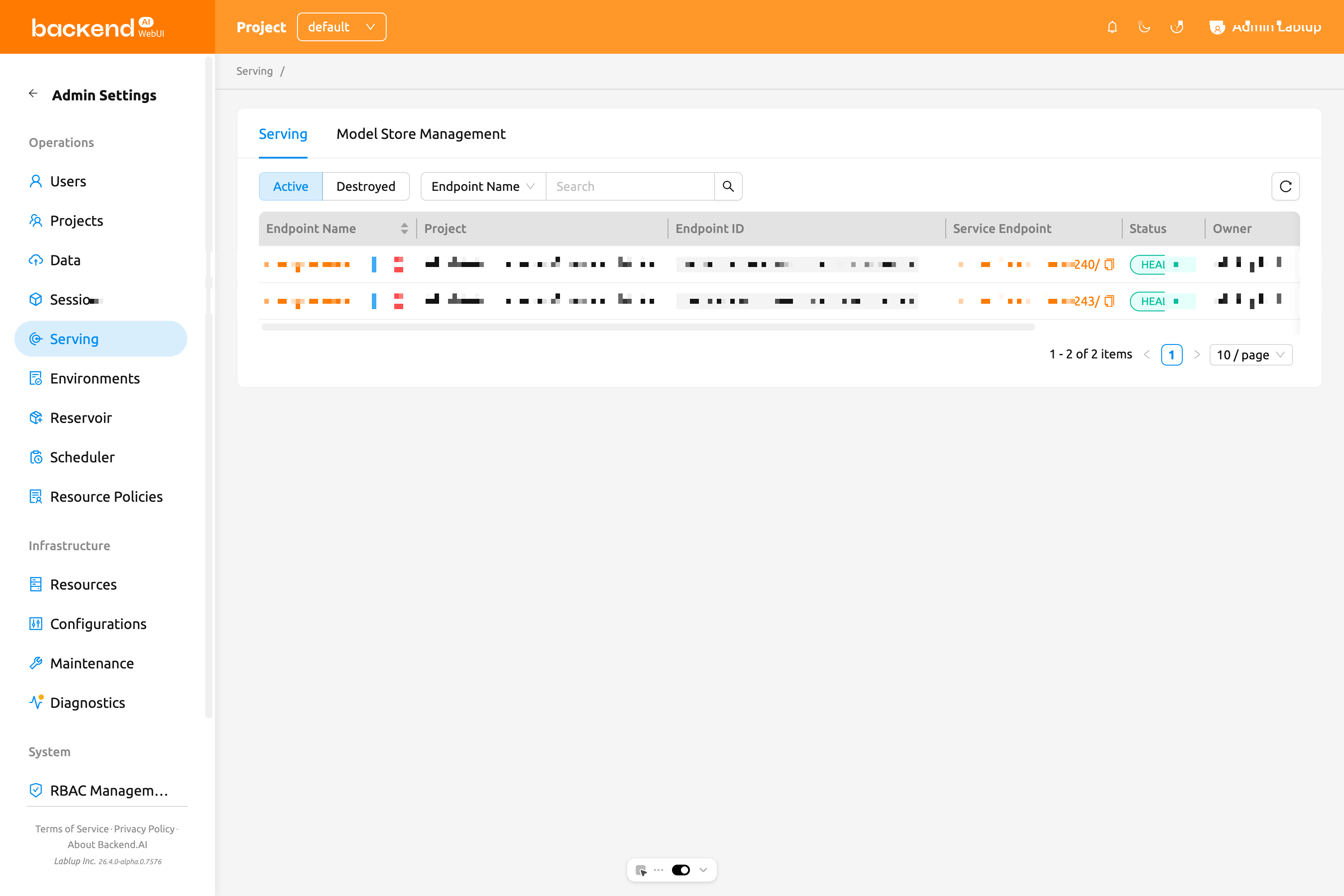
管理者サービングページには2つのタブがあります:
- Serving: すべてのプロジェクトのエンドポイント一覧を表示し、ユーザー向けサービングページと同じライフサイクルおよびプロパティフィルターを提供します。
- Model Store Management: スーパー管理者のみ利用可能です。以下のセクションを参照してください。
管理者モデルストア管理#
スーパー管理者は、管理者サービングページのモデルストア管理(Model Store Management)タブを通じてモデルカードを管理できます。
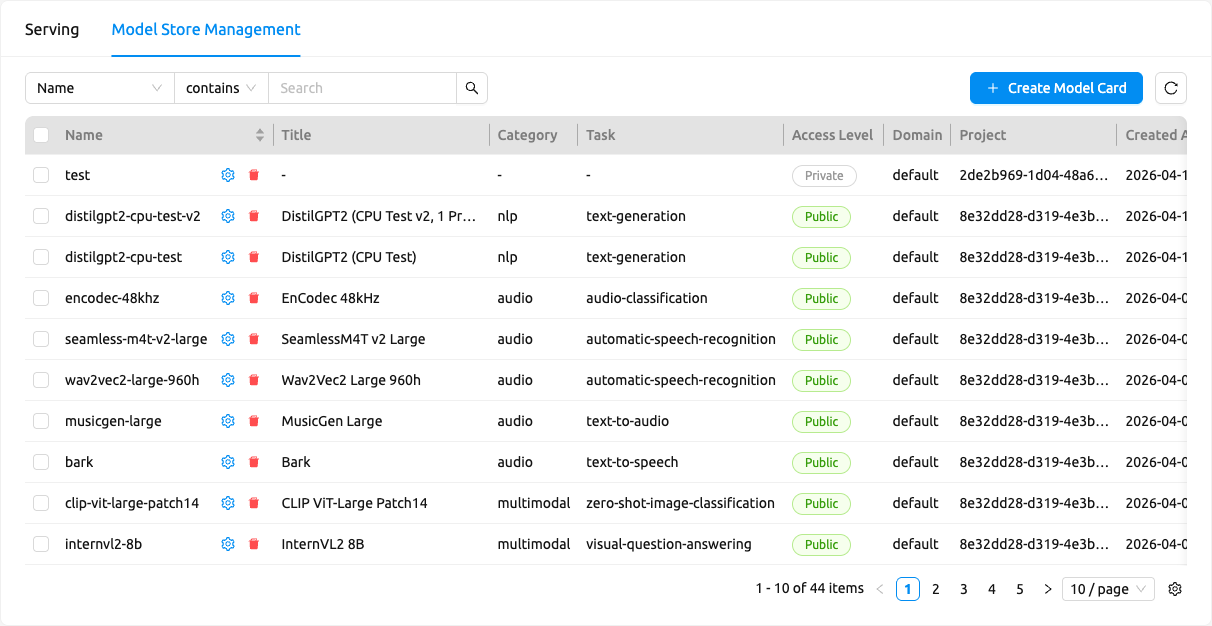
一覧には次の列が表示されます:
- 名前(Name): モデルカードの一意の識別子です。
- タイトル(Title): 人間が読みやすい表示名です。
- カテゴリ(Category): モデルカテゴリです(例:LLM)。
- タスク(Task): 推論タスクタイプです(例:text-generation)。
- アクセスレベル(Access Level): モデルカードが公開アクセス可能な場合は緑色の
Publicタグが、それ以外の場合はデフォルトのPrivateタグが表示されます。 - ドメイン(Domain): モデルカードを所有するドメインです。
- プロジェクト(Project): モデルカードを所有するプロジェクトです。
- 作成日時(Created At): モデルカードが作成された時間です。
上部のプロパティフィルターバーを使用して、名前で一覧をフィルタリングできます。各行の名前セルには、編集および削除のアクションアイコンが直接表示されます。
複数のモデルカードを一度に削除するには、チェックボックスで削除する行を選択し、選択件数の横にある赤色のゴミ箱ボタンをクリックします。カードが削除される前に確認ダイアログが表示されます。
モデルカードの作成#
モデルカードの作成(Create Model Card) ボタンをクリックして作成モーダルを開きます。以下のフィールドを入力します:
名前(Name)(必須): モデルカードの一意の識別子です。
タイトル(Title): 人間が読みやすい表示名です。
説明(Description): モデルの詳細な説明です。
著者(Author): モデルの作成者または組織です。
モデルバージョン(Model Version): モデルのバージョンです。
タスク(Task): 推論タスクタイプです(例:text-generation)。
カテゴリ(Category): モデルカテゴリです(例:LLM)。
フレームワーク(Framework): 使用される ML フレームワークです(例:PyTorch、TensorFlow)。
ラベル(Label): 分類およびフィルタリング用のタグです。
ライセンス(License): モデルが配布されるライセンスです。
アーキテクチャ(Architecture): モデルアーキテクチャです(例:Transformer)。
README: モデルのマークダウン README です。
ドメイン(Domain): モデルカードを関連付けるドメインです。
プロジェクト ID(Project ID)(必須): モデルカードを所有するプロジェクトです。
VFolder(必須): モデルファイルを含むストレージフォルダーです。
アクセスレベル(Access Level): ユーザー向けモデルストアでモデルカードを誰が閲覧できるかを制御します。
Internal: モデルカードを所有するドメインとプロジェクトの管理者にのみ表示されます。一般ユーザーは、自分のモデルストアで Internal のモデルカードを閲覧できません。Public: 該当プロジェクトにアクセス権を持つすべてのユーザーに表示されます。
モデルカードの編集#
モデルカード名の横にある編集アイコンをクリックして、既存のモデルカードを変更します。以前に入力したフィールドが入力された状態で編集モーダルが開きます。
モデルカードの削除#
モデルカード名の横にある削除アイコンをクリックして個別のモデルカードを削除するか、行のチェックボックスで複数のモデルカードを選択したうえで、選択件数の横にある赤色のゴミ箱ボタンをクリックして一括削除を実行できます。
リソースポリシー管理#
キーペアリソースポリシー#
Backend.AIでは、管理者は各キーペア、ユーザー、プロジェクトに対して利用可能な総リソースに 制限を設定できます。リソースポリシーを使用すると、許可される最大リソースやその他 コンピュートセッション関連の設定を定義できます。さらに、ユーザーや研究要件など、 さまざまなニーズに応じて複数のリソースポリシーを作成し、個別に適用することも可能です。
リソースポリシーページでは、管理者は登録されているすべてのリソースポリシーのリストを 表示できます。管理者は、キーペア、ユーザー、プロジェクトに対して設定されたリソース ポリシーをこのページで直接確認できます。まずキーペアのリソースポリシーを見ていきます。 下図では、合計3つのポリシー(gardener、student、default)があります。無限大の記号 (∞)は、該当するリソースに対して制限が適用されていないことを示します。
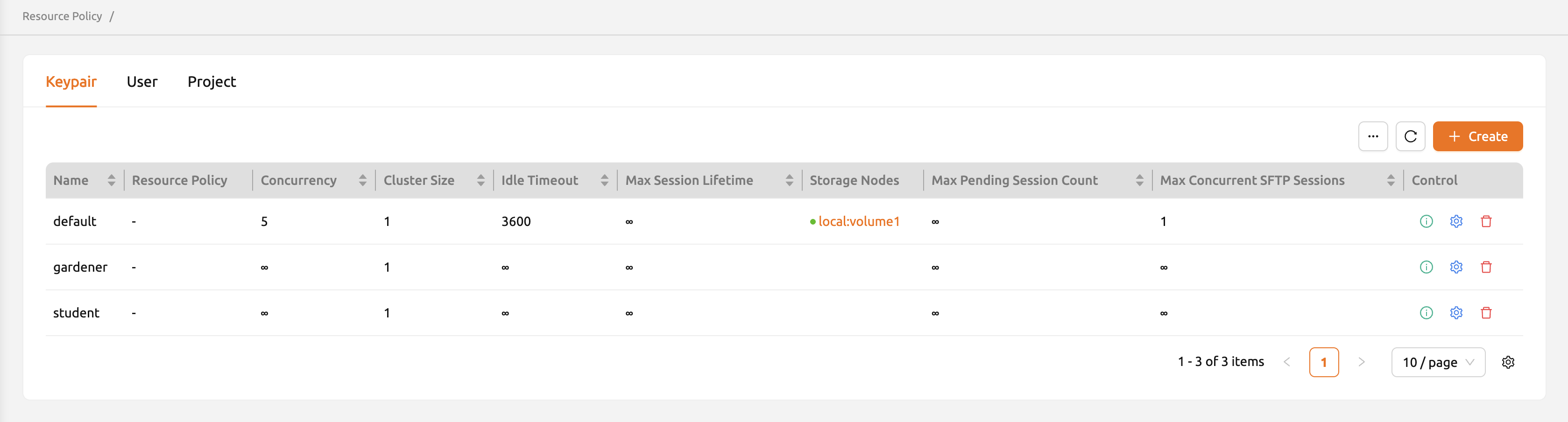
本ガイドで使用しているユーザーアカウントは、現在defaultリソースポリシーに割り当てられて います。これはUsersページのCredentialsタブで確認できます。また、Resource Policies パネルですべてのリソースポリシーがdefaultに設定されていることも確認できます。
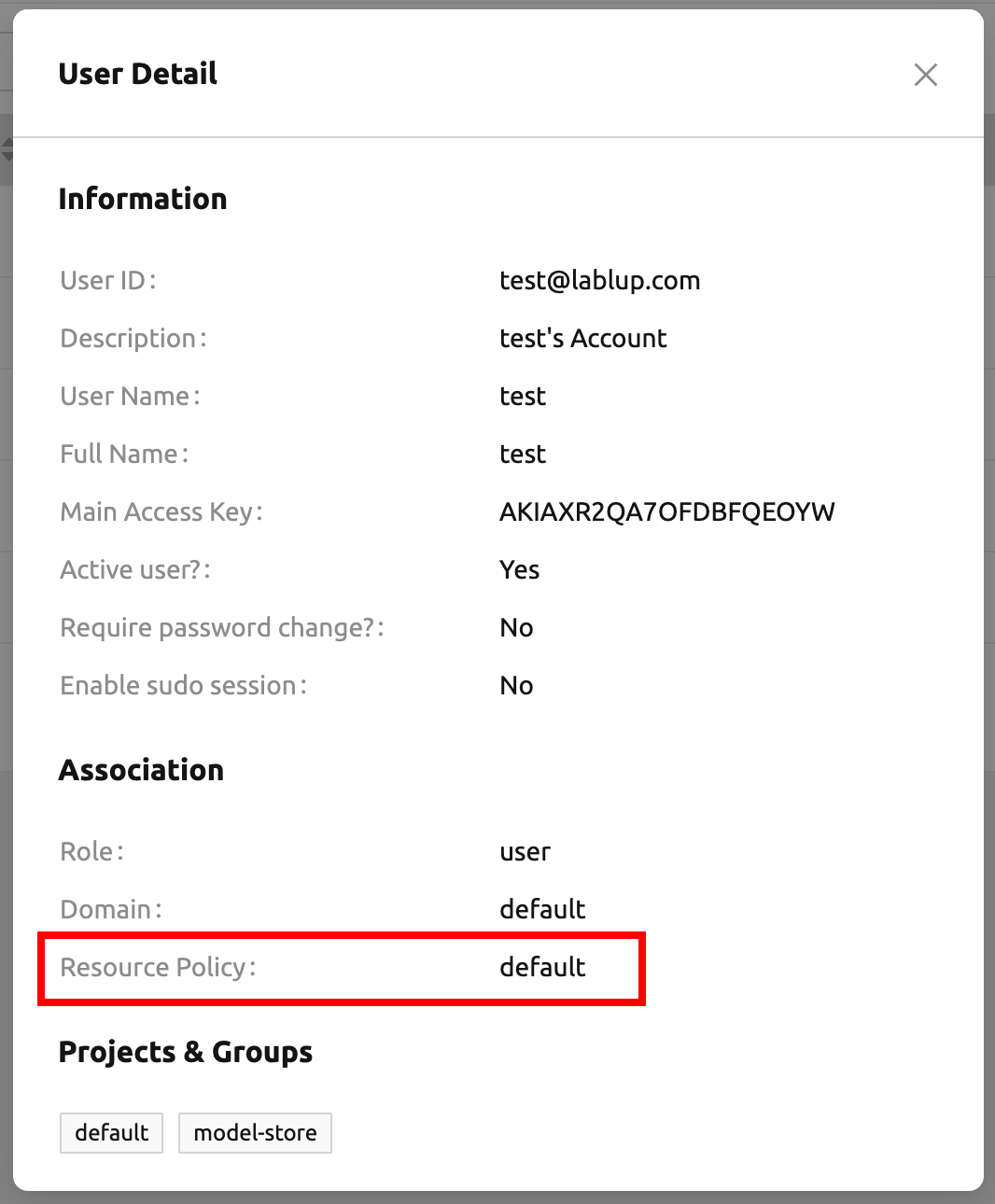
リソースポリシーを変更するには、defaultポリシーグループの「コントロール」列にある 「設定(歯車)」をクリックします。「Update Resource Policy」ダイアログでは、リソース ポリシーを一覧で識別するための主キーとして機能する「Policy Name」を除き、すべての オプションが編集可能です。CPU、RAM、fGPUの下部にあるUnlimitedチェックボックスをオフにし、 リソース制限を希望する値に設定します。割り当てるリソースが総ハードウェア容量を 超えないようにしてください。ここでは、CPU、RAM、fGPUをそれぞれ2、4、1に設定します。 「OK」ボタンをクリックして、更新したリソースポリシーを適用します。
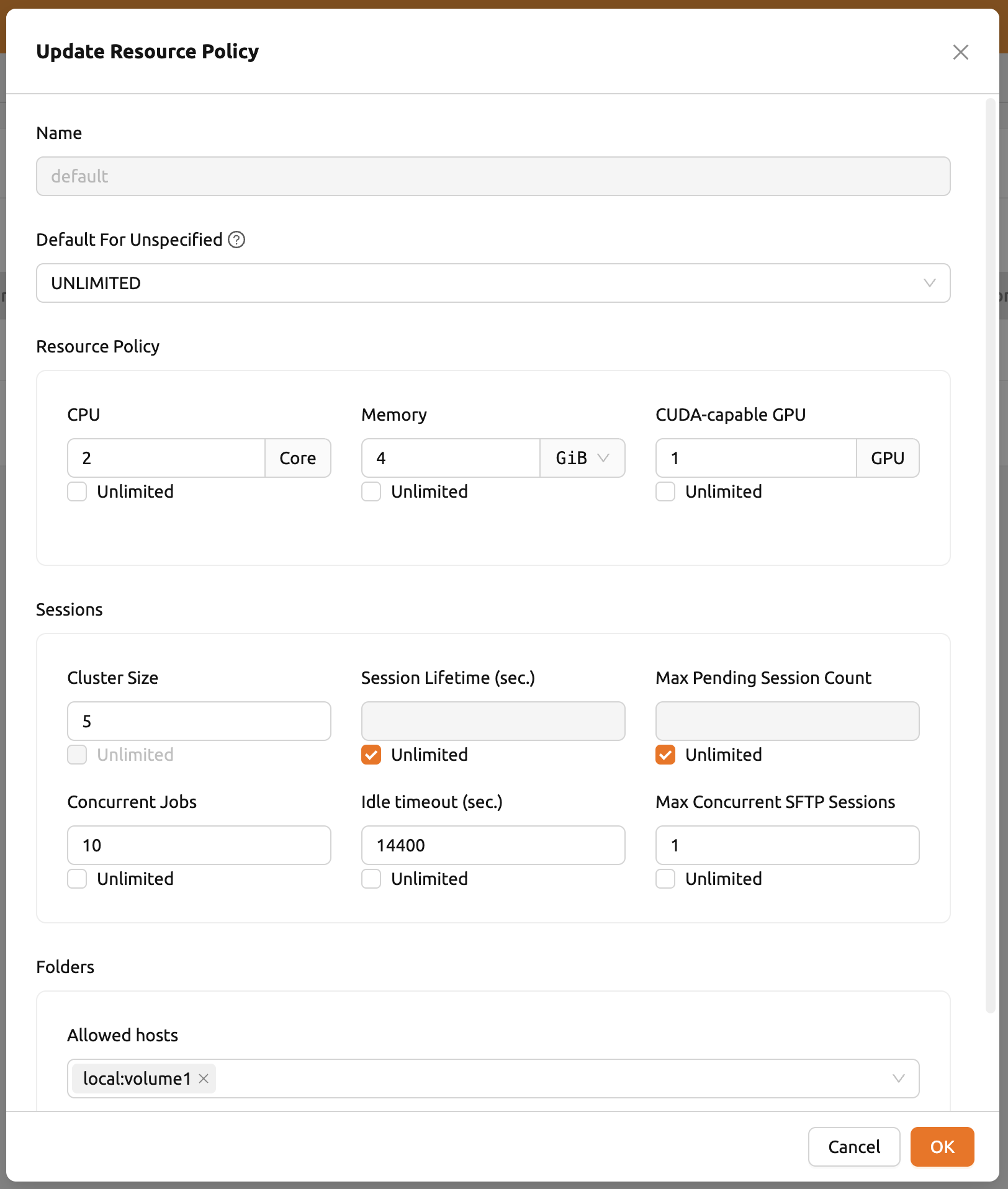
リソースポリシーダイアログの各オプションの詳細については、以下の説明を参照してください。
リソースポリシー
- CPU: 最大CPUコア数を指定します。(最大値: 512)
- メモリ: 最大メモリ量をGB単位で指定します。メモリはGPUメモリの最大値の2倍に設定 することを推奨します。(最大値: 1024)
- CUDA対応GPU: 物理GPUの最大数を指定します。サーバーでフラクショナルGPUが有効化 されている場合、この設定は効果がありません。(最大値: 64)
- CUDA対応GPU(フラクショナル): フラクショナルGPU(fGPU)は、GPUを効率的に使用する ために、1つのGPUを複数のパーティションに分割するものです。必要なfGPUの最小量は イメージごとに異なる点に注意してください。サーバーでフラクショナルGPUが有効化 されていない場合、この設定は効果がありません。(最大値: 256)
セッション
- クラスターサイズ: セッション作成時に構成できるマルチコンテナまたはマルチノードの 最大数を設定します。
- セッション寿命(秒):
PENDINGおよびRUNNINGステータスを含む、アクティブ状態 での予約からのコンピュートセッションの最大寿命を制限します。この時間を過ぎると、 セッションが完全に利用されている場合でも強制終了されます。セッションが無期限に 実行されるのを防ぐのに役立ちます。 - 最大ペンディングセッション数: 同時に
PENDINGステータスになることができる コンピュートセッションの最大数です。 - 同時実行ジョブ: キーペアごとの同時実行コンピュートセッションの最大数です。 例えば、この値を3に設定すると、このリソースポリシーに紐づけられたユーザーは、 同時に3つを超えるコンピュートセッションを作成できません。(最大値: 100)
- アイドルタイムアウト(秒): ユーザーがセッションを放置できる期間を設定します。 アイドルタイムアウトの間、コンピュートセッションに一切のアクティビティがない場合、 セッションは自動的にガベージコレクションされ破棄されます。「アイドル」の基準は さまざまで、管理者によって設定されます。(最大値: 15552000(約180日))
- 最大同時SFTPセッション数: 同時に実行できるSFTPセッションの最大数です。
フォルダ
- 許可ホスト: Backend.AIは複数のNFSマウントポイントをサポートします。このフィールドは それらへのアクセスを制限します。"data-1"という名前のNFSがBackend.AIにマウント されていても、リソースポリシーで許可されていなければユーザーはアクセスできません。
- (23.09.4以降は非推奨)最大数: 作成または招待できるストレージフォルダの最大数です。 (最大値: 100)
キーペアリソースポリシーリストで、defaultポリシーの「Resources」の値が更新されたことを 確認します。
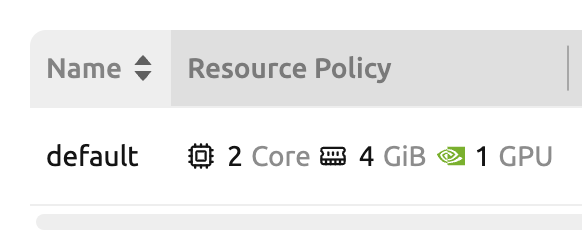
「+ 作成」ボタンをクリックして新しいリソースポリシーを作成できます。各設定値は上記の 説明と同じです。
リソースポリシーを作成してキーペアに関連付けるには、UsersページのCredentialsタブに 移動し、対象キーペアのコントロール列にある歯車ボタンをクリックして、「Select Policy」 フィールドをクリックして選択します。
「コントロール」列のゴミ箱アイコンをクリックして、各リソースキーペアを削除することも できます。アイコンをクリックすると、確認ポップアップが表示されます。「Delete」ボタンを クリックすると削除されます。
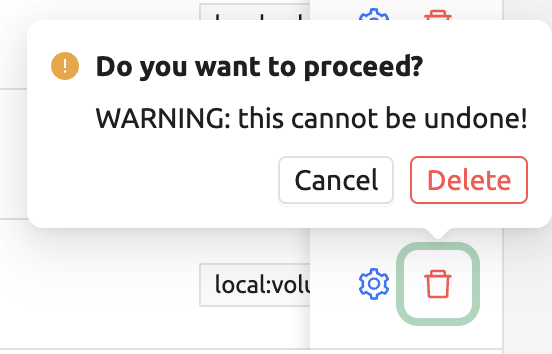
削除予定のリソースポリシーに従うユーザー(非アクティブなユーザーを含む)が存在する場合、 削除が行えない場合があります。リソースポリシーを削除する前に、そのリソースポリシーに 紐づくユーザーが残っていないことを確認してください。
特定のカラムを表示または非表示にしたい場合は、テーブルの右下にある「設定(歯車)」を クリックします。表示したいカラムを選択するダイアログが表示されます。
ユーザーリソースポリシー#
バージョン24.03以降、Backend.AIはユーザーリソースポリシーの管理をサポートしています。 各ユーザーは複数のキーペアを持つことができますが、ユーザーリソースポリシーは1つしか 持つことができません。ユーザーリソースポリシーページでは、「最大フォルダ数」や 「最大フォルダサイズ」などフォルダ関連のさまざまな設定、および「モデルセッションあたりの 最大セッション数」や「最大カスタマイズイメージ数」などの個別のリソース制限を設定できます。
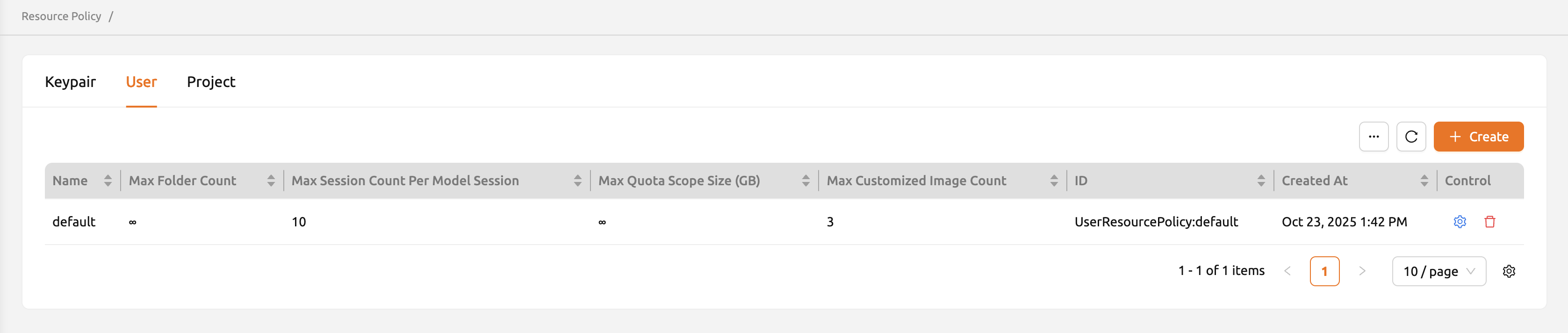
新しいユーザーリソースポリシーを作成するには、「Create」ボタンをクリックします。
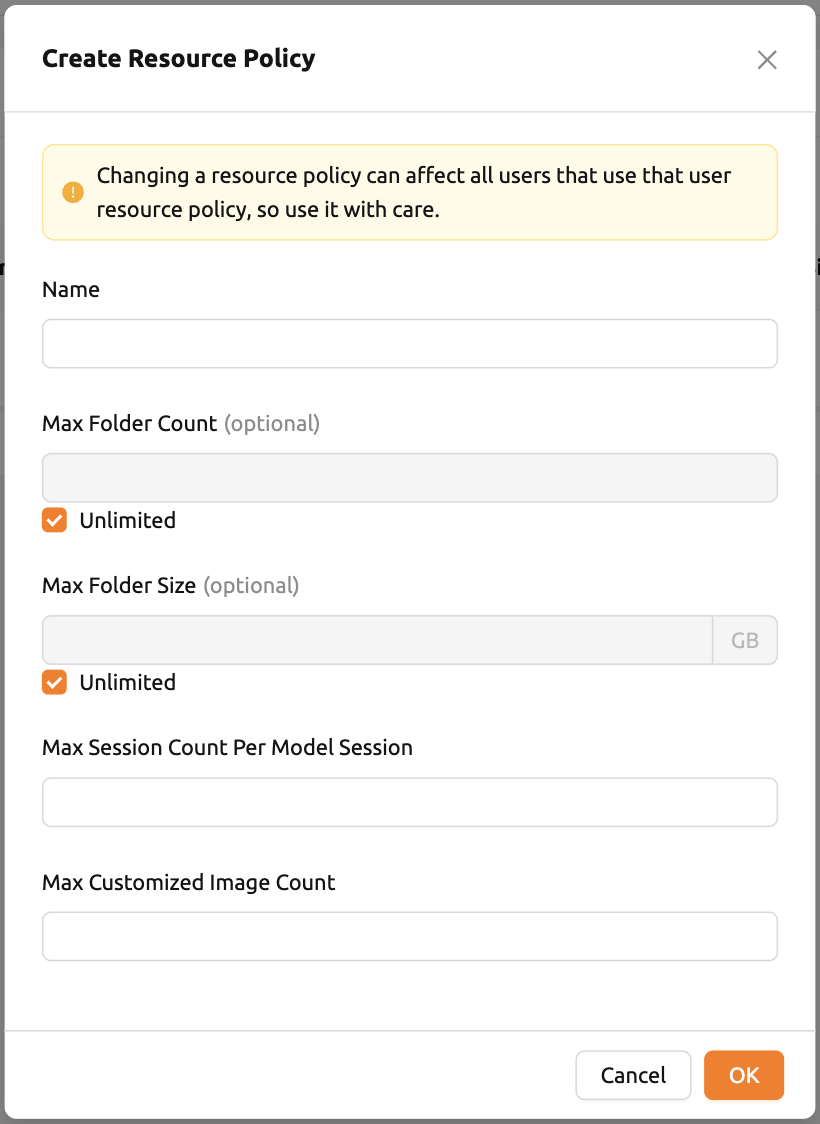
- 名前: ユーザーリソースポリシーの名前です。
- 最大フォルダ数: ユーザーが作成できるフォルダの最大数です。ユーザーのフォルダ数が この値を超えると、ユーザーは新しいフォルダを作成できません。Unlimitedに設定すると 「∞」と表示されます。
- 最大フォルダサイズ: ユーザーのストレージ容量の上限です。ユーザーのストレージ容量が この値を超えると、ユーザーは新しいデータフォルダを作成できません。Unlimitedに設定 すると「∞」と表示されます。
- モデルセッションあたりの最大セッション数: ユーザーが作成したモデルサービスごとに 利用可能なセッションの最大数です。この値を増やすとセッションスケジューラに高い負荷が かかり、システムダウンタイムを引き起こす可能性があるため、この設定を調整する際は ご注意ください。
- 最大カスタマイズイメージ数: ユーザーが作成できるカスタマイズイメージの最大数です。 ユーザーのカスタマイズイメージ数がこの値を超えると、ユーザーは新しいカスタマイズ イメージを作成できません。カスタマイズイメージの詳細については、My Environments セクションを参照してください。
更新するには、「コントロール」列の「設定(歯車)」ボタンをクリックします。削除するには、 ゴミ箱ボタンをクリックします。
リソースポリシーを変更すると、そのポリシーを使用するすべてのユーザーに影響する可能性が あるため、注意して使用してください。
キーペアリソースポリシーと同様に、テーブルの右下にある「設定(歯車)」ボタンをクリック することで、ユーザーが希望するカラムのみを選択して表示できます。
プロジェクトリソースポリシー#
バージョン24.03から、Backend.AIはプロジェクトリソースポリシーの管理をサポートしています。プロジェクトリソースポリシーは、プロジェクトのストレージ容量(クォータ)やフォルダ関連の制限を管理します。
「リソースポリシー」ページの「プロジェクト」タブをクリックすると、プロジェクトリソースポリシーのリストが表示されます。
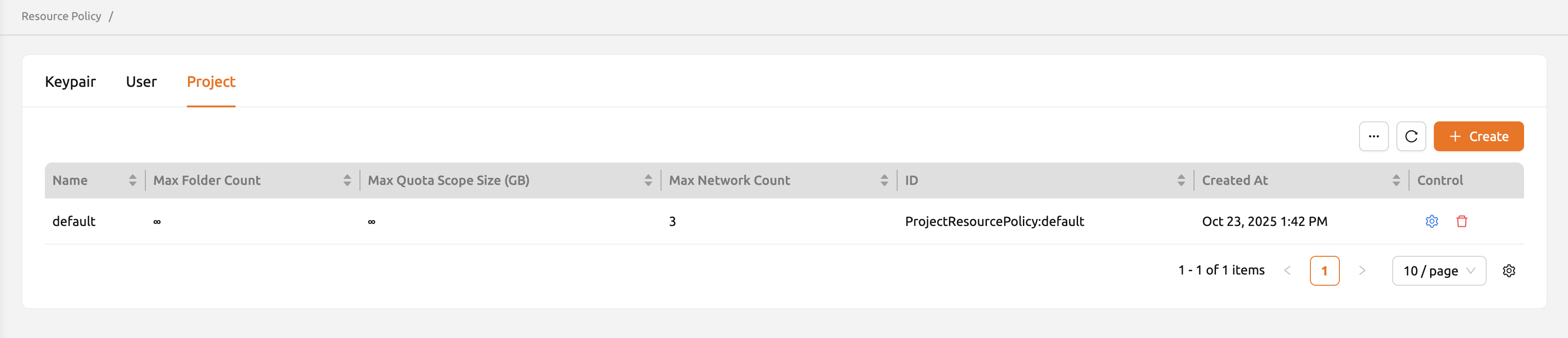
新しいプロジェクトリソースポリシーを作成するには、テーブルの右上にある「+ 作成」ボタンをクリックします。
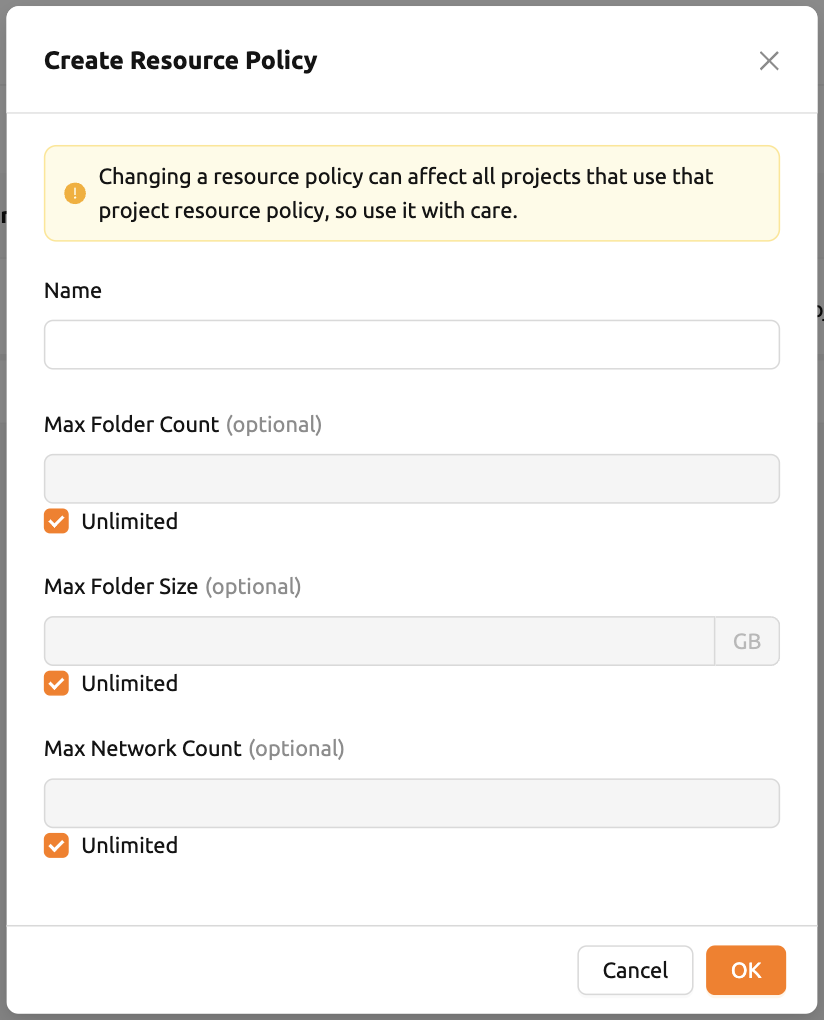
- 名前: プロジェクトリソースポリシーの名前。
- 最大フォルダ数: 管理者が作成できるプロジェクトフォルダの最大数。プロジェクトフォルダ数がこの値を超えると、管理者は新しいプロジェクトフォルダを作成できません。Unlimitedに設定すると「∞」と表示されます。
- 最大フォルダサイズ: プロジェクトのストレージ容量の上限。プロジェクトのストレージ容量がこの値を超えると、管理者は新しいプロジェクトフォルダを作成できません。Unlimitedに設定すると「∞」と表示されます。
- 最大ネットワーク数: Backend.AIバージョン24.12以降、プロジェクトに作成できるネットワークの最大数。Unlimitedに設定すると「∞」と表示されます。
各フィールドの意味はユーザーリソースポリシーと類似しています。違いは、プロジェクトリソースポリシーがプロジェクトフォルダに適用され、ユーザーリソースポリシーがユーザーフォルダに適用される点です。
変更するには、「コントロール」列の「設定」ボタンをクリックします。リソースポリシー名は編集できません。削除はゴミ箱アイコンボタンをクリックして行えます。
リソースポリシーの変更はそのポリシーを使用するすべてのユーザーに影響を与える可能性があるため、慎重に使用してください。
テーブルの右下にある「設定」ボタンをクリックして、表示するカラムのみを選択できます。
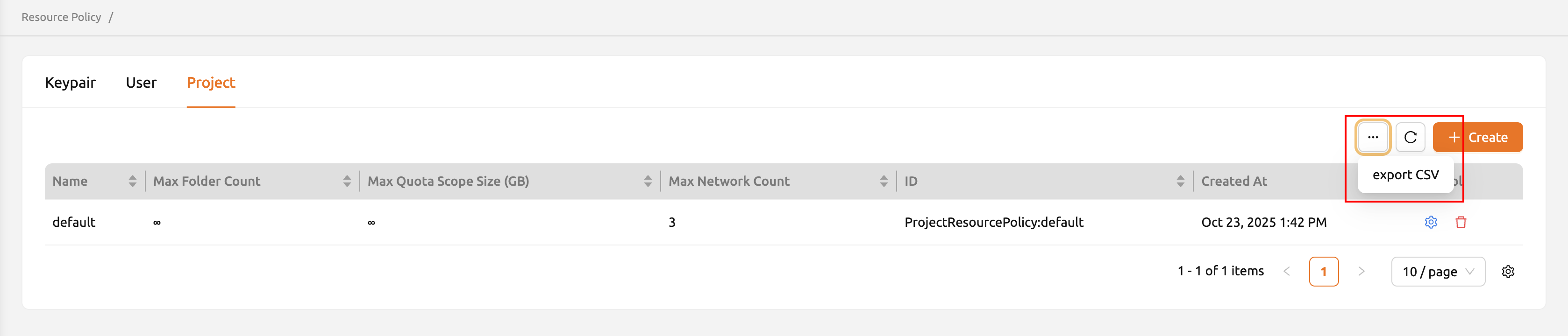
現在のリソースポリシーをファイルとして保存するには、各タブ右上の「もっと見る」ボタンをクリックし、「CSVをエクスポート」メニューを選択します。
ペンディングセッションの統合ビュー#
Backend.AIバージョン25.13.0以降、管理者メニューでペンディングセッションの統合ビューが利用可能です。 Admin Sessionページでは、選択したリソースグループ内のすべてのペンディングセッションを 一覧で確認できます。ステータスの横に表示されるインデックス番号は、十分なリソースが 確保された際にセッションが作成されるキューの位置を示しています。
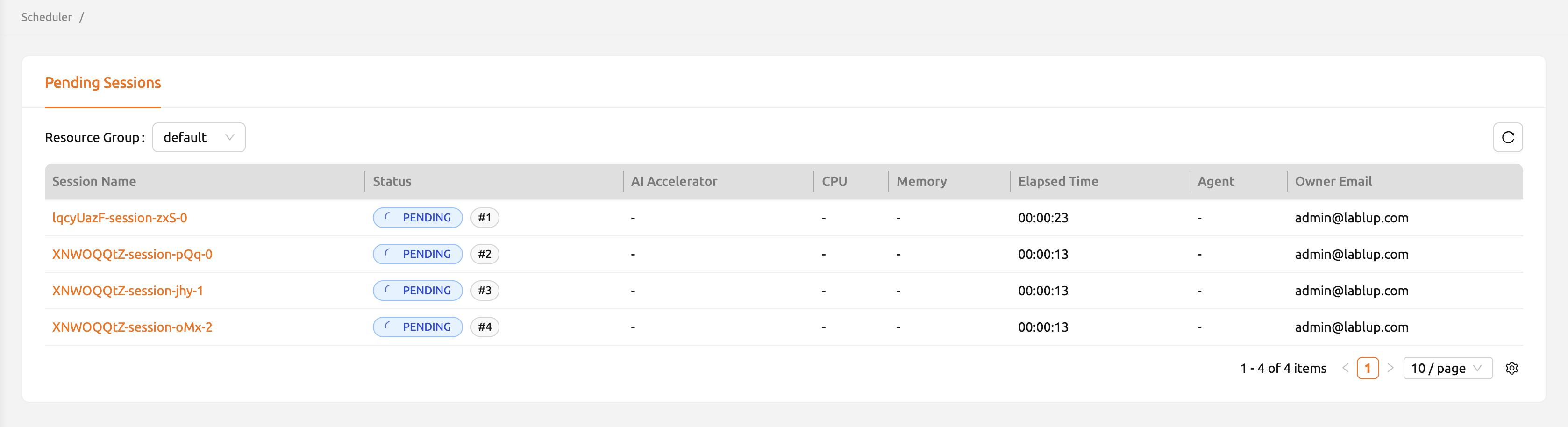
セッションページと同様に、セッション名をクリックすると、セッションの詳細情報を 表示するドロワーが開きます。
フェアシェアスケジューラ#
Backend.AIコアバージョン26.2.0以降で、フェアシェアスケジューラページがAdministration メニューから利用可能です。この機能により、管理者はリソースグループ、ドメイン、 プロジェクト、ユーザーの階層構造に基づいてフェアシェアスケジューリングの重みを 管理できます。
フェアシェアスケジューリングは、過去の使用パターンに基づいてコンピューティングリソースを 配分し、ユーザー間でリソースが公平に分配されるようにします。過去にリソースの使用が 少なかったユーザーはスケジューリング優先度が高くなり、多く使用したユーザーは優先度が 低くなります。管理者は階層構造の各レベルで重みを調整することで、この動作を 細かく制御できます。
フェアシェアスケジューラは、リソースグループのスケジューラタイプがFAIR_SHAREに
設定されている場合にのみ使用できます。リソースグループのスケジューラタイプの設定に
ついては、リソースグループの管理セクションを参照してください。
この機能にアクセスするには、サイドバーのAdministrationセクションでSchedulerメニュー項目を クリックします。ページにはフェアシェア設定タブと4段階のドリルダウンインターフェースが 表示されます。
ページは以下の4つの階層的なステップで構成されています:
- リソースグループ: 各リソースグループのフェアシェアの主要パラメータを設定します
- ドメイン: リソースグループ内のドメインごとに重みを設定します
- プロジェクト: ドメイン内のプロジェクトごとに重みを設定します
- ユーザー: プロジェクト内の個々のユーザーに重みを設定します
ページ上部のステップインジケーターバーは、階層構造での現在の位置を表示します。 完了したステップには選択した項目の名前が表示されます。完了したステップをクリックすると そのレベルに戻ることができます。

選択したリソースグループのスケジューラタイプがFAIR_SHAREに設定されていない場合、
そのリソースグループでフェアシェアスケジューラが有効になっていないことを示す警告
アラートが表示されます。

各ステップで以下の共通機能が利用可能です:
- フィルタリング: プロパティベースの検索フィルタを使用して、名前で結果を絞り込めます。ユーザーステップでは、メールアドレスとアクティブ状態による追加フィルタが利用できます。
- ソート: カラムヘッダーをクリックして、そのカラムでテーブルをソートできます。
- ページネーション: ページサイズを設定して結果をナビゲートできます。
- 自動リフレッシュ: データは7秒ごとに自動更新されます。手動リフレッシュボタンも利用可能です。
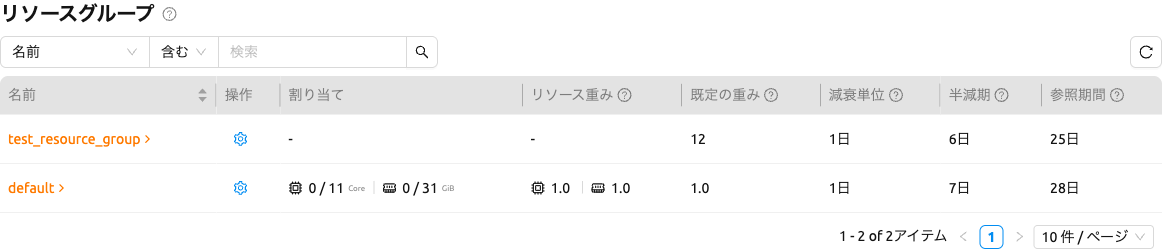
リソースグループ#
リソースグループステップでは、すべてのリソースグループとそのフェアシェア設定がテーブルで 表示されます。
テーブルには以下のカラムが含まれます:
- 名前: リソースグループ名です。名前をクリックすると、そのリソースグループのドメインレベル設定にドリルダウンします。
- 制御: リソースグループのフェアシェア設定モーダルを開く設定(歯車)ボタンです。
- 割り当て: リソースグループに割り当てられた各リソースタイプの使用量/容量を表示します(例:CPU、Memory、CUDA GPU)。
- リソース重み: リソースタイプごとの重みです。デフォルトの重みを使用している場合は「デフォルト」と表示されます。
- 既定の重み: 重みが指定されていないドメイン、プロジェクト、ユーザーに適用されるデフォルト値です。
- 減衰単位: 使用量を集計する期間(日単位)です。
- 半減期: 使用量の反映率が半分になる期間(日単位)です。
- 参照期間: Fair Share計算に反映される利用履歴の範囲(日単位)です。
リソースグループのフェアシェア設定#
リソースグループの制御カラムにある設定(歯車)ボタンをクリックすると、フェアシェア設定 モーダルが開きます。
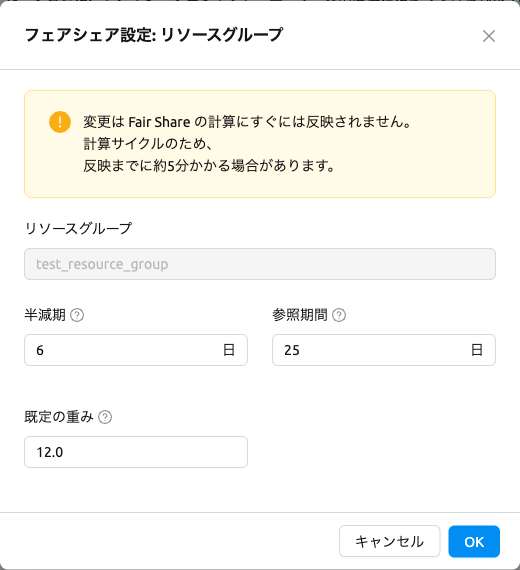
変更はFair Shareの計算にすぐには反映されません。計算サイクルのため、反映までに 約5分かかる場合があります。
モーダルには以下のフィールドが含まれます:
- リソースグループ: リソースグループ名を表示する読み取り専用フィールドです。
- 半減期: 使用量の反映率が半分になる期間で、日数で指定します(最小1)。例えば7日に設定すると、7日前の使用量は50%、14日前の使用量は25%として計算されます。減衰単位の倍数に設定することを推奨します。
- 参照期間: Fair Share計算に反映される利用履歴の範囲で、日数で指定します(最小1)。これより前の利用は計算から除外されます。半減期の倍数に設定することを推奨します。
- 既定の重み: 重みが指定されていないドメイン、プロジェクト、ユーザーに適用されるデフォルト値です(最小1、ステップ0.1)。
- リソース重み: リソースタイプごとの重み(例:CPU、Memory、GPU)で、それぞれ最小値1、ステップ0.1です。このセクションはリソースグループにリソース重みが存在する場合にのみ表示されます。
ドメイン#
リソースグループを選択すると、ドメインステップでそのリソースグループ内のドメインの フェアシェア重みと使用量がテーブルで表示されます。

テーブルには以下のカラムが含まれます:
- 名前: ドメイン名です。名前をクリックすると、そのドメインのプロジェクトレベル設定にドリルダウンします。
- 制御: 重み設定モーダルを開く設定(歯車)ボタンです。
- 重み: 現在の重み値です。デフォルトの重みを使用している場合は「デフォルト」と表示されます。
- フェアシェア係数: フェアシェアスケジューラによって算出されたスケジューリング優先度です。値が大きいほど優先度が高くなります。
- リソース割り当て: リソースタイプごとの1日あたりの平均減衰リソース使用量です(CPU、Memory、GPU / Day)。
- 更新日時: 最終更新のタイムスタンプです。
- 作成日時: 作成のタイムスタンプです。
テーブル左側のチェックボックスを使用して複数の行を選択できます。行が選択されると、 2つの追加ボタンが表示されます:
- 利用グラフ(チャートアイコン):選択した項目の利用履歴モーダルを開きます。
- 一括編集(歯車アイコン):選択したすべての項目の重みを一括で編集するモーダルを開きます。
プロジェクト#
ドメインを選択すると、プロジェクトステップでドメインステップと同じカラム構造の プロジェクトテーブルが表示されます。プロジェクト名をクリックするとユーザーステップに ドリルダウンします。
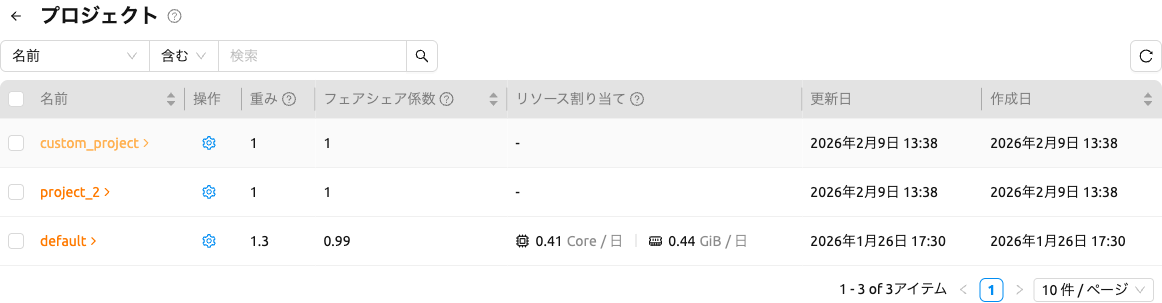
行を選択した場合、同じ一括操作(利用グラフおよび一括編集)が利用可能です。
ユーザー#
プロジェクトを選択すると、ユーザーステップで個々のユーザーのフェアシェア重みと 使用量がテーブルで表示されます。
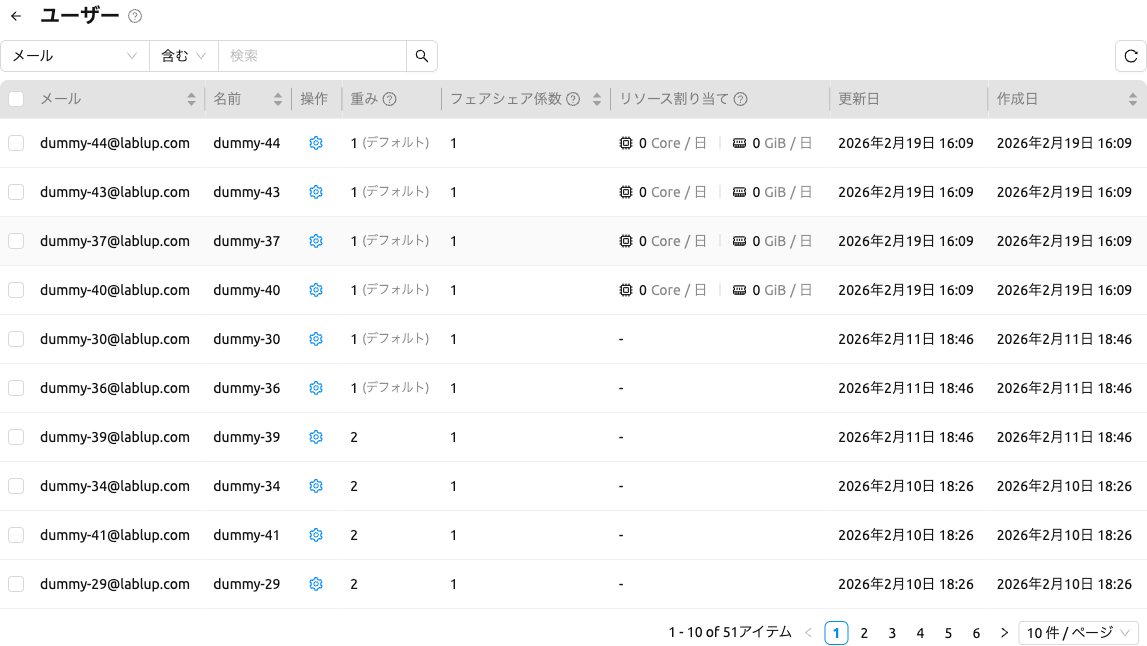
テーブルには以下のカラムが含まれます:
- メール: ユーザーのメールアドレスです。
- 名前: ユーザーの名前です。
- 制御: 重み設定モーダルを開く設定(歯車)ボタンです。
- 重み: 現在の重み値です。デフォルトの重みを使用している場合は「デフォルト」と表示されます。
- フェアシェア係数: フェアシェアスケジューラによって算出されたスケジューリング優先度です。
- リソース割り当て: リソースタイプごとの1日あたりの平均減衰リソース使用量です。
- 更新日時: 最終更新のタイムスタンプです。
- 作成日時: 作成のタイムスタンプです。
ユーザーステップでは、メール、名前、アクティブ状態による追加フィルタが利用可能です。
行を選択した場合、同じ一括操作(利用グラフおよび一括編集)が利用可能です。
フェアシェア重みの編集#
ドメイン、プロジェクト、またはユーザーのフェアシェア重みを編集するには、対象の行の 制御カラムにある設定(歯車)ボタンをクリックします。重み設定モーダルが開きます。
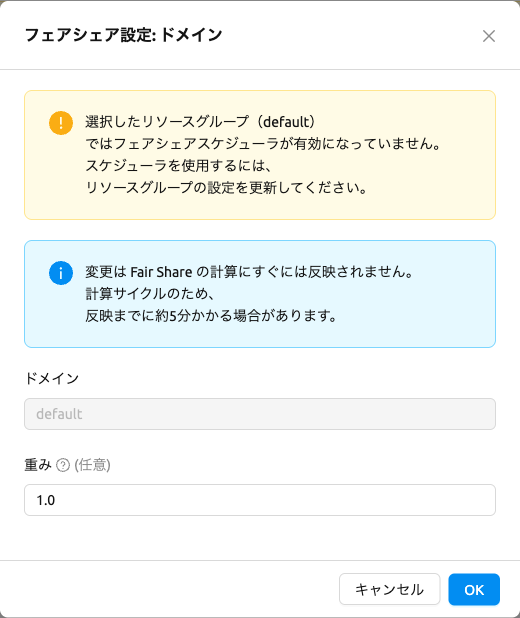
変更はFair Shareの計算にすぐには反映されません。計算サイクルのため、反映までに 約5分かかる場合があります。
単一編集モードでは、モーダルにエンティティ名(読み取り専用)と重み入力フィールドが 表示されます。
- 重み: Fair Shareスケジューリングの優先度を決定する基本倍率です。値が大きいほど優先度が高くなります。デフォルトは「1.0」です。重み「2.0」は「1.0」の2倍の優先度です。最小値は1、ステップは0.1です。
複数の項目の重みを一括で編集するには、テーブルのチェックボックスで対象の行を選択し、 一括編集(歯車アイコン)ボタンをクリックします。一括編集モードでは、モーダルに選択した すべてのエンティティのタグリストと、すべてに適用される単一の重み入力フィールドが 表示されます。
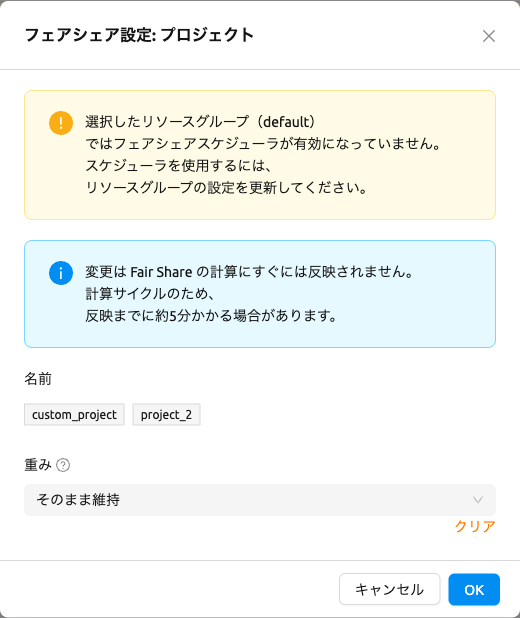
選択したリソースグループのスケジューラタイプがFAIR_SHAREに設定されていない場合、
モーダルに警告アラートが表示されます。
利用履歴の表示#
ドメイン、プロジェクト、またはユーザーの利用履歴を表示するには、テーブルの チェックボックスで対象の行を選択し、利用グラフ(チャートアイコン)ボタンをクリック します。利用履歴モーダルが開きます。
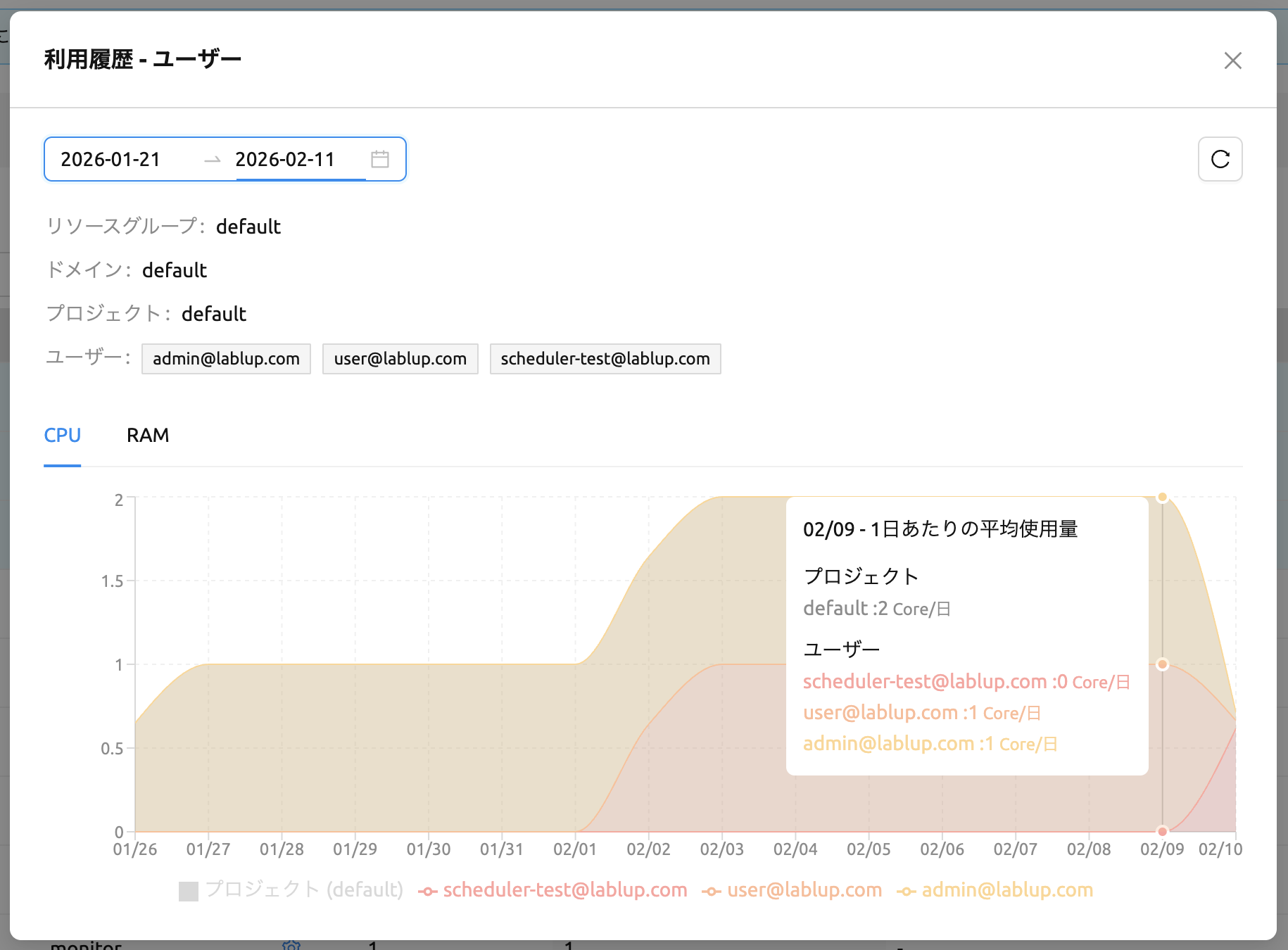
モーダルには以下が表示されます:
- 日付範囲ピッカー: 利用履歴の日付範囲を選択します。過去7日間、過去30日間、過去90日間のプリセットが利用可能です。
- リフレッシュボタン: 利用データを手動で更新します。
- コンテキスト情報: 現在のステップに応じて、リソースグループ、ドメイン、プロジェクトの情報が表示されます。
- 選択されたエンティティ: 選択した項目の名前がタグとして表示されます。
- 利用チャート: 選択した期間の1日あたりの平均リソース使用量を示すチャートです。
イメージ管理#
管理者はEnvironmentsページのImagesタブで、コンピュートセッションの作成に使用されるイメージを管理できます。このタブでは、現在Backend.AIサーバーにあるすべてのイメージのメタ情報が表示されます。レジストリ、アーキテクチャ、ネームスペース、イメージ名、ダイジェスト、各イメージに必要な最小リソースなどの情報を確認できます。1つ以上のエージェントノードにダウンロードされたイメージの場合、Statusカラムにinstalledタグが表示されます。
特定のエージェントを選択してイメージをインストールする機能は現在開発中です。
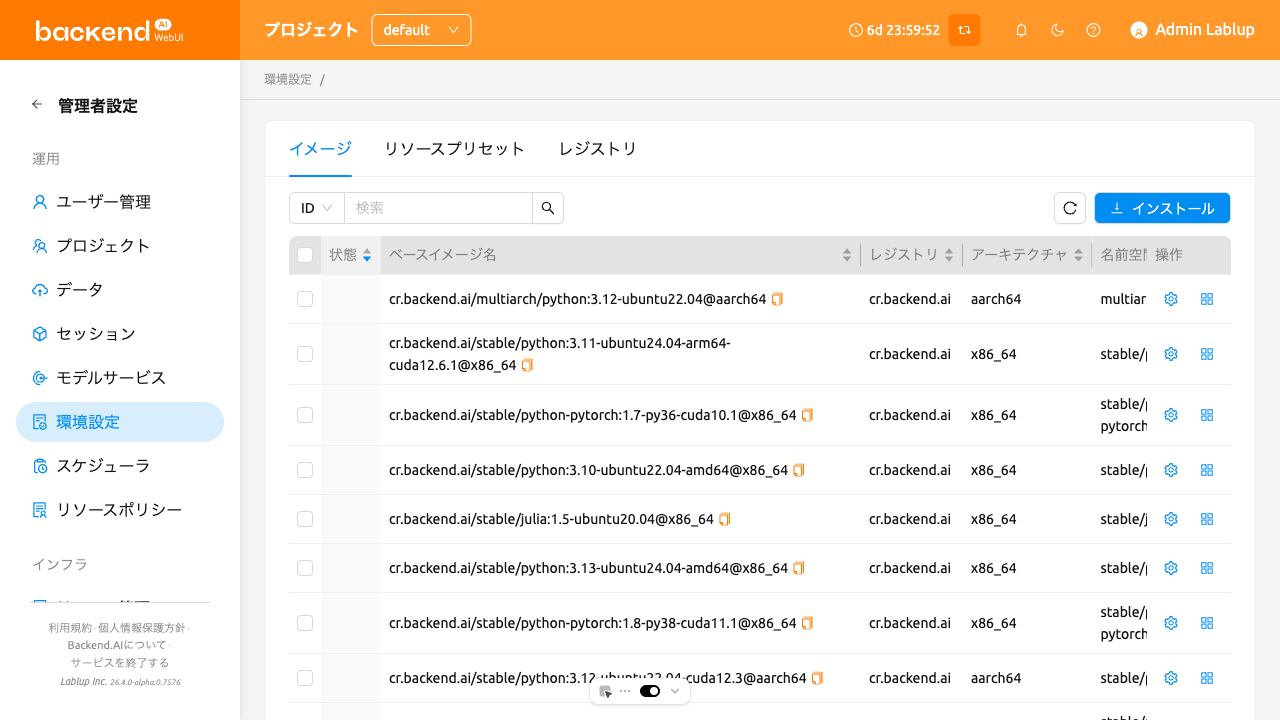
イメージリストには、より詳細なイメージ情報のための追加カラムが表示されます:
- アーキテクチャ: イメージのCPUアーキテクチャです(例:x86_64、aarch64)。
- 名前空間: レジストリ内のイメージのネームスペースです。
- ベースイメージ名: イメージの基本名で、識別しやすいようにエイリアスタグが表示されます。
- バージョン: イメージのバージョンタグです。
- タグ: イメージに関連する詳細なタグで、エイリアス付きのダブルタグとして表示されます。
未インストールのイメージを複数選択し、インストールボタンをクリックすると、利用可能なエージェントノードに一括インストールできます。
コントロールパネルの「設定(歯車)」をクリックすると、各イメージの最小リソース要件を 変更できます。各イメージには最小動作のためのハードウェアおよびリソース要件があります (例えば、GPU専用イメージの場合は、GPUが最低限割り当てられる必要があります)。 最小リソース量のデフォルト値は、イメージのメタデータに埋め込まれた形で提供されます。 各イメージで指定されたリソース量より少ないリソースでコンピュートセッションを作成しようと した場合、リクエストはキャンセルされず、イメージの最小リソース要件に自動的に調整されて 作成されます。
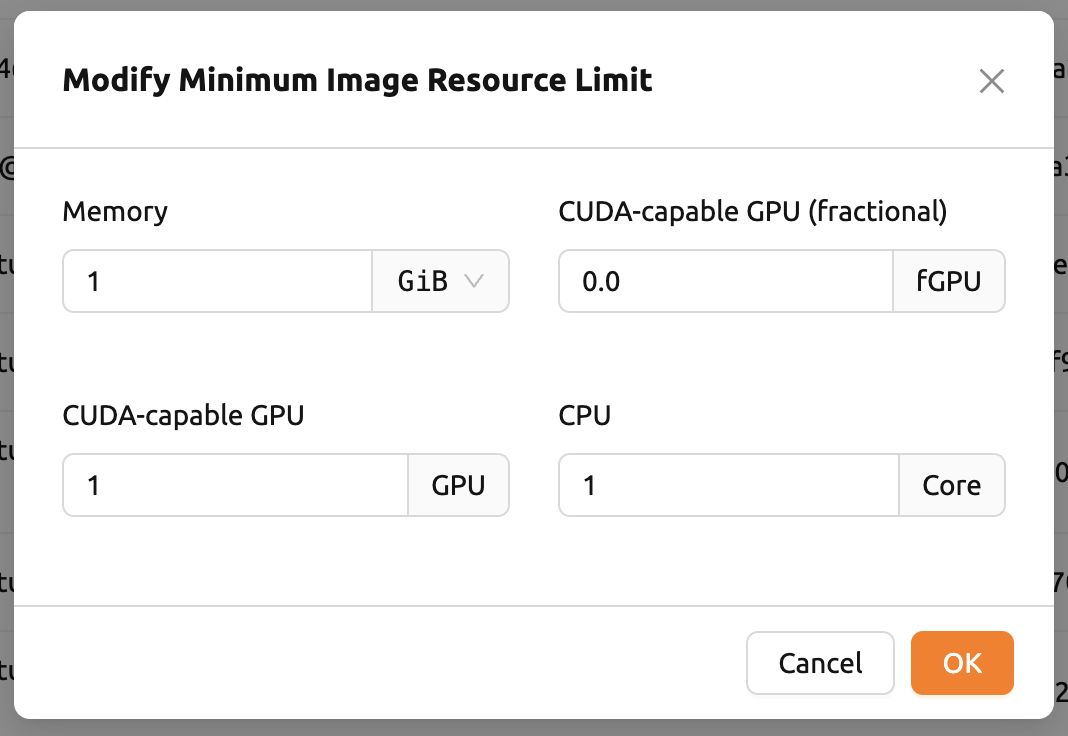
事前定義された値より少ない量に最小リソース要件を変更しないでください。イメージメタデータに 含まれる最小リソース要件は、テストされ決定された値です。変更したい最小リソース量が 本当に適切かわからない場合は、デフォルトのままにしてください。
さらに、「コントロール」列にある「Apps」アイコンをクリックすると、各イメージの サポートアプリを追加または変更できます。アイコンをクリックすると、アプリ名とその ポート番号が表示されます。
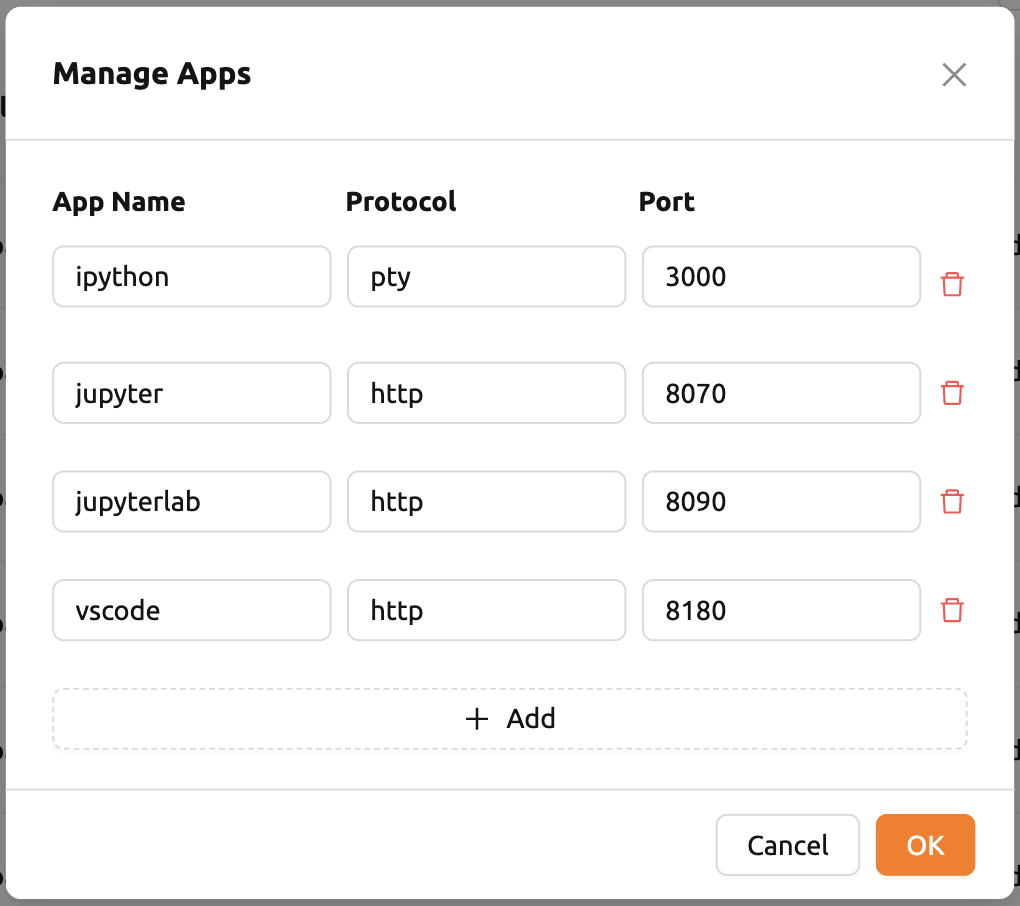
このインターフェースでは、下部の「+ Add」ボタンをクリックして、サポートされるカスタム アプリケーションを追加できます。アプリケーションを削除するには、各行の右側にある 「赤いゴミ箱」ボタンをクリックします。
管理対象アプリを変更した後は、イメージを再インストールする必要があります。
Dockerレジストリ管理#
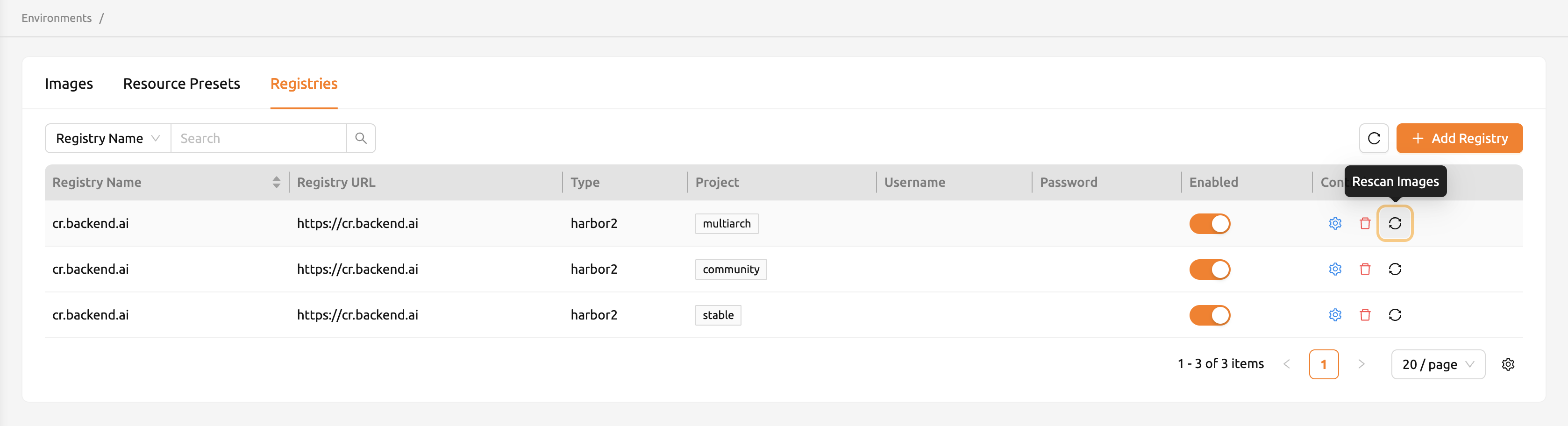
EnvironmentsページのRegistriesタブをクリックすると、現在接続されているDocker
レジストリの情報を確認できます。デフォルトでcr.backend.aiが登録されており、これは
Harborが提供するレジストリです。
オフライン環境ではデフォルトのレジストリにアクセスできないため、右側のゴミ箱アイコンを クリックして削除してください。
「コントロール」列の更新アイコンをクリックすると、接続されたレジストリからBackend.AI用の イメージメタデータを更新できます。レジストリに保存されたイメージのうち、Backend.AI用の ラベルを持たないイメージ情報は更新されません。
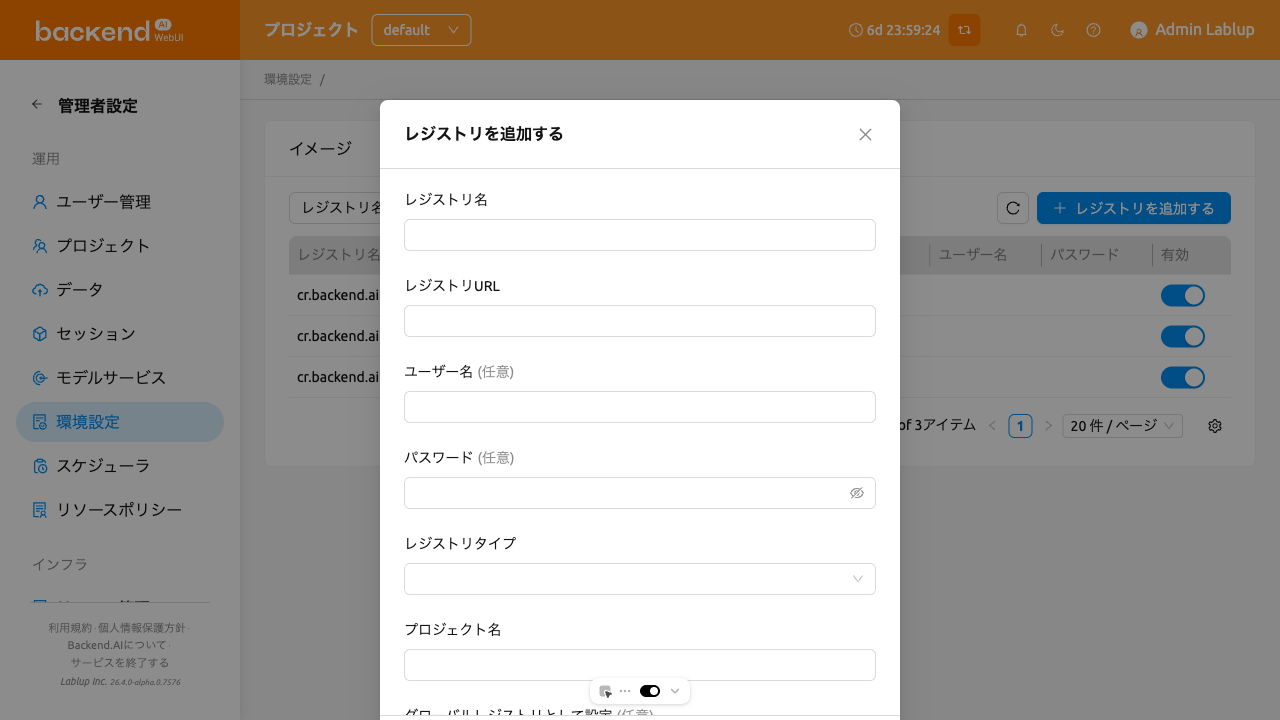
'+ Add Registry'ボタンをクリックして、独自のプライベートDockerレジストリを追加できます。レジストリ作成ダイアログには以下のフィールドが含まれています:
- レジストリ名: レジストリの一意の名前です(最大50文字)。レジストリに保存されたイメージ名のプレフィックスと一致する必要があります。
- レジストリURL: レジストリのURLです。
http://またはhttps://などのスキームを明示的に含める必要があります。 - ユーザー名: オプション。レジストリに別途認証設定がある場合に入力します。
- パスワード: オプション。既存のレジストリを編集する場合、
Change Passwordチェックボックスを選択して変更できます。 - レジストリタイプ: レジストリの種類を選択します。サポートされる種類:
docker、harbor、harbor2、github、gitlab、ecr、ecr-public。 - プロジェクト名: レジストリのプロジェクトまたはネームスペースです(必須)。GitLabレジストリの場合、ネームスペースとプロジェクト名を含む完全なパスを使用します。
- 追加情報: 各レジストリタイプに必要な追加設定用のJSON文字列です。このフィールドはバージョン24.09.3から利用可能です。
GitLab Container Registry設定#
GitLabコンテナレジストリを追加する場合、Extra Informationフィールドにapi_endpointを指定する必要があります。これはGitLabがコンテナレジストリとGitLab APIで別々のエンドポイントを使用するためです。
**GitLab.com(パブリックインスタンス)**の場合:
- Registry URL:
https://registry.gitlab.com - Extra Information:
{"api_endpoint": "https://gitlab.com"}
セルフホスト(オンプレミス)GitLabの場合:
- Registry URL: ご使用のGitLabレジストリURL(例:
https://registry.example.com) - Extra Information:
{"api_endpoint": "https://gitlab.example.com"}
api_endpointはGitLabインスタンスのURLを指す必要があり、レジストリURLではありません。
追加の設定に関する注意:
プロジェクトパスの形式: プロジェクトを指定する際は、ネームスペースとプロジェクト名を含む完全なパスを使用してください(例:
namespace/project-name)。レジストリが正しく機能するには両方のコンポーネントが必要です。アクセストークンの権限: レジストリに使用するアクセストークンには
read_registryとread_apiの両方のスコープが必要です。read_apiスコープはBackend.AIが再スキャン操作中にGitLab APIでイメージメタデータをクエリするために必要です。
既存のレジストリの情報を更新することもできますが、レジストリ名は変更できません。
レジストリを作成してイメージメタデータを更新した後も、ユーザーはすぐにイメージを使用できるわけではありません。レジストリリストのEnabledスイッチを切り替えてレジストリを有効にし、ユーザーがレジストリからイメージにアクセスできるようにする必要があります。
リソースプリセットの管理#
以下の事前定義されたリソースプリセットは、コンピュートセッション作成時のリソース割り当てパネルに表示されます。スーパー管理者はこれらのリソースプリセットを管理できます。
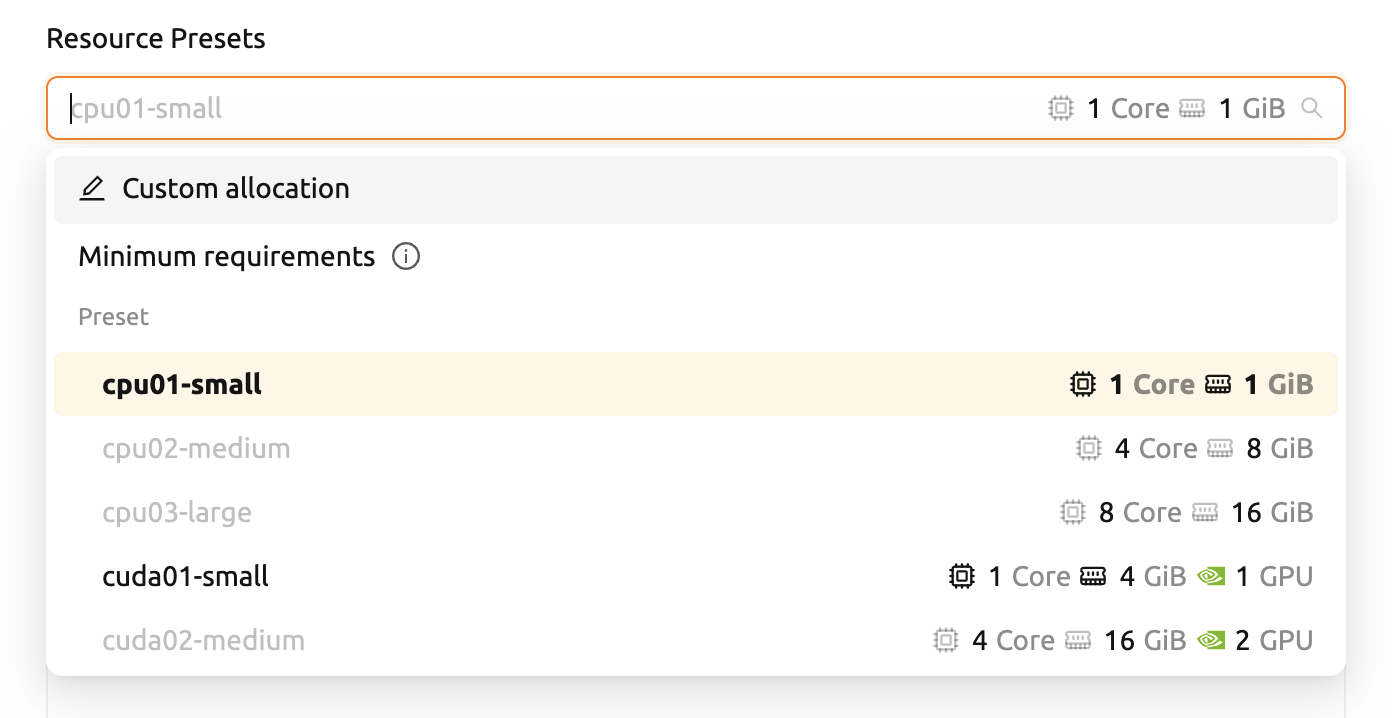
EnvironmentページのResource Presetsタブに移動します。現在定義されているリソースプリセットのリストを確認できます。
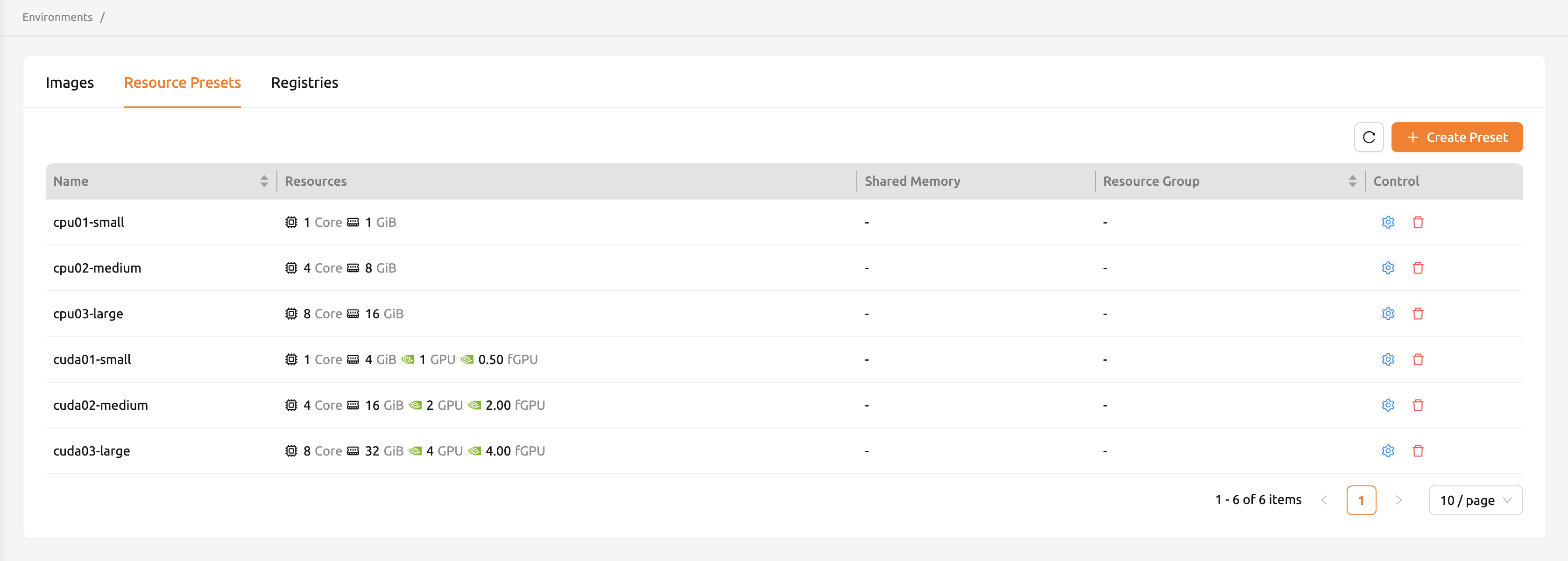
「コントロール」列の「設定」ボタンをクリックして、リソースプリセットが提供するCPU、RAM、fGPUなどのリソースを設定できます。リソースプリセットの作成または変更モーダルには、現在利用可能なリソースのフィールドが表示されます。サーバーの設定によっては、特定のリソースが表示されない場合があります。希望の値でリソースを設定した後、保存して、コンピュートセッション作成時に対応するプリセットが表示されるか確認してください。利用可能なリソースがプリセットで定義されたリソース量より少ない場合、対応するプリセットは表示されません。
リソースプリセットダイアログには以下の項目が含まれます:
- プリセット名: プリセットの一意の名前です(英数字、ピリオド、ハイフン、アンダースコアのみ使用可能)。
- リソースグループ: (条件付き)プリセットを特定のリソースグループに関連付けます。
- リソースプリセット: 利用可能な各リソースタイプ(CPU、メモリ、GPUなど)を入力する動的フィールドのまとまりです。メモリフィールドは動的な単位入力(MiB、GiB、TiB、PiB)をサポートしています。
- 共有メモリ: プリセットに割り当てられた共有メモリの量です。この値はメモリの値より少なくなければなりません。
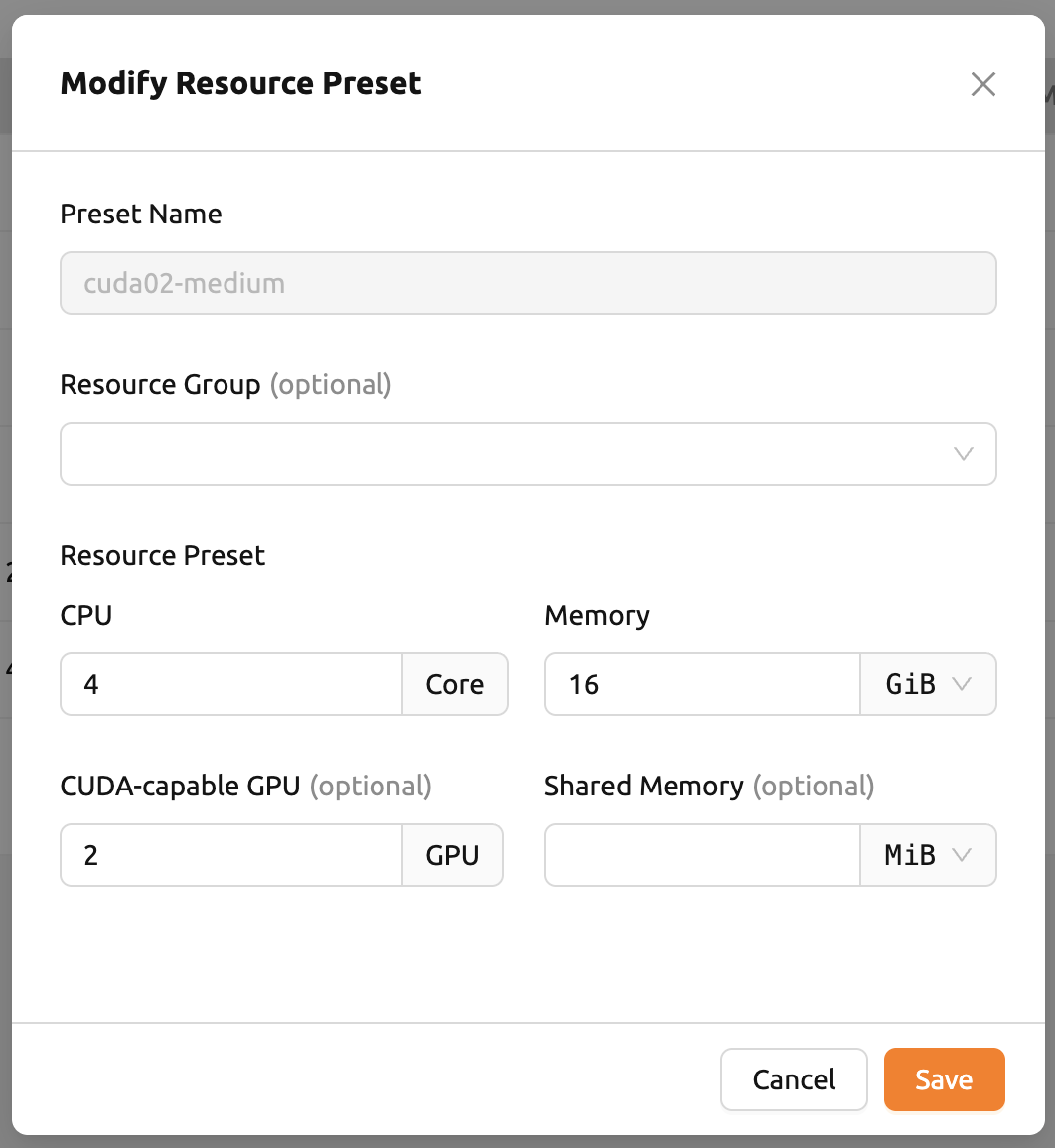
「リソースプリセット」タブの右上にある「+ プリセットの作成」ボタンをクリックしてリソースプリセットを作成することもできます。既に存在する名前と同じリソースプリセットは作成できません。名前は各リソースプリセットを区別するキー値です。
エージェントノードの管理#
スーパー管理者は、Resourcesページにアクセスして、現在Backend.AIに接続されているエージェントワーカーノードのリストを表示できます。エージェントノードのIP、接続時間、現在実際に使用中のリソースなどを確認できます。WebUIはエージェントノードを操作する機能を提供していません。
エージェントノードの照会#
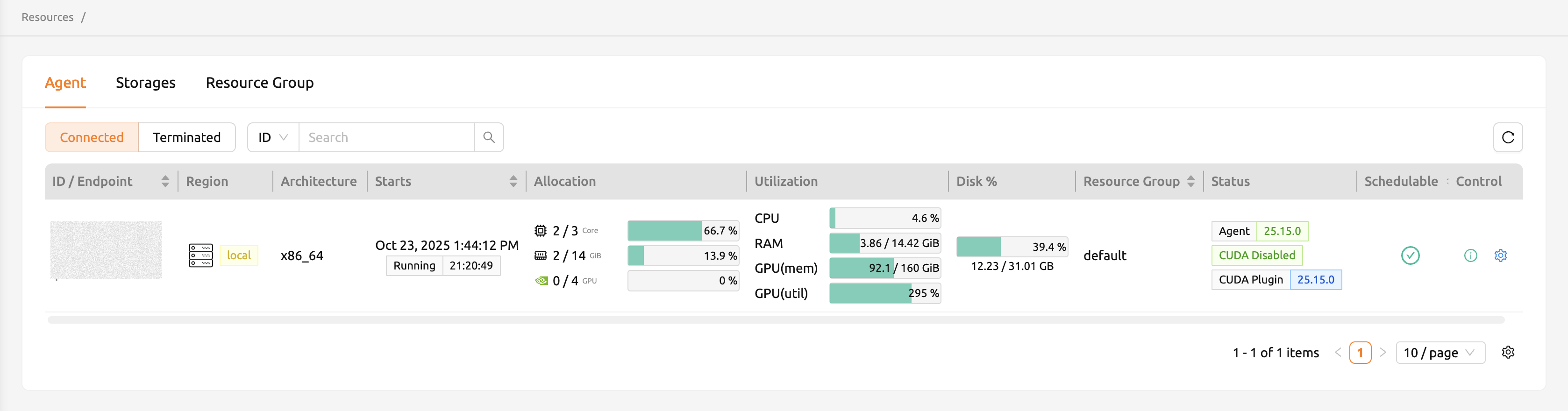
「コントロール」列のノートアイコンをクリックすると、エージェントワーカーノードのリソースの正確な使用状況を確認できます。

Terminatedタブでは、一度接続されてから終了または切断されたエージェントの情報を確認できます。ノード管理の参考資料として使用できます。リストが空の場合、切断や終了が発生していないことを意味します。
エージェントノードのスケジュール可能ステータスの設定#
エージェントサービスを停止せずに新しいコンピュートセッションがスケジュールされることを防止したい場合があります。その場合、エージェントのSchedulableステータスを無効にできます。これにより、エージェント上の既存のセッションを保持しながら、新しいセッションの作成をブロックできます。
リソースグループの管理#
エージェントはリソースグループと呼ばれる単位にグループ化できます。例えば、V100 GPUを搭載したエージェント3台とP100 GPUを搭載したエージェント2台がある場合、2種類のGPUをユーザーに別々に公開するには、V100エージェント3台を1つのリソースグループに、残りのP100エージェント2台を別のリソースグループにグループ化できます。
特定のエージェントを特定のリソースグループに追加する操作は、現在WebUIでは処理されていません。インストール場所からエージェントのconfigファイルを編集し、エージェントデーモンを再起動して行えます。リソースグループの管理は、ResourceページのResource Groupタブで可能です。
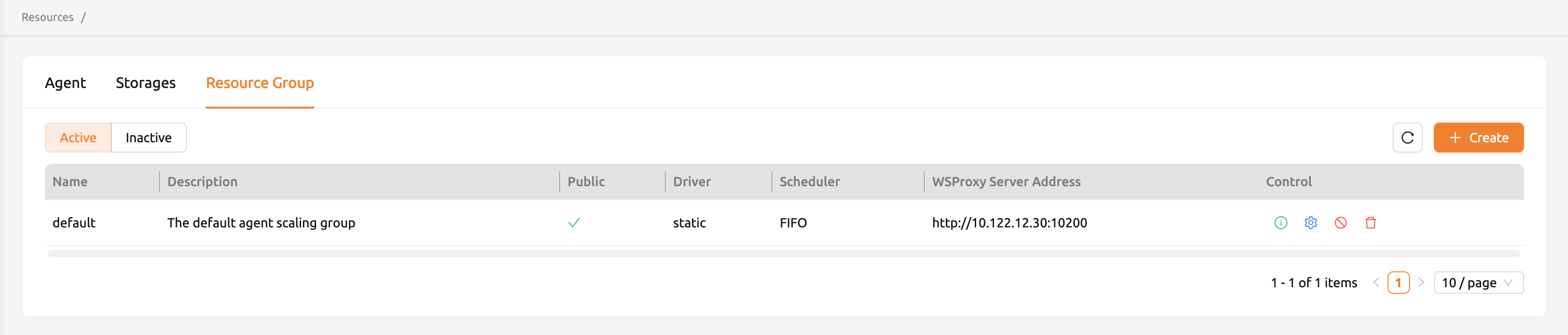
「コントロール」列の「設定」ボタンをクリックしてリソースグループを編集できます。「スケジューラーを選択」フィールドで、コンピュートセッション作成のスケジューリング方法を選択できます。現在、FIFO、LIFO、DRF、FAIR_SHAREの4種類があります。FIFOとLIFOはジョブキューで最初または最後にキューイングされたコンピュートセッションを作成するスケジューリング方法です。DRFはDominant Resource Fairnessの略で、各ユーザーにできるだけ公平にリソースを提供することを目指します。FAIR_SHAREは過去の使用パターンに基づいてコンピュートリソースを割り当てます。詳細については、フェアシェアスケジューラセクションを参照してください。「アクティブ」ステータスをオフにすることでリソースグループを無効化できます。
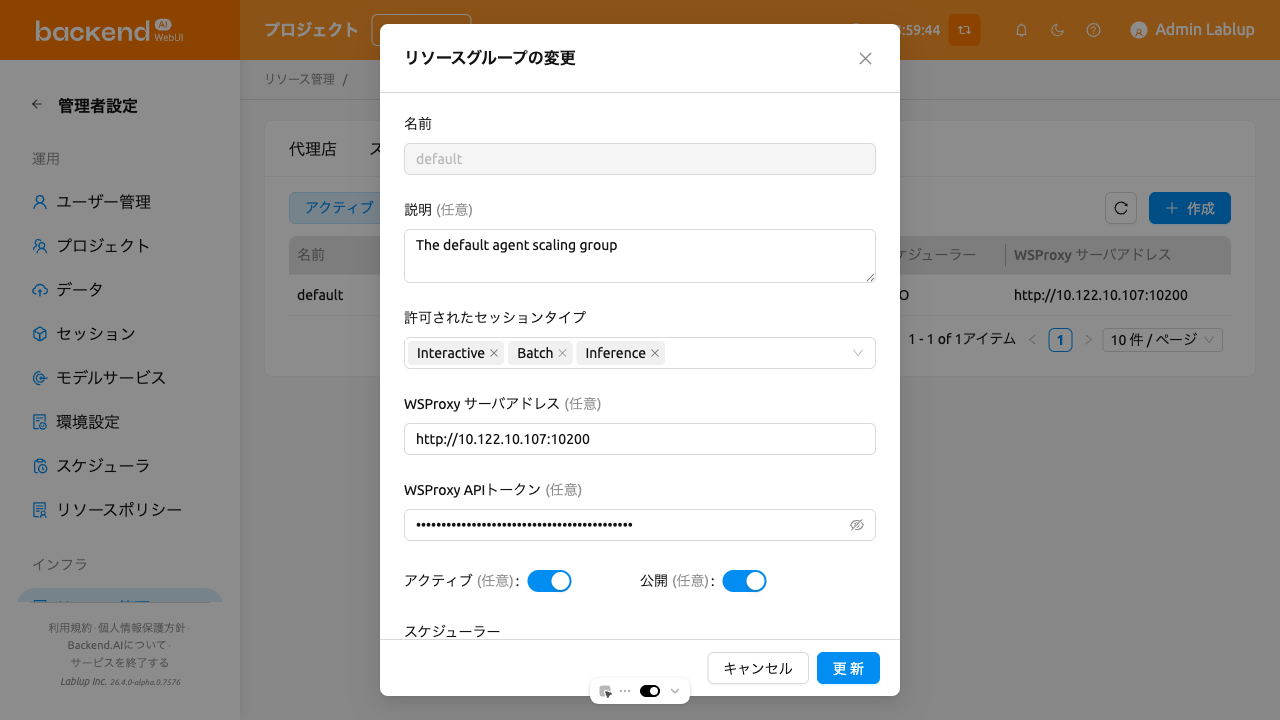
リソースグループ編集ダイアログには以下の追加フィールドが含まれています:
- 許可されたセッションタイプ: ユーザーがセッションタイプを選択できるため、リソースグループで特定のタイプを許可できます。少なくとも1つのセッションタイプを許可する必要があります。許可されるセッションタイプは Interactive、Batch、Inference、System です。
- WSProxy サーバアドレス: リソースグループのエージェントが使用するWSProxyアドレスを設定します。このフィールドにURLを設定すると、WSProxyがJupyterなどのアプリのトラフィックをManagerをバイパスしてエージェント経由でコンピュートセッションに直接中継します(v2 API)。WSProxyからエージェントノードへの直接接続が利用できない場合は、このフィールドを空白のままにしてv1 APIにフォールバックしてください。
- WSProxy APIトークン: WSProxyサーバーとの認証用APIトークンです。
- アクティブ: リソースグループの有効/無効を切り替えます。
- 公開: 有効にすると、リソースグループがすべてのユーザーに表示されます。
- 保留中のタイムアウト: コンピュートセッションが保留中のタイムアウトより長く
PENDING状態を維持すると取り消されます。この値をゼロ(0)に設定すると、この機能は適用されません。 - 保留中セッションをスキップする再試行回数: スケジューラがPENDINGセッションをスキップする前に試行する回数です。
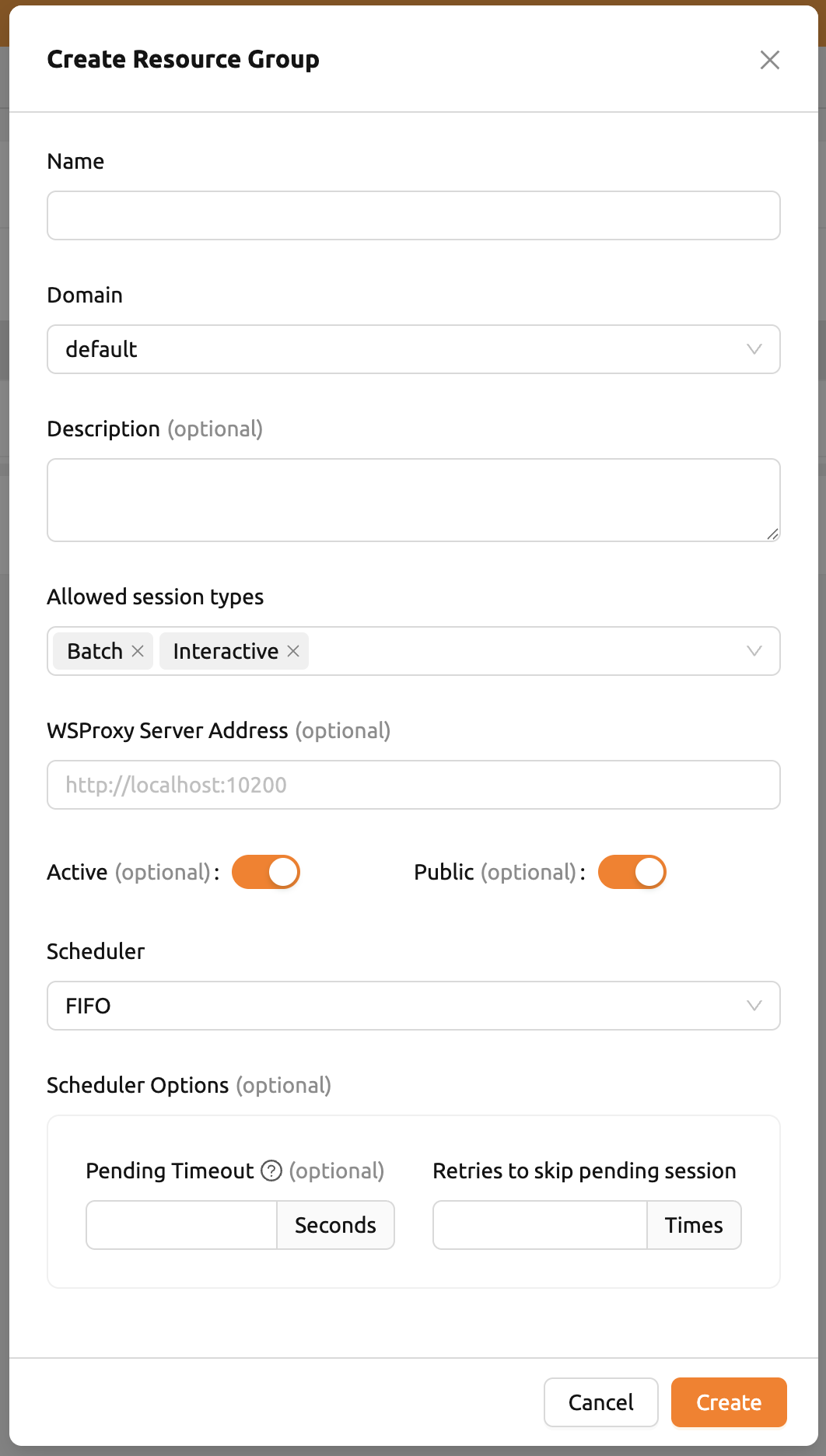
「+ 作成」ボタンをクリックして新しいリソースグループを作成できます。他の作成オプションと同様に、既に存在する名前ではリソースグループを作成できません。名前はキー値です。
ストレージ#
STORAGESタブでは、どのようなマウントボリューム(通常はNFS)が存在するかを確認できます。 バージョン23.03以降、クォータ管理をサポートするストレージに対してユーザーごと/ プロジェクトごとのクォータ設定を提供しています。この機能を使用すると、管理者は ユーザーおよびプロジェクト単位のフォルダのストレージ使用量を簡単に管理およびモニター できます。
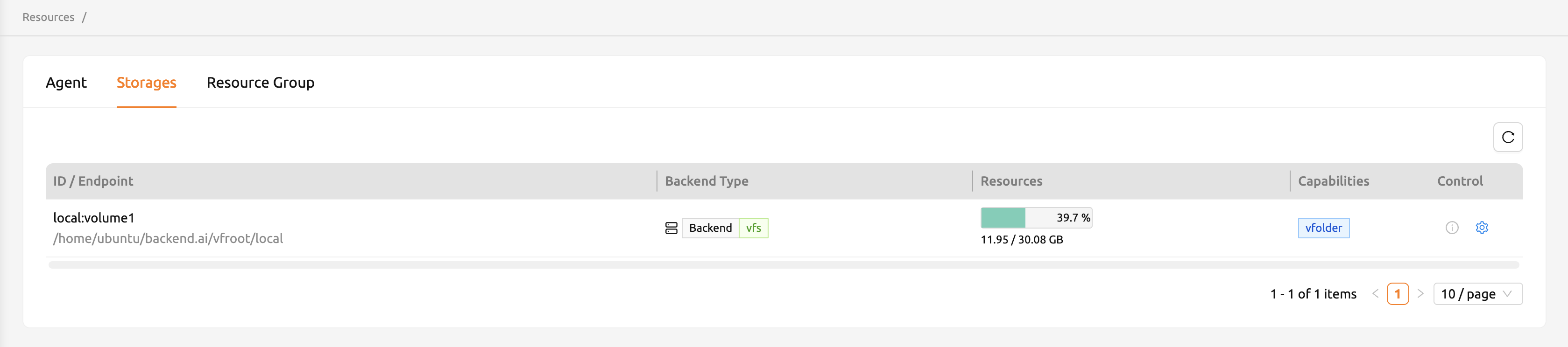
クォータを設定するには、まずリソースページのストレージタブにアクセスする必要があります。 その後、「コントロール」列の「設定(歯車)」をクリックします。
クォータ設定はクォータ設定を提供するストレージ(例:XFS、CephFS、NetApp、Purestorage など)でのみ利用可能である点にご注意ください。ストレージの種類に関係なくクォータ設定 ページでストレージの使用量を確認できますが、内部的にクォータ設定をサポートしていない ストレージにはクォータを設定できません。
クォータ設定パネル#
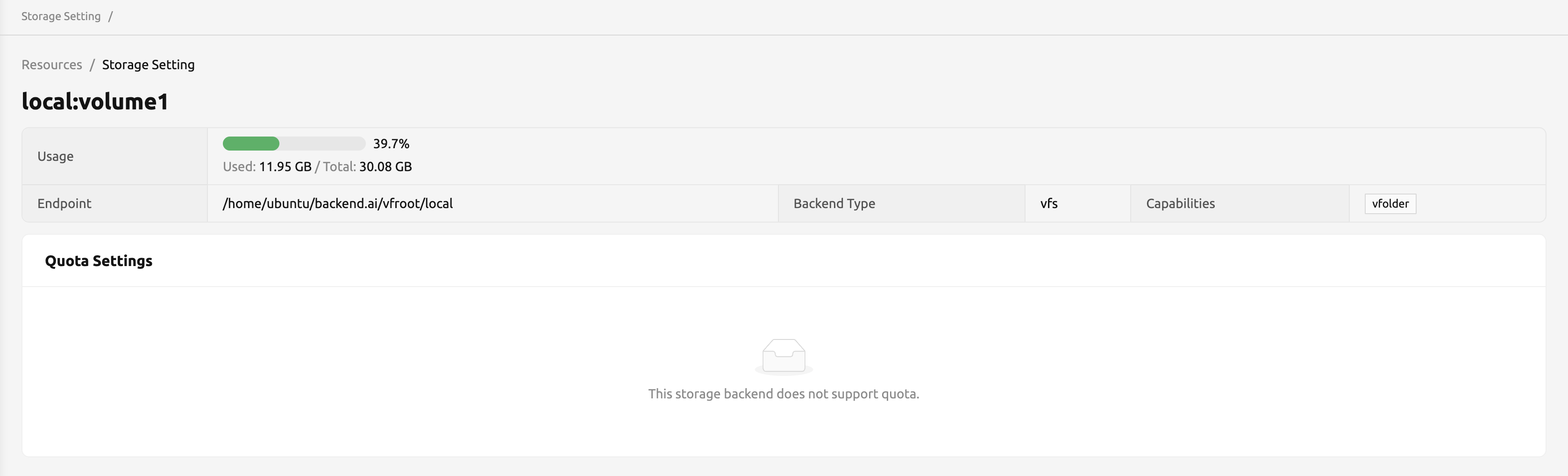
クォータ設定ページには、2つのパネルがあります。
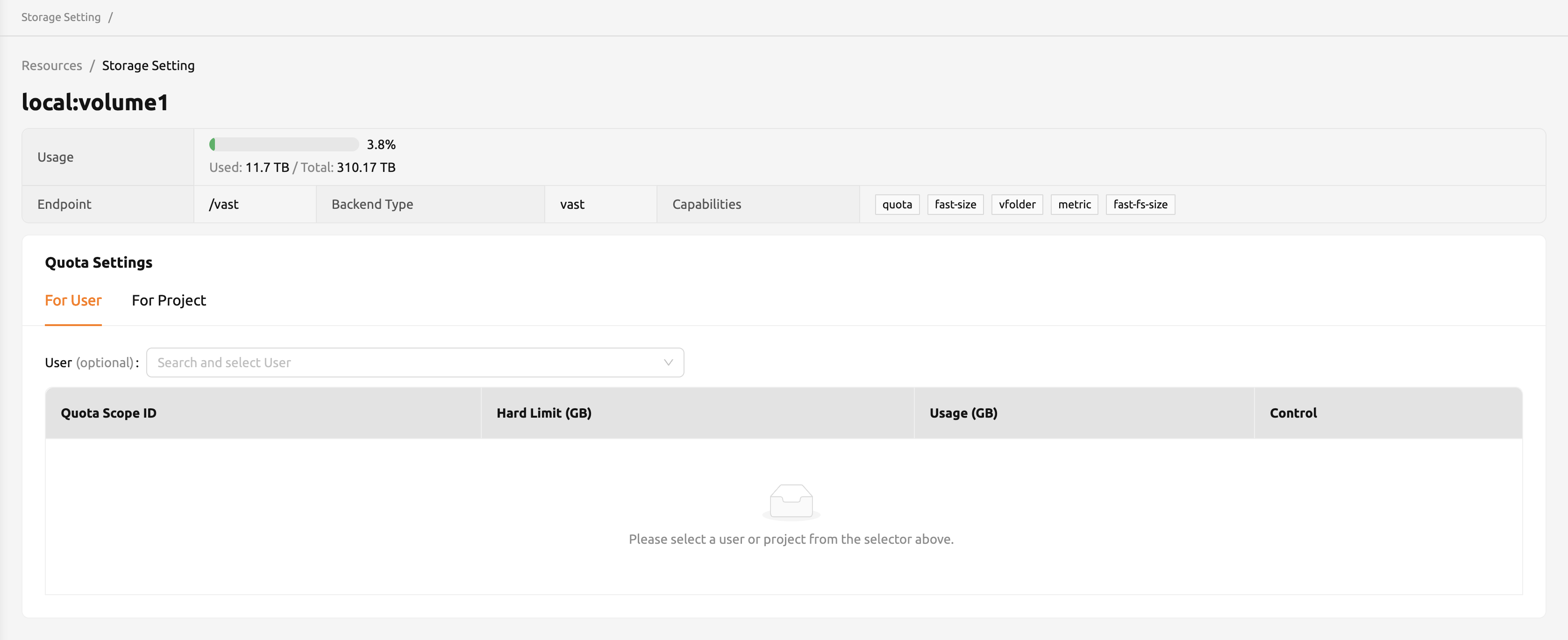
Overviewパネル
- Usage: 選択したストレージの実際の使用量を表示します。
- Endpoint: 選択したストレージのマウントポイントを示します。
- Backend Type: ストレージの種類です。
- Capabilities: 選択したストレージでサポートされる機能です。
Quota Settings
- For User: ここでユーザーごとのクォータ設定を行います。
- For Project: ここでプロジェクトごとのクォータ(プロジェクトフォルダ)設定を行います。
- ID: ユーザーまたはプロジェクトIDに対応します。
- Hard Limit (GB): 選択したクォータに対して現在設定されているハードリミットです。
- Control: ハードリミットの編集やクォータ設定の削除を提供します。
ユーザークォータの設定#
Backend.AIには、ユーザーが作成するvfolderと管理者が作成するvfolder(プロジェクト)の
2種類があります。このセクションでは、ユーザーごとの現在のクォータ設定を確認する方法と、
その設定方法を示します。まず、クォータ設定パネルのアクティブタブがFor Userであることを
確認してください。次に、クォータを確認および編集したいユーザーを選択します。すでに
クォータを設定している場合は、ユーザーIDに対応するクォータIDと、すでに設定されている
構成をテーブルで確認できます。
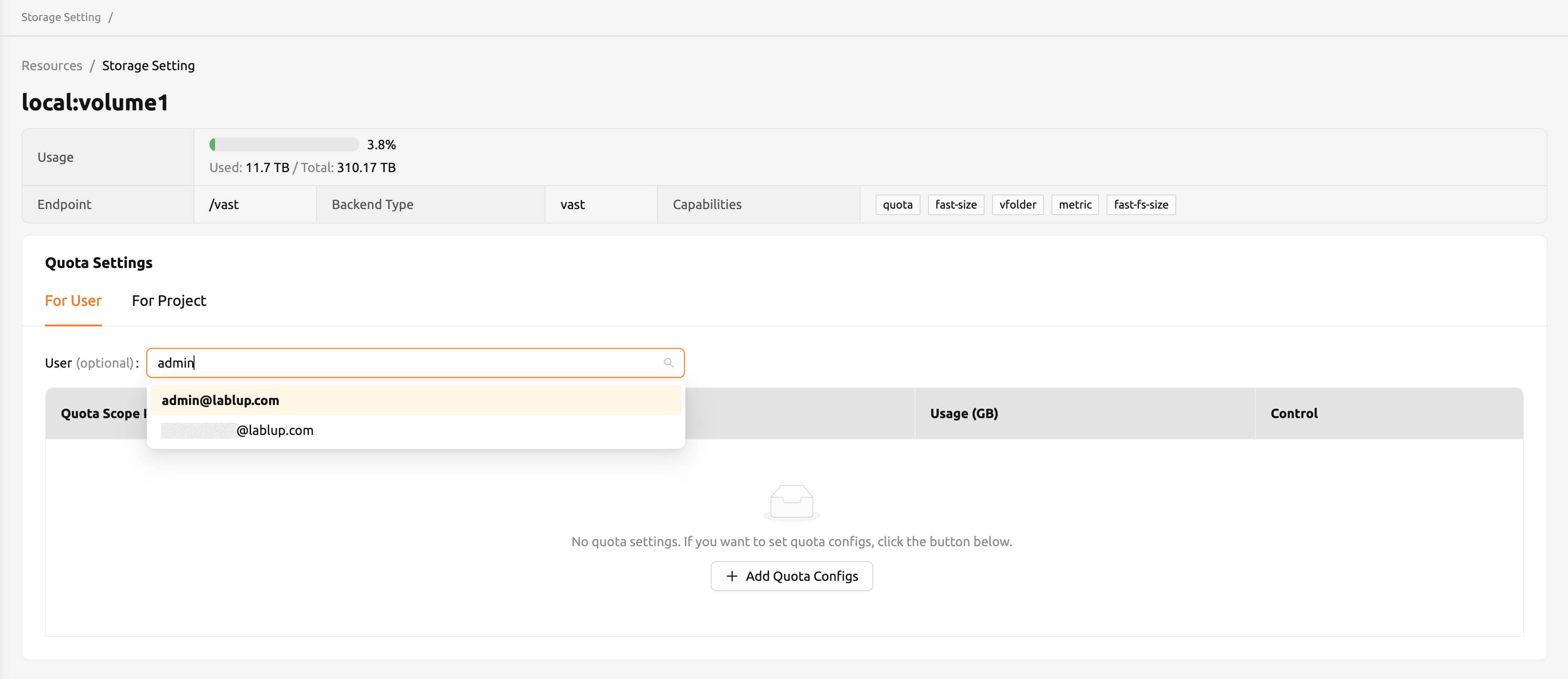
もちろん、クォータを編集したい場合は、「コントロール」列のEditボタンをクリックするだけで
可能です。Editボタンをクリックすると、クォータ設定を構成できる小さなモーダルが表示
されます。正確な量を入力した後、変更を適用するために必ずOKボタンをクリックして
ください。
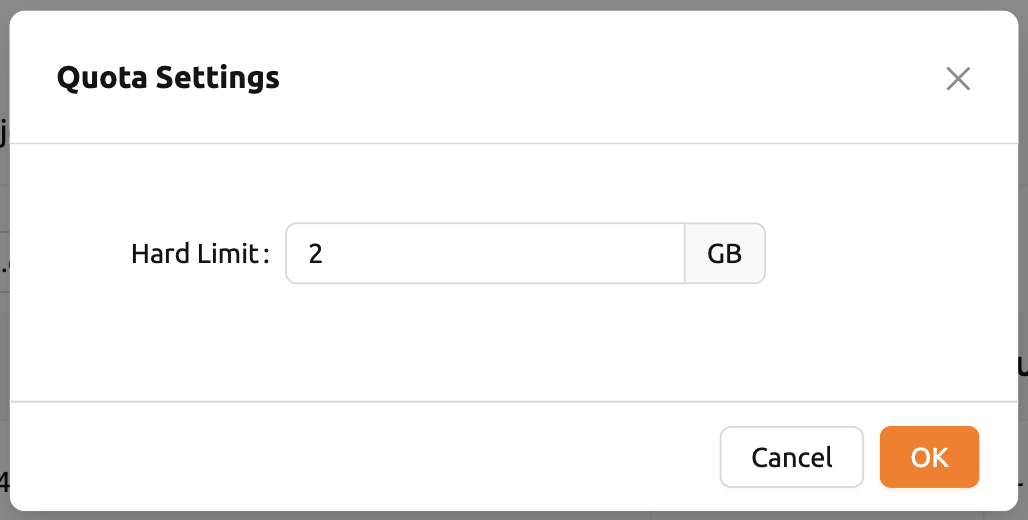
プロジェクトクォータの設定#
プロジェクトフォルダにクォータを設定する方法は、ユーザークォータの設定と似ています。 プロジェクトクォータとユーザークォータの設定の違いは、プロジェクトクォータの設定では、 プロジェクトが依存するドメインを選択するという追加の手順が必要なことです。その他は 同じです。下の画像のように、まずドメインを選択してから、プロジェクトを選択する必要が あります。
クォータの解除#
クォータを解除する機能も提供しています。クォータ設定を削除すると、クォータは自動的に
ユーザーまたはプロジェクトのデフォルトクォータに従う点にご注意ください。デフォルトは
WebUIでは設定できません。デフォルトクォータ設定を変更したい場合は、管理者専用の
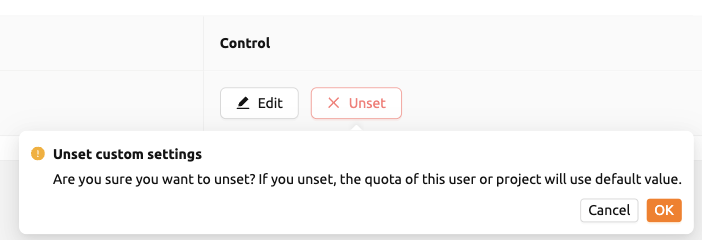
ページにアクセスする必要があります。「コントロール」列のUnsetボタンをクリックすると、
現在のクォータ設定を本当に削除するかどうかを確認する小さなスナックバーメッセージが
表示されます。スナックバーメッセージでOKボタンをクリックすると、クォータ設定が削除され、
クォータタイプ(ユーザー/プロジェクト)に応じて対応するクォータに自動的にリセットされます。
ユーザー/プロジェクトごとの設定がない場合は、ユーザー/プロジェクトリソースポリシーの
対応する値がデフォルト値として設定されます。例えば、クォータのハードリミット値が
設定されていない場合、リソースポリシーのmax_vfolder_size値がデフォルト値として
使用されます。
セッションリストのダウンロード#
この機能は現在、デフォルトのSessionページでは利用できません。この機能を使用するには、 User Settingページの「Switch back to the Classic UI」セクションで「Classic Session list page」オプションを有効にしてください。詳細については、 Backend.AI User Settingsセクションを参照してください。
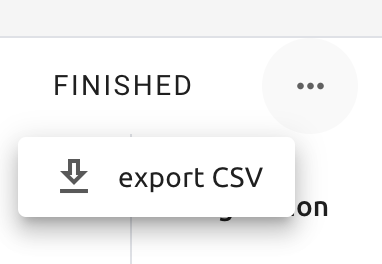
Sessionページには管理者向けの追加機能があります。FINISHEDタブの右側には、...と
記されたメニューがあります。このメニューをクリックすると、export CSVサブメニューが
表示されます。
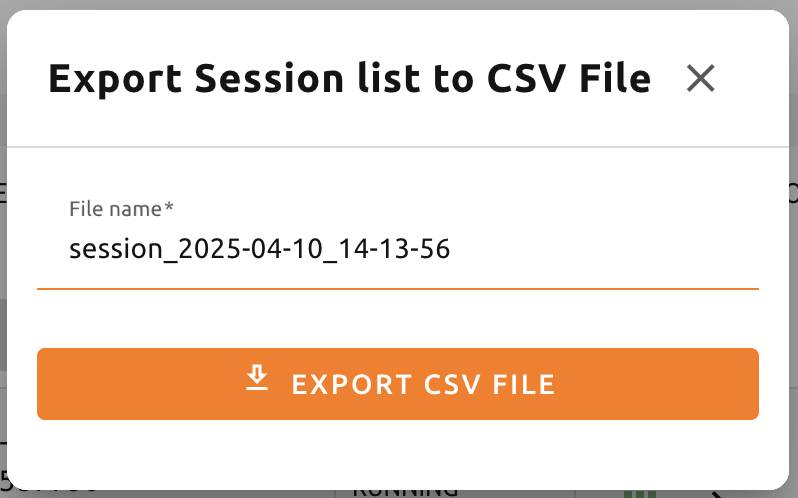
このメニューをクリックすると、これまでに作成されたコンピュートセッションの情報を CSV形式でダウンロードできます。次のダイアログが開いたら、適切なファイル名を入力し (必要に応じて)、EXPORTボタンをクリックするとCSVファイルを取得できます。 ファイル名は最大255文字まで使用できる点にご注意ください。
システム設定#
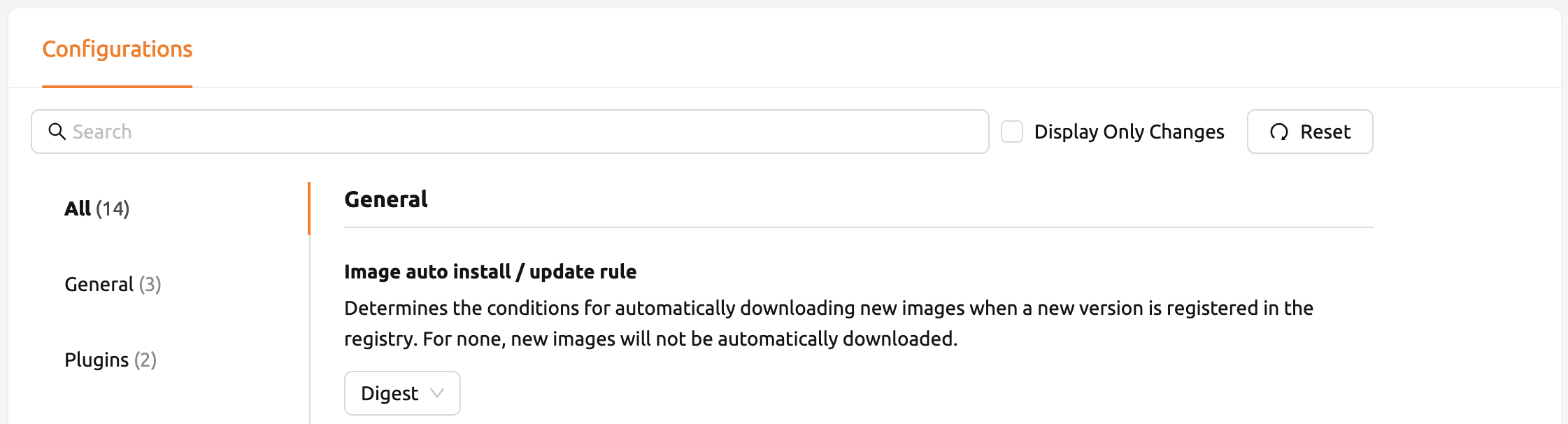
ConfigurationページでBackend.AIサーバーの主要な設定を確認できます。現在、設定を変更および 一覧表示できる複数のコントロールが提供されています。
Digest、Tag、Noneのオプションから1つを選択することで、イメージの自動インストールと
更新ルールを変更できます。Digestはイメージのチェックサムの一種で、イメージの整合性を
検証し、重複するレイヤーを再利用することで、イメージのダウンロード効率を向上させます。
Tagはイメージの整合性を保証しないため、開発用のオプションのみとなります。
各ルールの意味を完全に理解していない場合は、ルールの選択を変更しないでください。
Configurationsページでは、プラグインとエンタープライズ機能のステータスも表示されます:
プラグイン:
- オープンソース CUDA GPU サポート: CUDA GPUサポートのステータス。
- ROCm GPU サポート: ROCm GPUサポートのステータス。
エンタープライズ機能:
- Fractional GPU: セッション間でGPUを共有するためのフラクショナルGPU (fGPU) 仮想化。
Backend.AIは、複数のベンダーにわたる幅広いAIアクセラレータをサポートしています:
- NVIDIA
- Spark (GB10)
- Blackwell (B300、B200、RTX Pro 6000など)
- Hopper (H200、H100 NVLなど)
- Grace Superchip (GB300、GB200、GH200など)
- Turing (Titan RTX、RTX 8000、T4)
- Ampere (A100、A40、A10など)
- Ada Lovelace (L40S、L4)
- Jetson (TX、Xavier、Orin、Thorなど)
- Intel
- Gaudi 3
- Gaudi 2
- Gaudi 1
- Arc
- AMD
- Instinct MIシリーズ (MI300Xを含む)
- MI300A
- MI250
- Rebellions
- ATOM Max
- ATOM+
- REBEL
- FuriosaAI
- RNGD
- Tenstorrent
- Wormhole n150s
- Wormhole n300s
- Google
- TPU v7 (Ironwood)
- Coral TPU v5p
- Coral TPU v5e
- TPU v4
- Graphcore
- C600 IPU
- Bow IPU
- HyperAccel
- LPU
- Groq
- LPU
- Cerebras
- WSE-3
- SambaNova
- SN40L
バージョン20.09で導入されたマルチノードクラスターセッションをユーザーが起動すると、 Backend.AIはプライベートなノード間通信をサポートするためにオーバーレイネットワークを 動的に作成します。管理者は、MTU(Maximum Transmission Unit)の値がネットワーク速度の 向上に確実に寄与する場合、オーバーレイネットワークのMTU値を設定できます。
Backend.AIクラスターセッションの詳細については、 Backend.AIクラスターコンピュートセッション セクションを参照してください。
Schedulerの設定ボタンをクリックすると、ジョブスケジューラごとの構成を編集できます。 スケジューラ設定の値は、各リソースグループにスケジューラ設定が ない場合に使用されるデフォルト値です。リソースグループ固有の設定がある場合、この値は 無視されます。
現在サポートされているスケジューリング方式は、FIFO、LIFO、DRFです。各スケジューリング
方式は、上記のスケジューリング方式と同じです。スケジューラ
オプションにはセッション作成再試行が含まれます。セッション作成再試行とは、セッション
作成に失敗した場合の再試行回数を指します。試行回数内にセッションを作成できない場合、
リクエストは無視され、Backend.AIは次のリクエストを処理します。現在、変更が可能なのは
スケジューラがFIFOの場合のみです。
今後も、より広範な設定コントロールを追加していきます。
システム設定はデフォルト設定です。リソースグループに特定の値がある場合、システム設定で 構成された値はそれによって上書きされます。
サーバー管理#
Maintenanceページに移動すると、サーバーを管理するためのいくつかのボタンが表示されます。
- RECALCULATE USAGE: ネットワーク接続が不安定な場合やDockerデーモンのコンテナ管理に 問題がある場合、Backend.AIが占有しているリソースとコンテナが実際に使用しているリソースが 一致しないことがあります。その場合、RECALCULATE USAGEボタンをクリックすることで、 リソースの占有状況を手動で修正できます。
- RESCAN IMAGES: 登録されているすべてのDockerレジストリからイメージのメタ情報を更新 します。Backend.AIに接続されたDockerレジストリに新しいイメージがプッシュされた場合に 使用できます。
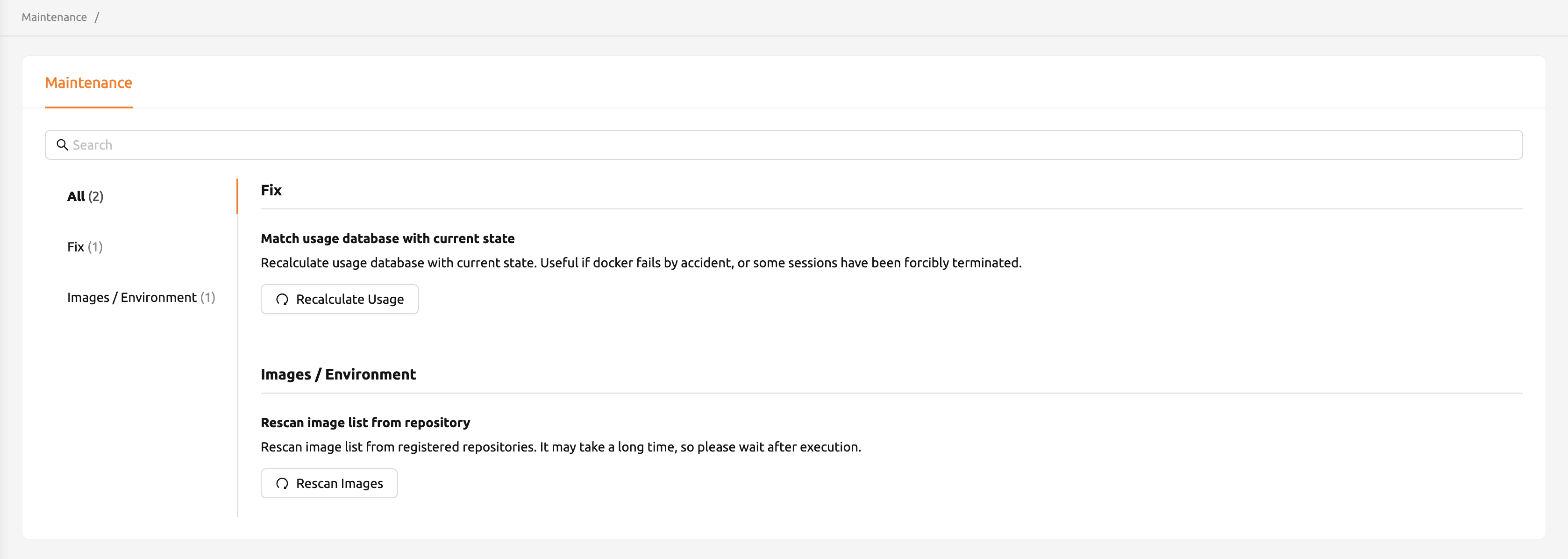
未使用のイメージの削除や定期メンテナンススケジュールの登録など、管理に必要な その他の設定も継続的に追加していきます。
詳細情報#
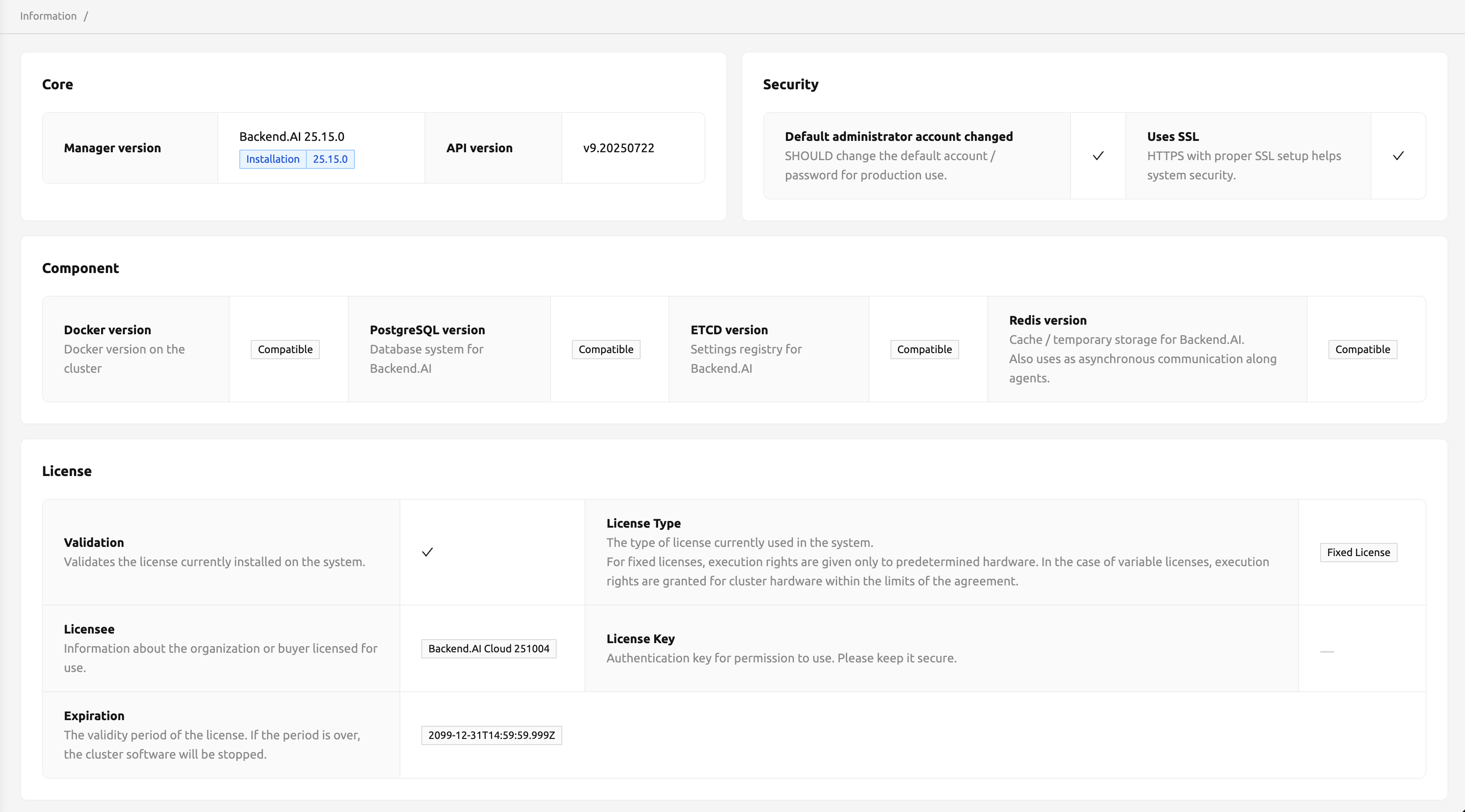
Informationページでは、各機能のいくつかの詳細情報およびステータスを確認できます。 Managerのバージョンおよび API のバージョンを確認するには、Coreパネルをチェックします。 Backend.AIの各コンポーネントに互換性があるかどうかを確認するには、Componentパネルを チェックします。
このページは現在の情報を表示する専用のページです。
RBAC管理#
RBAC(ロールベースアクセス制御)管理では、スーパー管理者がきめ細かい権限を持つロールを定義し、ユーザーに割り当てることができます。Backend.AIシステム全体で特定のユーザーがさまざまなリソースに対して実行できる操作を制御できます。
RBAC管理はスーパー管理者のみが利用でき、Backend.AI Managerバージョン25.4.0以降が必要です。
ロール、権限、ユーザー割り当ての管理の詳細については、RBAC管理ページを参照してください。