モデルサービング#
モデルサービス#
この機能はエンタープライズ版でのみサポートされています。
Backend.AIは、モデル学習フェーズにおける開発環境の構築とリソース管理を支援するだけでなく、 バージョン23.09以降、モデルサービス機能もサポートしています。この機能により、 エンドユーザー(AIベースのモバイルアプリやウェブサービスバックエンドなど)は、 完成したモデルを推論サービスとしてデプロイしたい場合に、推論APIコールを実行できます。
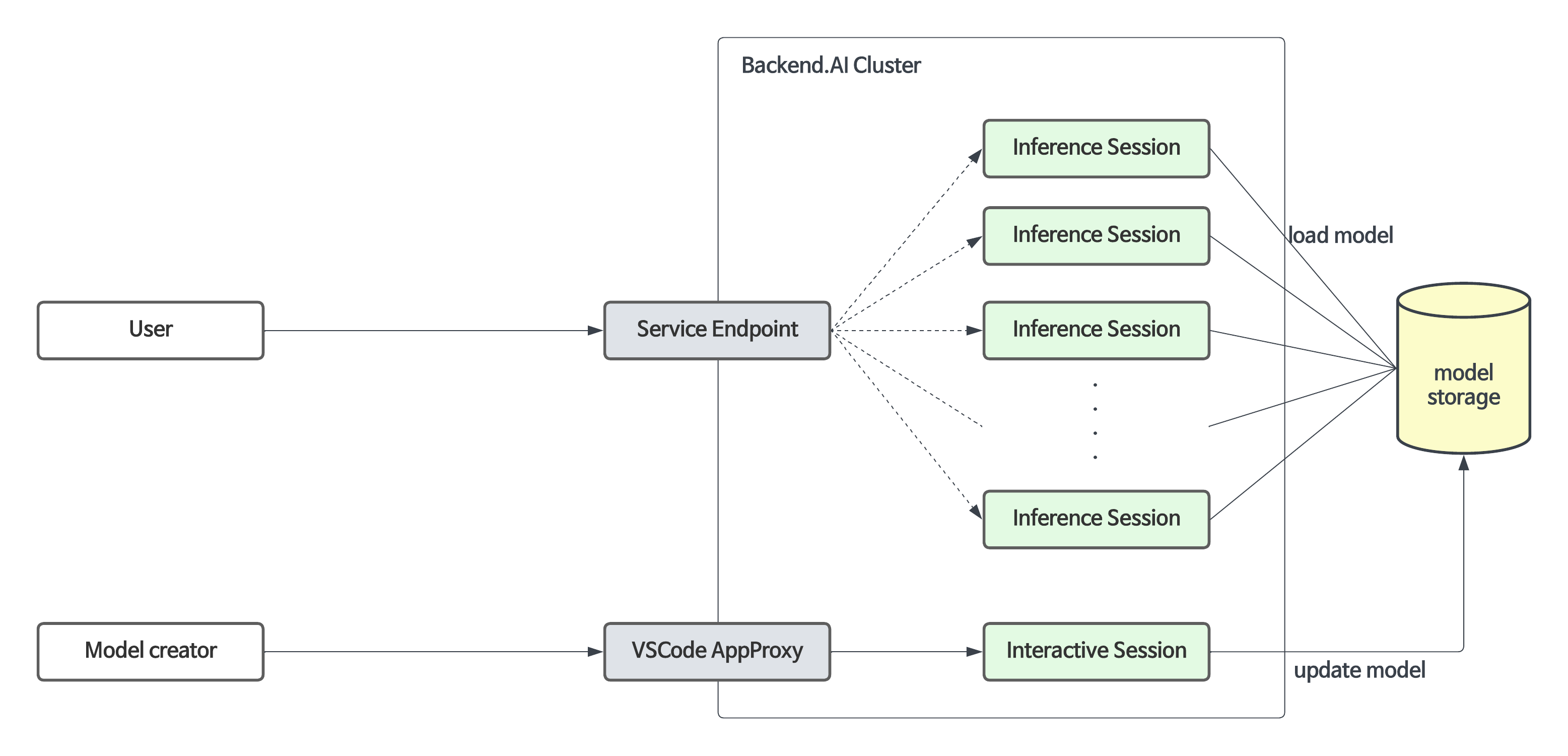
モデルサービスは、既存のトレーニングコンピュートセッションの機能を拡張し、自動メンテナンス、スケーリング、および本番サービスのための永続的なポートとエンドポイントアドレスのマッピングを可能にします。開発者または管理者は、モデルサービスに必要なスケーリングパラメータを指定するだけでよく、コンピュートセッションを手動で作成または削除する必要はありません。
モデルサービスの使用手順ガイド#
バージョン26.4.0以降、別途設定ファイルなしでもモデルサービスを簡単にデプロイできます。
クイックデプロイ(推奨): モデルストアで事前構成されたモデルを閲覧し、デプロイ(Deploy)ボタンをクリックするだけでデプロイできます。
サービスランチャーからのデプロイ: サービングページのStart Serviceボタンをクリックしてサービスランチャーを開き、vLLMやSGLangなどのランタイムバリアントを選択すると、モデル定義ファイルなしでモデルサービスを作成できます。
一般的なワークフローは次のとおりです:
- サービスランチャーを使用してモデルサービスを作成します。
- (モデルサービスが公開されていない場合)トークンを生成します。
- (エンドユーザー向け)サービスエンドポイントにアクセスしてサービスを確認します。
- (必要に応じて)モデルサービスを変更します。
- (必要に応じて)モデルサービスを終了します。
高度な設定: モデル定義ファイルおよびサービス定義ファイルの使用(Customランタイム)
Customランタイムバリアントを使用する場合や、より詳細な制御が必要な場合は、モデル定義ファイルとサービス定義ファイルを作成して使用できます:
- モデル定義ファイルを作成します。
- サービス定義ファイルを作成します。
- 定義ファイルをモデルタイプフォルダーにアップロードします。
- サービスランチャーで
Customランタイムを選択してモデルサービスを作成/検証します。
詳細については、下記のモデル定義ファイルの作成およびサービス定義ファイルの作成セクションを参照してください。
モデル定義ファイルの作成#
24.03以降、モデル定義ファイル名を設定できます。モデル定義ファイルパスで
他の入力フィールドを入力しない場合、システムはmodel-definition.ymlまたは
model-definition.yamlと見なします。
モデル定義ファイルには、推論セッションを自動的に開始、初期化、およびスケーリングするためにBackend.AIシステムで必要な構成情報が含まれています。これは推論サービスエンジンを含むコンテナイメージとは独立して、モデルタイプフォルダーに保存されます。これにより、特定の要件に基づいて異なるモデルをエンジンが提供できるようになり、モデルが変更されるたびに新しいコンテナイメージを構築してデプロイする必要がなくなります。ネットワークストレージからモデル定義とモデルデータをロードすることで、自動スケーリング中にデプロイメントプロセスを簡素化し、最適化できます。
モデル定義ファイルは次の形式に従います:
models:
- name: "simple-http-server"
model_path: "/models"
service:
start_command:
- python
- -m
- http.server
- --directory
- /home/work
- "8000"
port: 8000
health_check:
path: /
interval: 10.0
max_retries: 10
max_wait_time: 15.0
expected_status_code: 200
initial_delay: 60.0モデル定義ファイルのキーと値の説明
「(必須)」表示のないフィールドはオプションです。
name(必須): モデルの名前を定義します。model_path(必須): モデルが定義されているパスを指定します。service: サービスされるファイルに関する情報を整理する項目です (コマンドスクリプトおよびコードを含む)。pre_start_actions:start_commandの前に実行されるアクションです。これらのアクションは、 設定ファイルの作成、ディレクトリのセットアップ、初期化スクリプトの実行などによって環境を準備します。 アクションは定義された順序で順次実行されます。action: 実行するアクションのタイプ。利用可能なアクションタイプとそのパラメータについては 事前開始アクションを参照してください。args: アクション固有のパラメータ。各アクションタイプには異なる必須引数があります。
start_command(必須): モデルサービングで実行されるコマンドを指定します。 文字列または文字列のリストで指定できます。port(必須): モデルサービス用のコンテナポートです(例:8000、8080)。health_check: モデルサービスの定期的なヘルスモニタリングの設定です。 設定すると、システムはサービスが正しく応答しているか自動的に確認し、 異常なインスタンスをトラフィックルーティングから除外します。path(必須): ヘルスチェックリクエスト用のHTTPエンドポイントパスです(例:/health、/v1/health)。interval(デフォルト:10.0): 連続するヘルスチェック間の秒数です。max_retries(デフォルト:10): サービスをUNHEALTHYとしてマークする前に 許容される連続失敗回数です。このしきい値を超えるまでサービスはトラフィックを受け続けます。max_wait_time(デフォルト:15.0): 各ヘルスチェックHTTPリクエストのタイムアウト秒数です。 この時間内に応答がない場合、チェックは失敗とみなされます。expected_status_code(デフォルト:200): 正常な応答を示すHTTPステータスコードです。 一般的な値:200(OK)、204(No Content)。initial_delay(デフォルト:60.0): コンテナ作成後にヘルスチェックを開始するまでの 待機時間(秒)です。モデルのロード、GPUの初期化、サービスのウォームアップに時間を確保します。 大規模モデルの場合はより高い値を設定してください(例:70B+のLLMの場合300.0)。
ヘルスチェック動作の理解
ヘルスチェックシステムは、個々のモデルサービスコンテナを監視し、ヘルスステータスに基づいてトラフィックルーティングを自動的に管理します。
① AppProxy: トラフィックルーティング制御

② Manager: ヘルス状態管理と eviction

内部ヘルスステータス(トラフィックルーティングに使用)は、ユーザーインターフェースに 表示されるステータスと即座に同期されない場合があります。
UNHEALTHYまでの時間:
初期起動時:
initial_delay + interval × (max_retries + 1)デフォルト値の例: 60 + 10 × 11 = 170秒(約3分)
運用中(正常状態後):
interval × (max_retries + 1)デフォルト値の例: 10 × 11 = 110秒(約2分)
Backend.AIモデルサービングでサポートされているサービスアクションの説明
write_file: 指定されたファイル名でファイルを作成し、内容を追加するアクションです。 デフォルトのアクセス権限は644です。arg/filename: ファイル名を指定body: ファイルに追加する内容を指定mode: ファイルのアクセス権限を指定append: ファイルへの内容の上書きまたは追加をTrueまたはFalseで設定
write_tempfile: 一時ファイル名(.py)でファイルを作成し、内容を追加するアクションです。 モードの値が指定されていない場合、デフォルトのアクセス権限は644です。body: ファイルに追加する内容を指定mode: ファイルのアクセス権限を指定
run_command: コマンドを実行した結果が、エラーも含めて以下の形式で返されます (out: コマンド実行の出力、err: コマンド実行中にエラーが発生した場合のエラーメッセージ)args/command: 実行するコマンドを配列として指定(例:python3 -m http.server 8080コマンドは ["python3", "-m", "http.server", "8080"] になります)
mkdir: 入力パスによってディレクトリを作成するアクションですargs/path: ディレクトリを作成するパスを指定
log: 入力メッセージによってログを出力するアクションですargs/message: ログに表示するメッセージを指定debug: デバッグモードの場合はTrue、それ以外はFalseに設定
モデル定義ファイルをモデルタイプフォルダーにアップロード#
モデル定義ファイル(model-definition.yml)をモデルタイプフォルダーにアップロードするには、
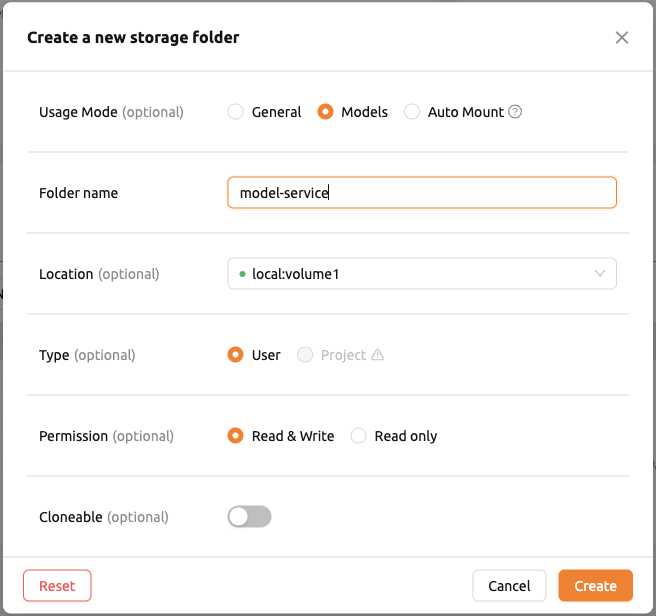
バーチャルフォルダーを作成する必要があります。バーチャルフォルダーを作成する際は、
デフォルトの general タイプではなく model タイプを選択してください。
フォルダーの作成方法については、データページのストレージフォルダーの作成セクションを参照してください。
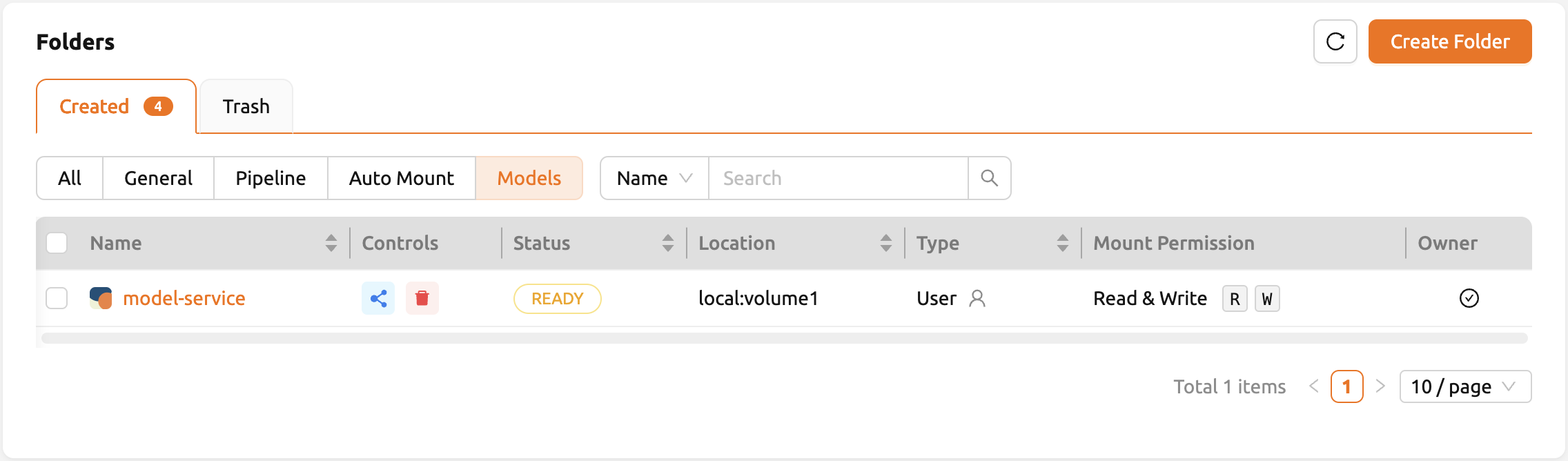
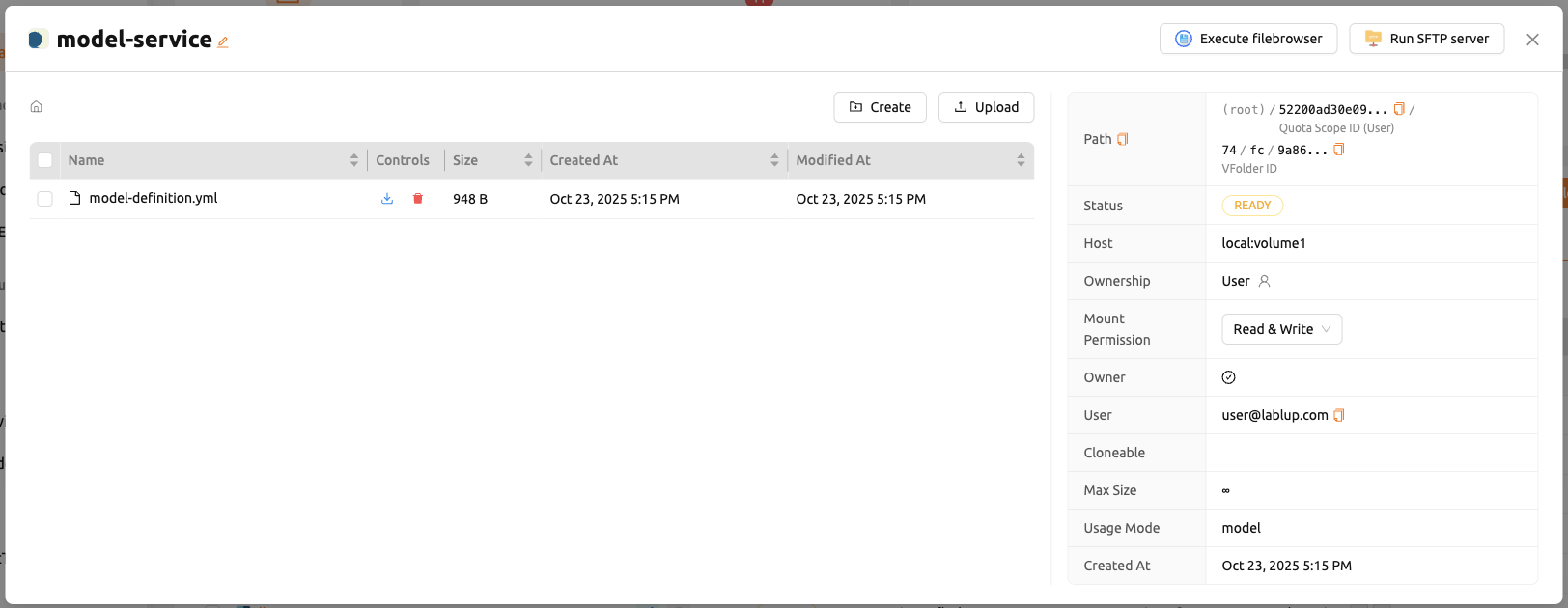
フォルダーを作成した後、データページの「MODELS」タブを選択し、 最近作成したモデルタイプフォルダーアイコンをクリックしてフォルダーエクスプローラーを開き、 モデル定義ファイルをアップロードします。 フォルダーエクスプローラーの使用方法については、フォルダーの探索セクションを参照してください。
サービス定義ファイルの作成#
サービス定義ファイル(service-definition.toml)を使用すると、管理者はモデルサービスに必要なリソース、環境、およびランタイム設定を事前に構成できます。このファイルがモデルフォルダーに存在する場合、システムはサービスを作成する際にこれらの設定をデフォルト値として使用します。
model-definition.yaml と service-definition.toml の両方がモデルフォルダーに存在する必要があり、
これによりモデルストアページで デプロイ(Deploy) ボタンが有効になります。これら 2 つの
ファイルは連携して動作します:モデル定義はモデルと推論サーバーの構成を指定し、サービス
定義はランタイム環境、リソース割り当て、および環境変数を指定します。
サービス定義ファイルは、ランタイムバリアントごとにセクションを整理したTOML形式に従います。各セクションはサービスの特定の側面を構成します:
[vllm.environment]
image = "example.com/model-server:latest"
architecture = "x86_64"
[vllm.resource_slots]
cpu = 1
mem = "8gb"
"cuda.shares" = "0.5"
[vllm.environ]
MODEL_NAME = "example-model-name"サービス定義ファイルのキーと値の説明
[{runtime}.environment]: モデルサービスのコンテナイメージとアーキテクチャを指定します。image(必須): 推論サービスに使用するコンテナイメージのフルパス(例:example.com/model-server:latest)。architecture(必須): コンテナイメージのCPUアーキテクチャ(例:x86_64、aarch64)。
[{runtime}.resource_slots]: モデルサービスに割り当てるコンピュートリソースを定義します。cpu: 割り当てるCPUコアの数(例:1、2、4)。mem: 割り当てるメモリ量。単位接尾辞をサポート(例:"8gb"、"16gb")。"cuda.shares": 割り当てる分割GPU(fGPU)シェア(例:"0.5"、"1.0")。キーにドットが含まれるため、この値は引用符で囲まれています。
[{runtime}.environ]: 推論サービスコンテナに渡される環境変数を設定します。- ランタイムに必要な環境変数を定義できます。例えば、
MODEL_NAMEはどのモデルをロードするかを指定するために一般的に使用されます。
- ランタイムに必要な環境変数を定義できます。例えば、
各セクションヘッダーの {runtime} プレフィックスは、ランタイムバリアント名
(例:vllm、nim、custom)に対応します。システムは、サービスを作成する際に
選択されたランタイムバリアントとこのプレフィックスを照合します。
デプロイ(Deploy) ボタンを使用してモデルストアからサービスを作成すると、
service-definition.toml の設定が自動的に適用されます。後でリソース割り当てを調整する
必要がある場合は、モデルサービングページを通じてサービスを変更できます。
サービングページの概要#
サービングページには、現在のプロジェクト内のすべてのモデルサービスエンドポイントの一覧が表示されます。サイドバーメニューのモデルサービスをクリックしてアクセスできます。
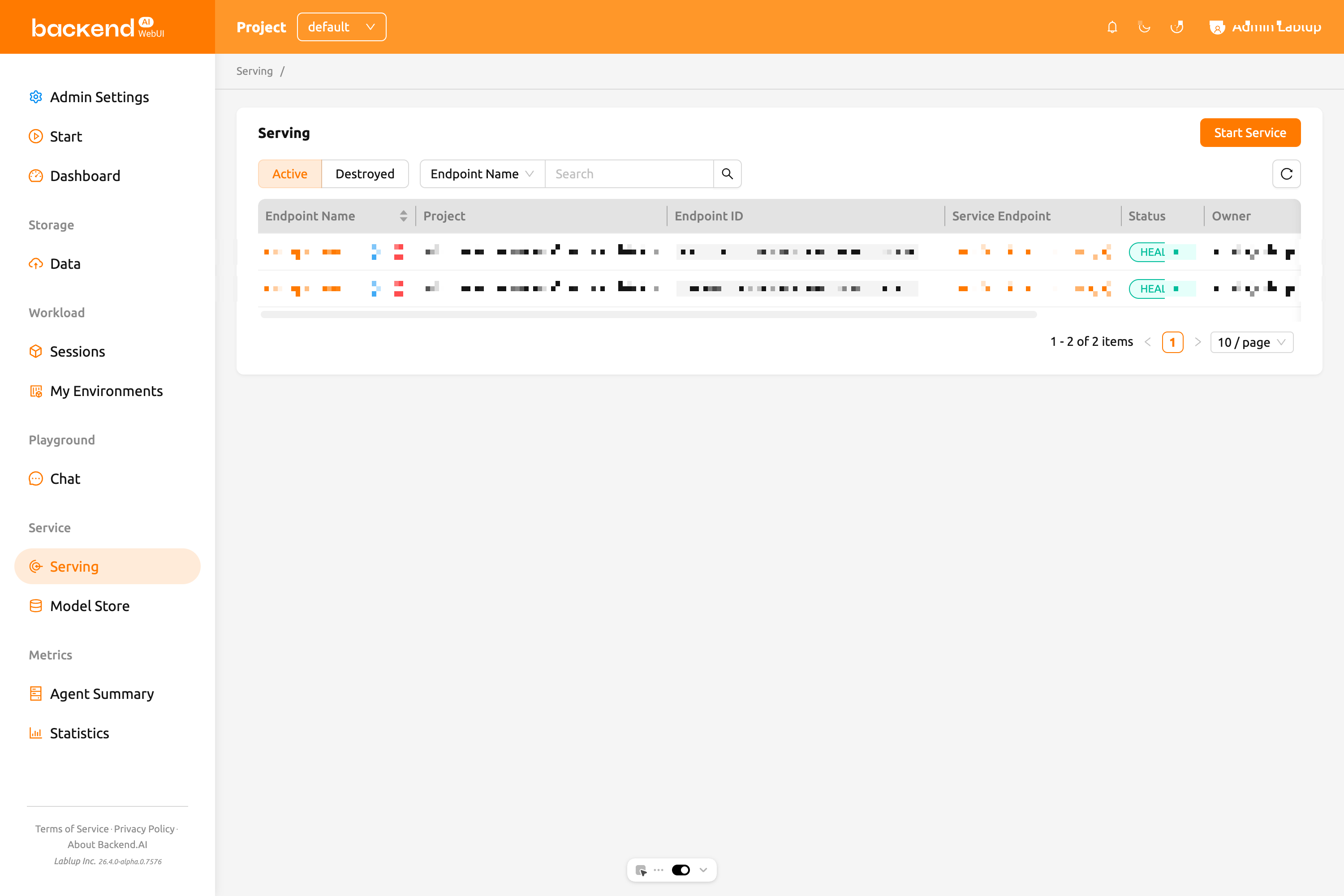
ページ上部で、ライフサイクルステージ別にエンドポイントをフィルタリングできます:
- Active: 現在実行中または作成中のエンドポイントを表示します。これがデフォルトビューです。
- Destroyed: 終了したエンドポイントを表示します。
また、プロパティフィルターバーを使用して、エンドポイント名、サービスエンドポイントURL、またはオーナー(管理者およびスーパー管理者に提供)でエンドポイントを検索できます。
Start Serviceボタンをクリックしてサービスランチャーを開き、新しいモデルサービスを作成します。
モデルサービスの作成#
サービスランチャー#
サービングページでStart Serviceボタンをクリックしてサービスランチャーを開きます。
サービス名と基本設定#
まず、サービス名を入力します。以下のフィールドが利用可能です:
- サービス名: エンドポイントを区別する一意の名前です。
- アプリを外部公開 (Open To Public): 別途トークンなしでモデルサービスにアクセスできるようにします。デフォルトでは無効です。
- マウントするモデルストレージフォルダー: モデルファイルを含むストレージフォルダーを選択します。
- 推論ランタイム・バリアント: モデルサービスのランタイムバリアントを選択します。利用可能なバリアントはバックエンドから動的にロードされ、インストールに応じて
vLLM、SGLang、NVIDIA NIM、Modular MAX、Customなどが含まれます。 - 実行環境 / バージョン: モデルサービスの実行環境を設定します。ランタイムバリアントを選択すると環境イメージが自動的にフィルタリングされます。
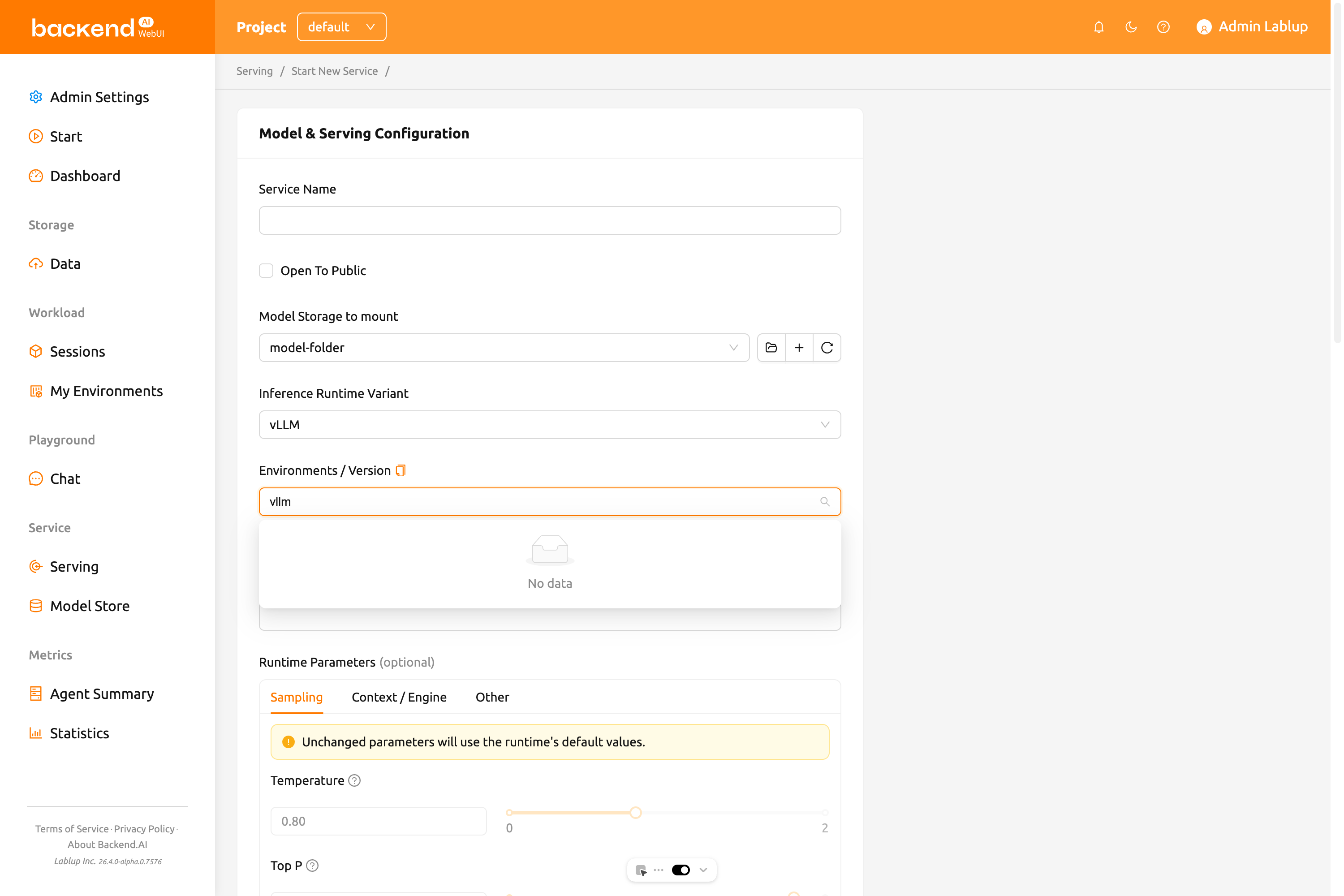
vLLM、SGLang、NVIDIA NIM、Modular MAXなどのランタイムバリアントを選択すると、モデルフォルダーにmodel-definitionファイルを設定する必要はありません。選択されたバリアントに基づいて、システムがモデル構成を自動的に処理します。

モデル定義モード(Customランタイム専用)#
Customランタイムバリアントを選択すると、モデルサービスを定義する2つのモードから選択できます:
コマンド入力モード#
コマンドを入力を選択して、CLIコマンドを直接貼り付けることができます。例えば:
vllm serve /models/my-model --tp 2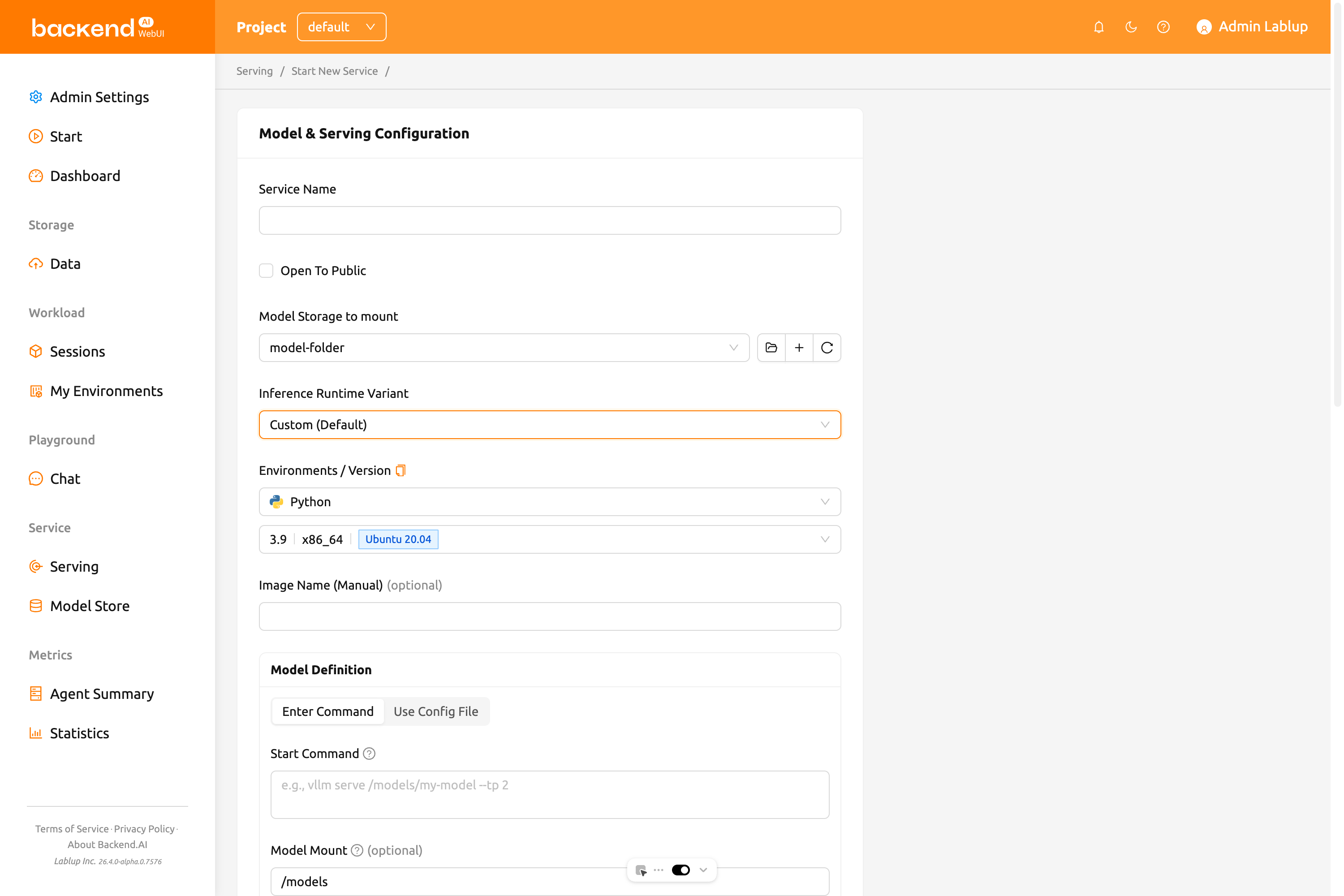
システムが自動的にコマンドを解析し、以下のフィールドを入力します:
- 開始コマンド: モデルサービングで実行されるコマンドを直接入力します。
- モデルマウント: コンテナ内でモデルストレージフォルダーがマウントされるパスです(デフォルト
/models)。 - Port: コマンドから自動検出されます(デフォルト
8000)。モデルサービングプロセスがリッスンするポート番号です。 - ヘルスチェックURL: コマンドから自動検出されます(デフォルト
/health)。サービスのヘルスチェック時に呼び出されるHTTPエンドポイントパスです。 - 初期遅延時間: サービス起動後、最初のヘルスチェックを行うまで待機する秒数です(デフォルト
60.0)。 - 最大再試行回数: サービスが失敗と判断されるまでのヘルスチェックの最大試行回数です(デフォルト
10)。
コマンドがマルチGPU使用を示唆している場合(例:--tp 2)、正しい数のGPU
リソースを割り当てるのに役立つGPUヒントが表示されます。
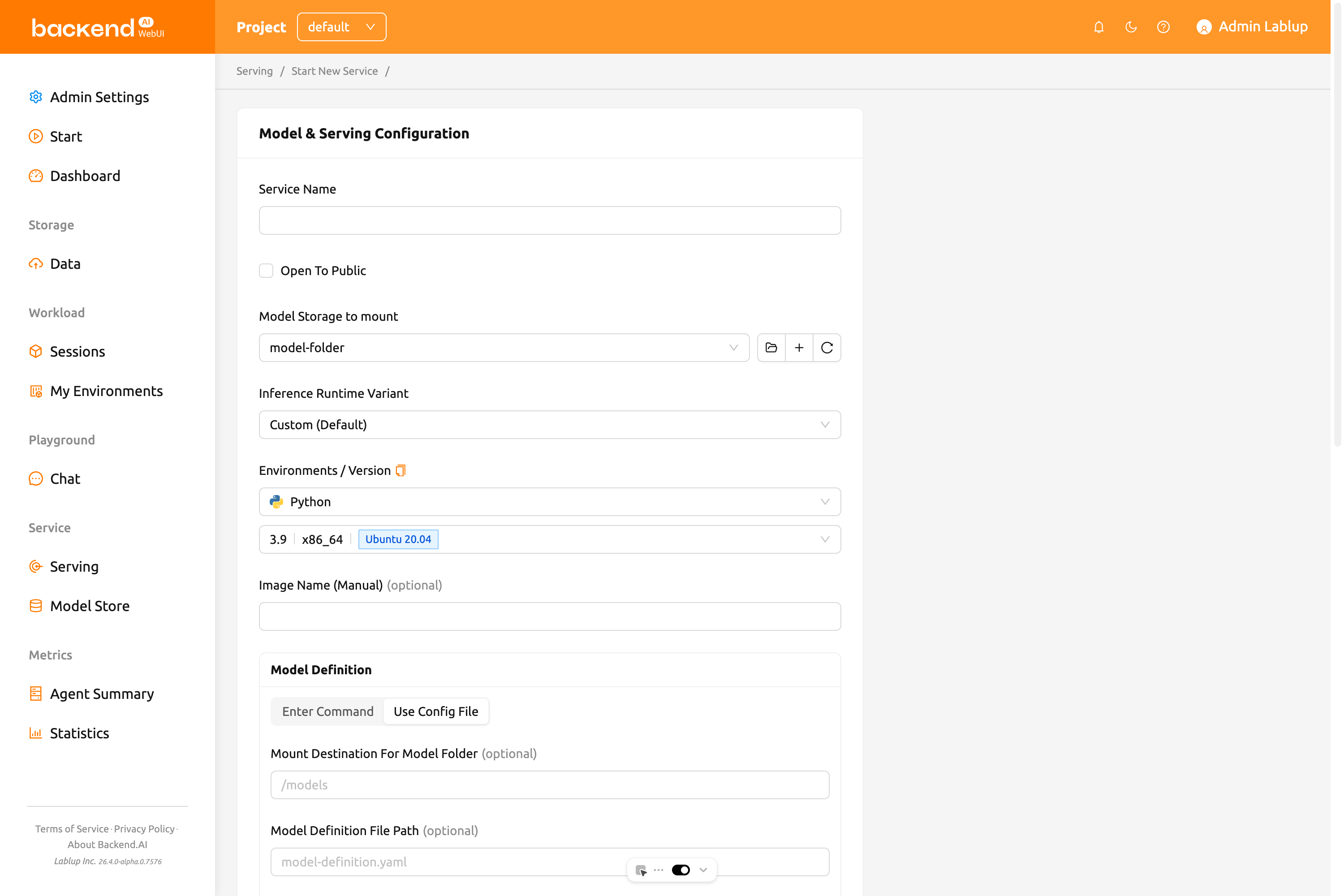
設定ファイル使用モード#
設定ファイルを使用を選択して、従来のmodel-definition.yamlアプローチを使用します。このモードでは以下を設定できます:
- モデルフォルダーのマウント先: セッションでモデルストレージがマウントされるパスです。デフォルト値は
/modelsです。 - モデル定義ファイルパス: アップロードしたモデル定義ファイルのパスです。デフォルト値は
model-definition.yamlです。 - 追加マウント: 追加のストレージフォルダーをマウントできます。追加のモデルフォルダーではなく、一般/データ使用モードのフォルダーのみをマウントできることに注意してください。
ランタイムパラメータ(vLLM / SGLang)#
vLLMまたはSGLangランタイムバリアントを選択すると、ランタイムパラメータセクションが表示されます。このセクションでは、設定ファイルを手動で編集することなく、モデルサービングの動作を微調整できます。
パラメータはタブで区切られたカテゴリ別に構成されます。タブ一覧はランタイムバリアントによって異なります。
変更されていないパラメータはランタイムのデフォルト値を使用します。
vLLMランタイムパラメータ
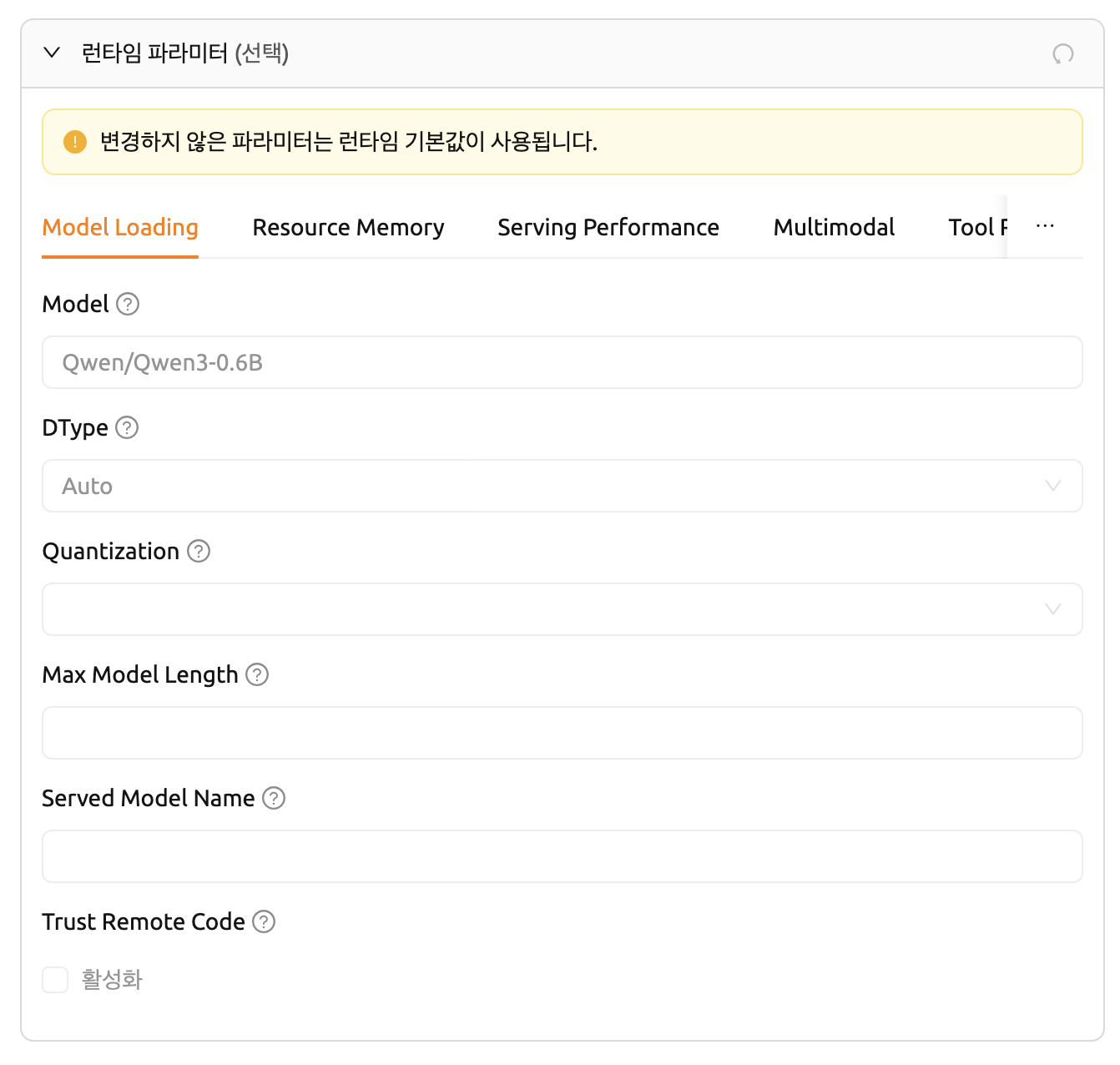
vLLMは次のタブを提供します:Model Loading、Resource Memory、Serving Performance、Multimodal、Tool Reasoning など。
Model Loadingタブの主要フィールド:
- Model: 使用するモデルの名前またはパスです。
- DType: モデルの重みと計算のデータ型です(例:
Auto、float16、bfloat16)。 - Quantization: モデルの量子化方式です(例:
awq、gptq、fp8)。 - Max Model Length: モデルが処理できる最大コンテキスト長(トークン数)です。
- Served Model Name: APIエンドポイントで公開するモデル名です。
- Trust Remote Code: モデルリポジトリのカスタムモデルコードの実行を許可します。
SGLangランタイムパラメータ
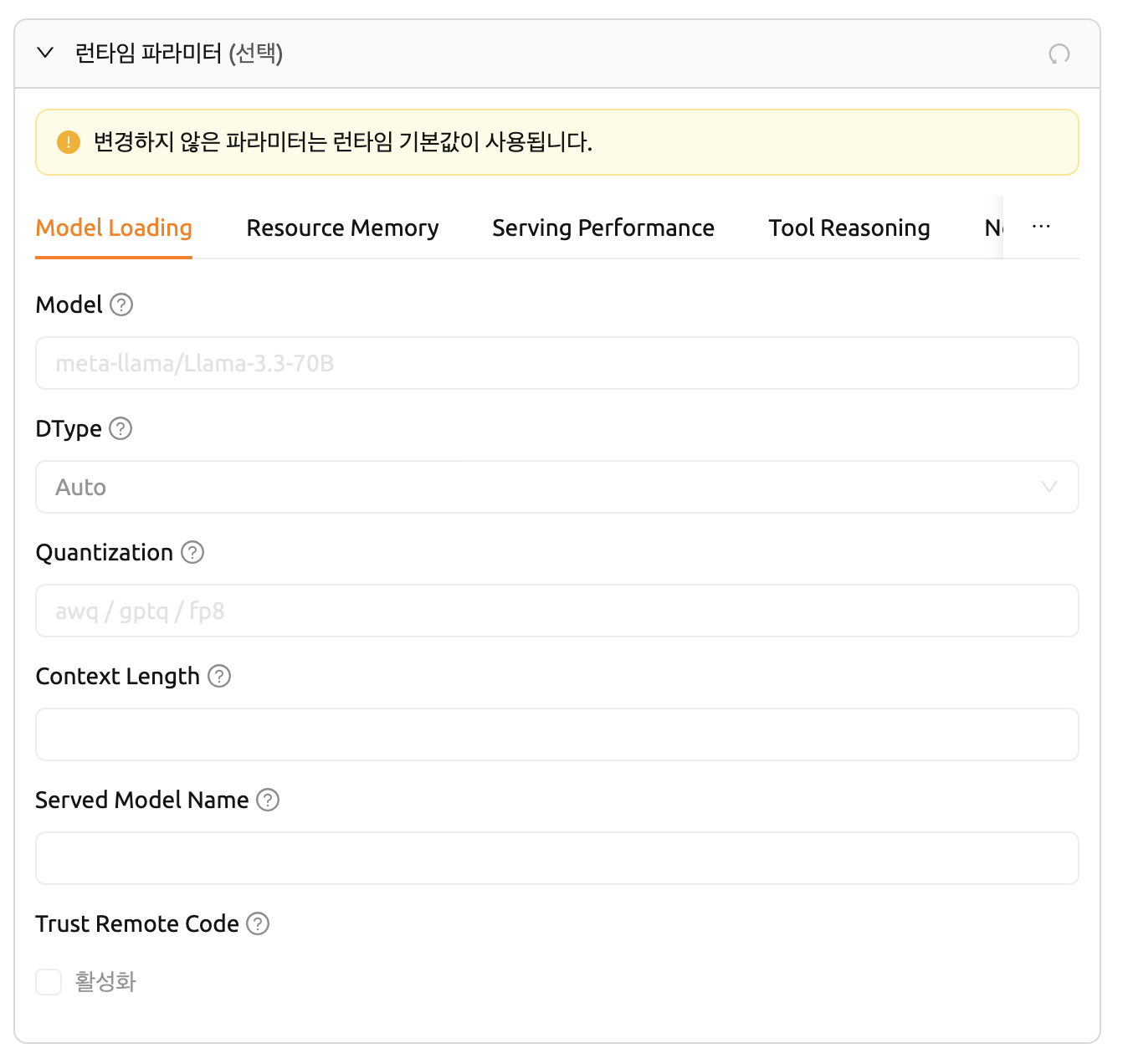
SGLangは次のタブを提供します:Model Loading、Resource Memory、Serving Performance、Tool Reasoning など。
Model Loadingタブの主要フィールド:
- Model: 使用するモデルの名前またはパスです。
- DType: モデルの重みと計算のデータ型です(例:
Auto、float16、bfloat16)。 - Quantization: モデルの量子化方式です(例:
awq、gptq、fp8)。 - Context Length: モデルが処理できる最大コンテキスト長です。
- Served Model Name: APIエンドポイントで公開するモデル名です。
- Trust Remote Code: モデルリポジトリのカスタムモデルコードの実行を許可します。
ランタイムパラメータに加えて、vLLM および SGLang ランタイムバリアントは、サービスランチャーの環境変数セクションで特定の環境変数を提供します:
- vLLM:
BACKEND_MODEL_NAME、VLLM_QUANTIZATION、VLLM_TP_SIZE(テンソル並列化)、VLLM_PP_SIZE(パイプライン並列化)、VLLM_EXTRA_ARGS(追加CLIアーギュメント) - SGLang:
BACKEND_MODEL_NAME、SGLANG_QUANTIZATION、SGLANG_TP_SIZE(テンソル並列化)、SGLANG_PP_SIZE(パイプライン並列化)、SGLANG_EXTRA_ARGS(追加CLIアーギュメント)
これらの環境変数は、ランタイムパラメータセクションではなく、ランチャーの環境変数セクションに 表示されます。各ランタイムバリアント固有の追加構成オプションを提供します。
ランタイムバリアント比較#
次の表は、3つの主要なランタイムバリアント間の主な違いをまとめたものです:
| 機能 | Custom | vLLM | SGLang |
|---|---|---|---|
| ランタイムパラメータセクション | なし | あり | あり |
| コマンド入力 / 設定ファイル使用切替 | あり | なし | なし |
| 環境変数プリセット | 手動入力のみ | VLLM_* プリセット |
SGLANG_* プリセット |
| 編集時のフォーム事前入力 | あり(最新リビジョン基準) | なし | なし |
環境とリソース#
レプリカ数を設定し、環境とリソースグループを選択します。
- レプリカ数: サービスに対して維持するルーティングセッションの数を決定します。この値を変更すると、マネージャーはレプリカセッションを作成または終了します。
- 環境 / バージョン: モデルサービスの実行環境を設定します。vLLMなどのランタイムバリアントを選択すると、環境イメージが自動的にフィルタリングされ、関連するイメージが表示されます。
- リソースプリセット: 割り当てるリソースの量を選択します。リソースにはCPU、RAM、GPUが含まれます。
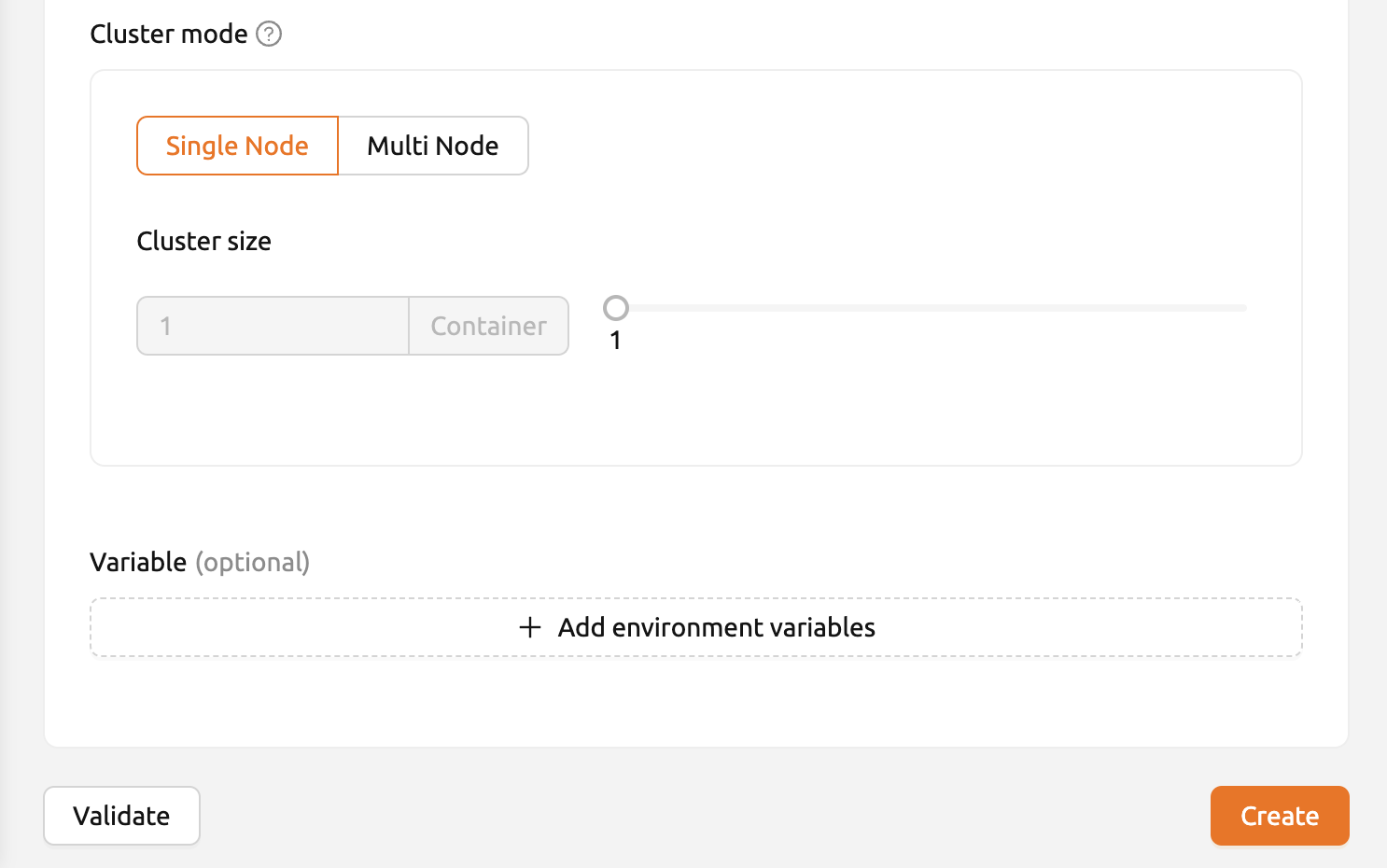
クラスターモードと環境変数#
- シングルノード: セッションを実行する際、管理ノードとワーカーノードが単一の物理ノードまたは仮想マシンに配置されます。
- マルチノード: 1つの管理ノードと1つ以上のワーカーノードが複数の物理ノードまたは仮想マシンに分割されます。
- 変数: モデルサービスを開始する際に環境変数を設定できます。ランタイムバリアントを使用してモデルサービスを作成する場合に便利です。
サービスの検証#
モデルサービスを作成する前に、Backend.AIは実行が可能かどうかをチェックする検証機能をサポートしています。
サービスランチャーの左下にあるValidateボタンをクリックすると、
検証イベントをリスニングするための新しいポップアップが表示されます。ポップアップモーダルでは、
コンテナログを通じてステータスを確認できます。結果がFinishedに設定されると、
検証チェックは完了です。
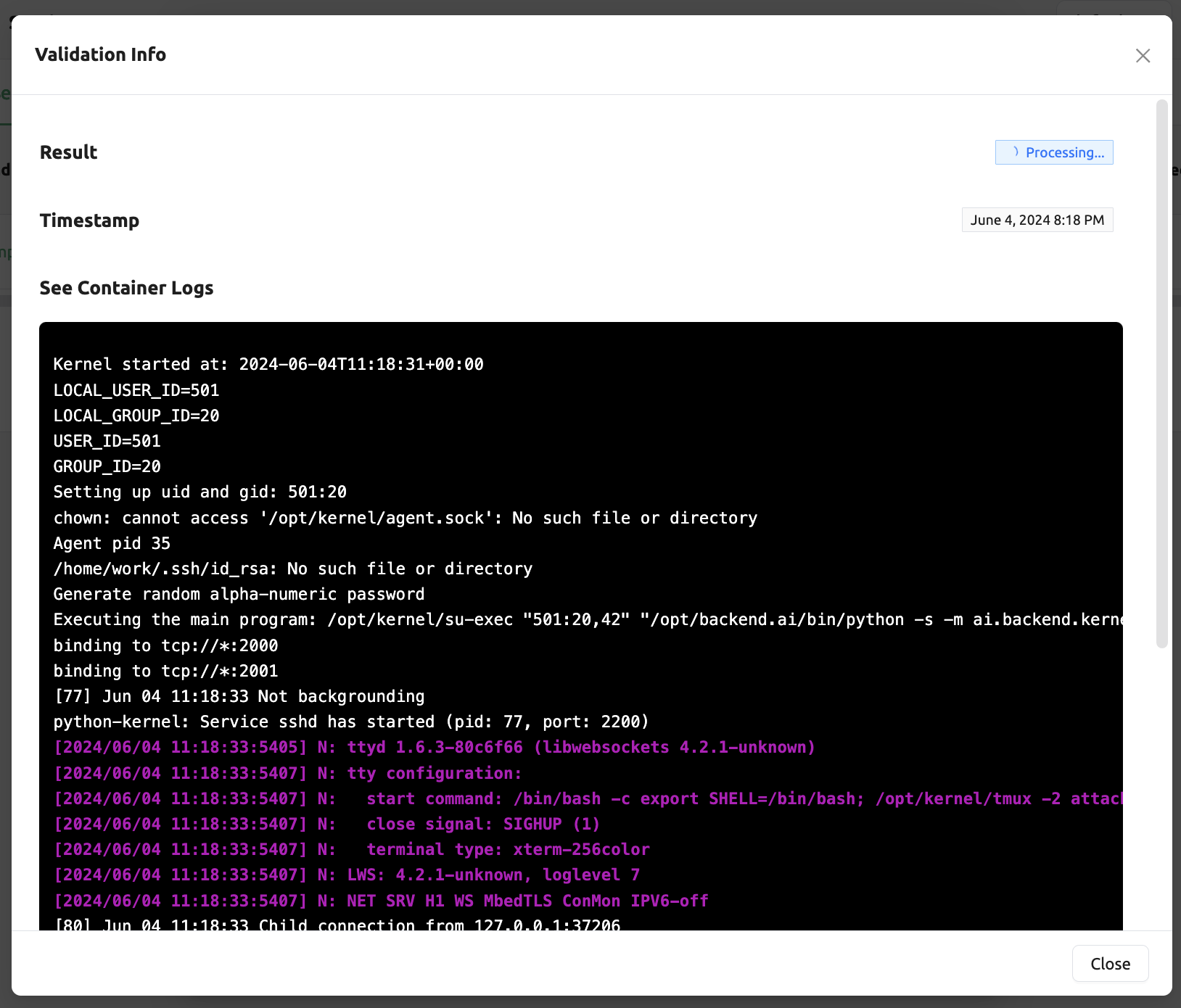
結果が Finished であっても、実行が正常に完了したことを保証するものではありません。
代わりに、コンテナログを確認してください。
モデルサービス作成の失敗への対処#
モデルサービスのステータスが UNHEALTHY のままの場合、
モデルサービスが正しく実行できないことを示しています。
作成失敗の一般的な理由とその解決策は次のとおりです:
モデルサービス作成時のルーティングに対して割り当てられたリソースが不十分
- 解決策: 問題のあるサービスを終了し、以前の設定よりも十分なリソースを 割り当てて再作成してください。
モデル定義ファイル(
model-definition.yml)の形式が正しくない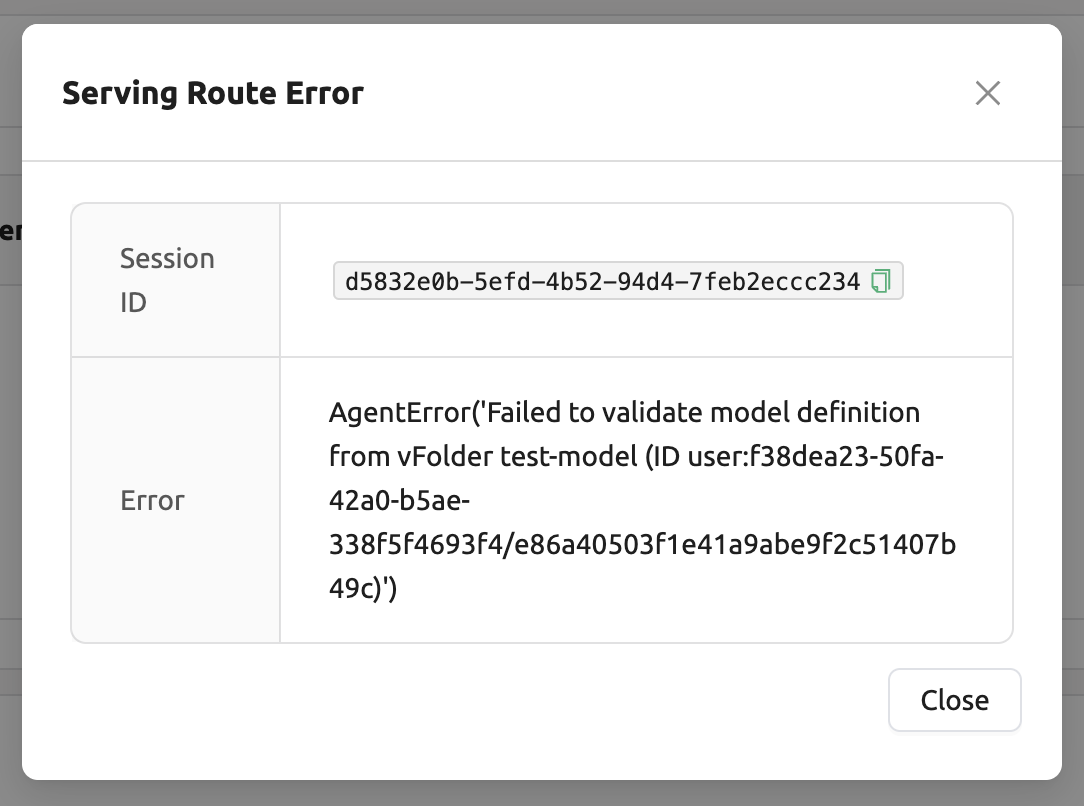
図 15.18 - 解決策: モデル定義ファイルの形式を確認し、
キー値ペアが正しくない場合は、それらを修正して保存された場所のファイルを上書きしてください。
その後、
Clear error and retryボタンをクリックして、ルート情報テーブルに スタックされたすべてのエラーを削除し、モデルサービスのルーティングが正しく設定されていることを確認してください。
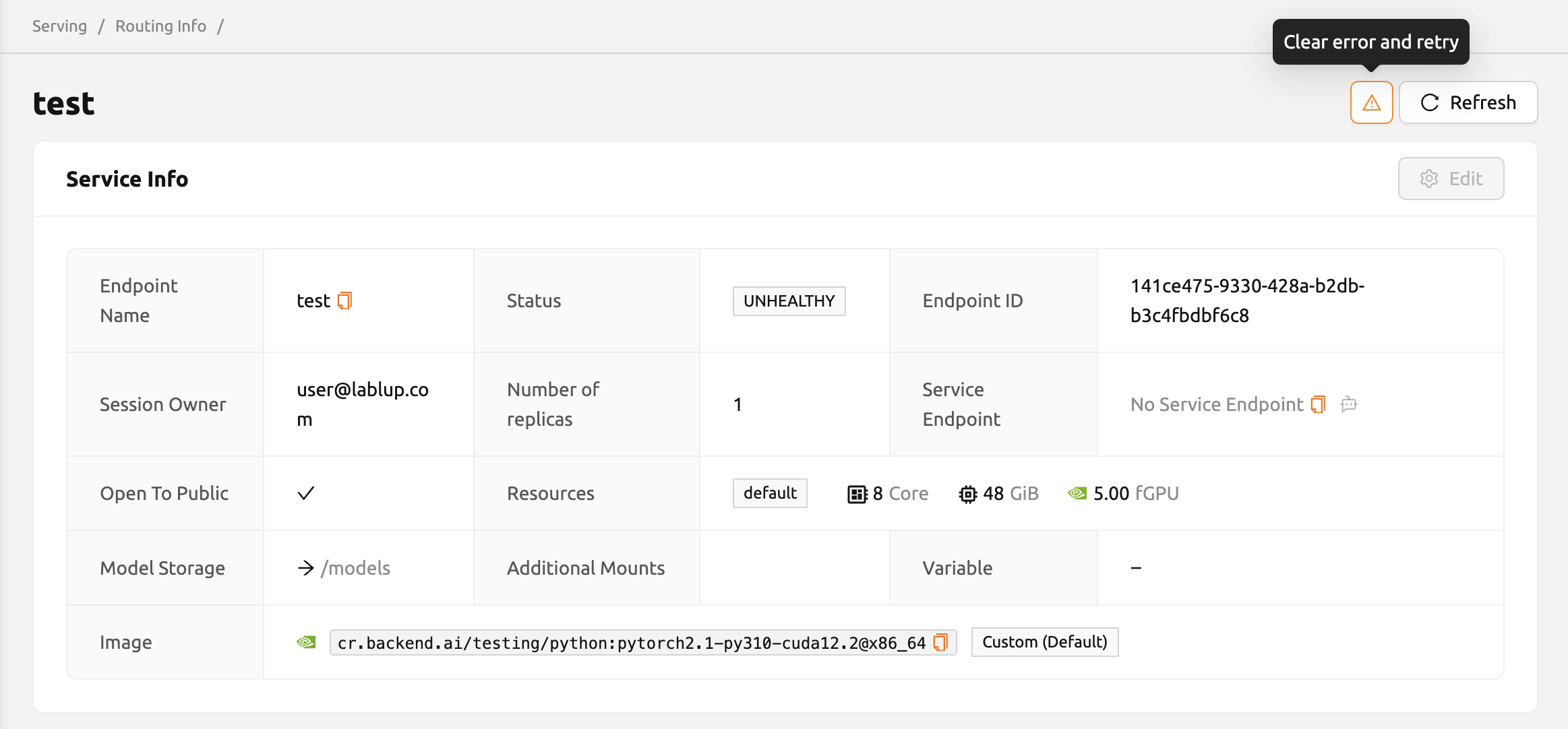
図 15.19 - 解決策: モデル定義ファイルの形式を確認し、
キー値ペアが正しくない場合は、それらを修正して保存された場所のファイルを上書きしてください。
その後、
エンドポイント詳細ページ#
サービング一覧でエンドポイント名をクリックすると、モデルサービスの詳細情報を表示できます。
サービス情報#
サービス情報カードには以下の詳細が表示されます:
- エンドポイント名とステータス
- エンドポイントIDとセッションオーナー
- レプリカ数
- サービスエンドポイント: モデルサービスにアクセスするためのURLです。LLMサービスの場合、
LLM Chat Testボタンが利用可能です。 - Open To Public: サービスが公開アクセス可能かどうかです。
- リソース: リソースグループおよび割り当てられたCPU/メモリ/GPUです。
- モデルストレージ: マウントされたモデルストレージフォルダーとマウント先です。
- 追加マウント: マウントされた追加のストレージフォルダーです。
- 環境変数: コードブロックとして表示されます。
- イメージ: サービスに使用されるコンテナイメージです。
サービス情報カードのEditボタンをクリックすると、更新ランチャーに移動してサービス設定を変更できます。
エンドポイント詳細ページでは、サービスの現在の状態に応じて、ページ上部にコンテキストに応じたアラートバナーが表示されます:
- サービスを準備しています: サービスがデプロイ中またはステータス遷移中に表示されます。サービスがまだリクエストを処理する準備ができていないことを示します。

- サービスの準備が整いました: サービスのステータスが
HEALTHYの場合に表示されます。このバナーには、LLMチャットテストインターフェースへのショートカットを提供する チャットを開始 ボタンが含まれています。

- このモデルサービスは別のプロジェクトに属しています: エンドポイントが現在選択されているプロジェクトとは異なるプロジェクトに属している場合に表示されます。このアラートが表示されている間は Edit ボタンが無効になります。アラート内の プロジェクトを切り替える ボタンをクリックして正しいプロジェクトに切り替えてください。
リビジョン情報#
リビジョン情報カードは、サーバーが Model Card v2 をサポートしている場合 (Backend.AI バージョン 26.4.0 以降)に利用可能です。
エンドポイント詳細ページのリビジョン情報カードは、最新リビジョン — 次に適用される予定のリビジョンの構成を表示します。これは、現在サービスで実行されているリビジョンとは異なる場合があります。
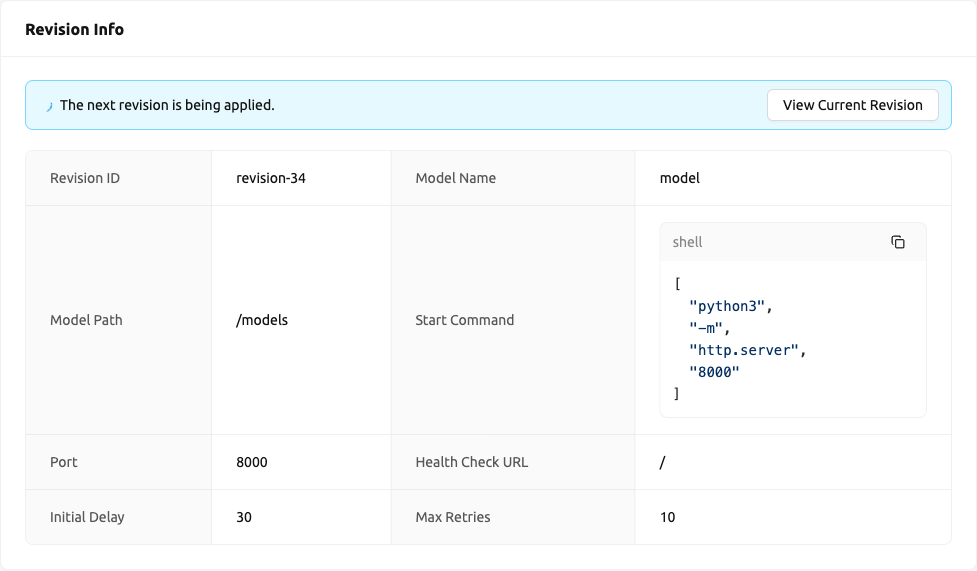
カードには以下のフィールドが表示されます:
- Revision ID: 最新リビジョンの識別子です。
- Model Name: モデル定義で定義されたモデル名です。
- Model Path: モデルがマウントされているパスです。
- Start Command: 推論サーバーの起動に使用されるコマンドです。
- Port: モデルサービス用のコンテナポートです。
- Health Check Path: ヘルスチェック用のHTTPエンドポイントパスです。
- Initial Delay: 最初のヘルスチェックまでの待機秒数です。
- Max Retries: 許容される連続ヘルスチェック失敗の最大回数です。
リビジョン不一致の状態#
新しいリビジョンがキューに追加されたが、サービスがまだ前のリビジョンで実行されている場合、リビジョン情報カードに 「次のリビジョンを適用中です。」 アラートが表示されます。これは、カードに表示されている最新リビジョンの値が、現在実行中の構成とまだ一致していないことを示します。

現在のリビジョンを表示 ボタンをクリックすると、現在実行中のリビジョンのモデル定義を表示するモーダルが開きます。これにより、今後のリビジョン(リビジョン情報カードに表示)と現在アクティブなリビジョン(モーダルに表示)を比較できます。
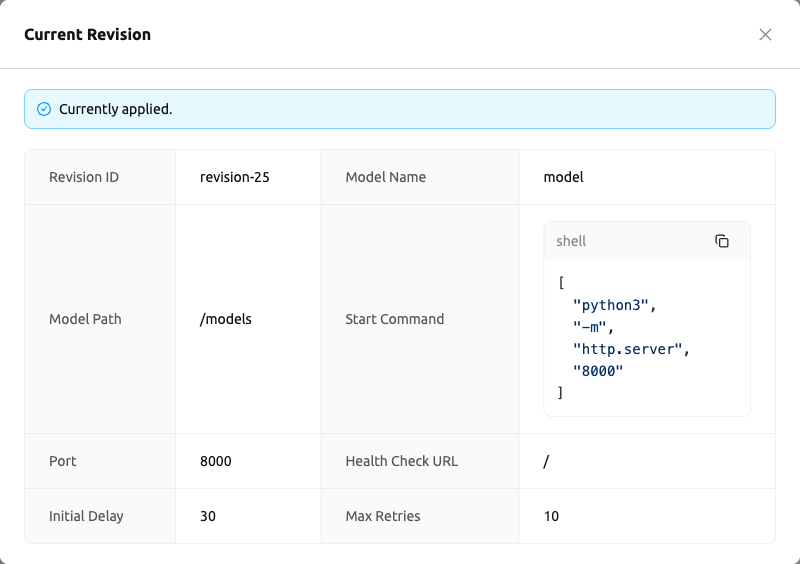
まとめると:リビジョン情報カードは常に最新/今後のリビジョン値を表示し、 現在のリビジョンを表示モーダルは現在実行中のリビジョン値を表示します。
リビジョンを使用した編集動作(Customバリアント専用)#
Custom ランタイムバリアントを使用しているサービスで、サービス情報パネルの Edit ボタンをクリックすると、サービスランチャーフォームに最新リビジョンのモデル定義値がデフォルト値として事前入力されます。これにより、すべてのフィールドを再入力することなく、設定を段階的に調整できます。
このモデル定義値の事前入力動作は、Custom ランタイムバリアントにのみ適用されます。
vLLM および SGLang バリアントはモデル定義フィールドを使用しません。代わりに、
フレームワーク固有の設定用の ランタイムパラメータ セクション(inference_runtime_config)を提供します。
モデル定義とランタイムパラメータは、リビジョン内に別々に保存される独立した概念です。
自動スケーリングルール#
自動スケーリングルール(Auto Scaling Rules)は、ライブメトリックに基づいてモデルサービスのレプリカ数を自動的に増減します。これにより、使用率が低いときはリソースを節約し、使用率が高いときはリクエストの遅延や失敗を防ぎます。
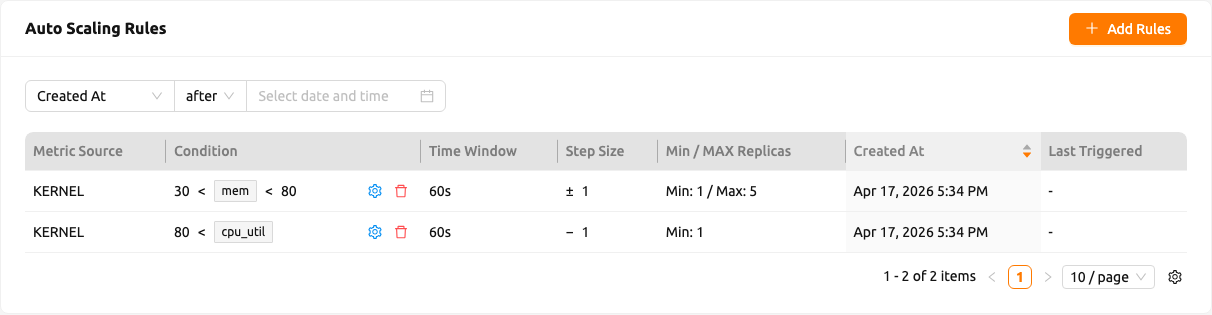
ルール一覧には以下が含まれます:
- 作成された時間(Created At)および最後にトリガーされました(Last Triggered)の日時範囲でルールをフィルタリングできるプロパティフィルターバー。
- サーバーサイドのページネーション。
- メトリックソース(Metric Source)、コンディション(Condition)、クールダウン秒(Cooldown Sec.)、ステップサイズ(Step Size)、min / max レプリカ(Min / Max Replicas)、作成された時間(Created At)、最後にトリガーされました(Last Triggered)の列。ステップサイズ列は、設定されたしきい値から導出される方向に基づいて
+、−、±を自動的に表示するため、Scale OutまたはScale Inを明示的に選択する必要はなくなりました。 - 各行のコンディションサマリーの横に表示される行ごとの編集および削除アイコン。
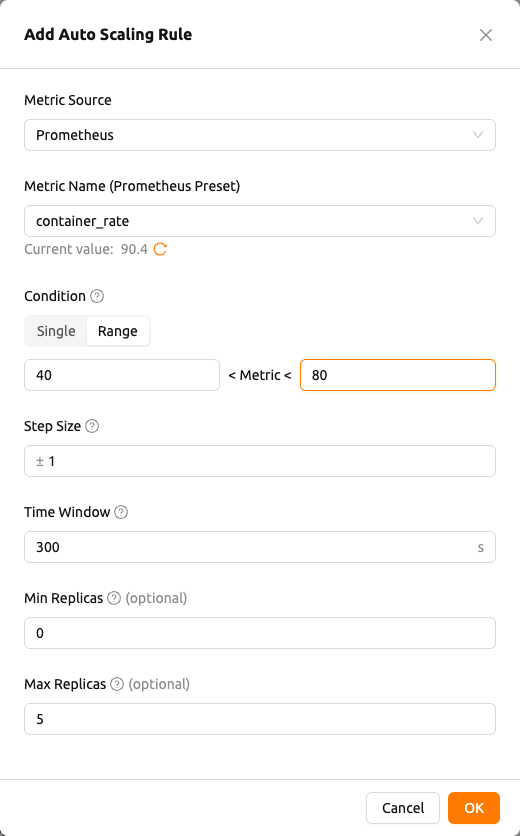
Add Rules ボタンをクリックすると、自動スケーリングルールを追加します エディターが開きます。既存のルールを変更するには、その行の編集アイコンをクリックします。ルールの値が事前に入力された状態で 自動スケーリングルールを編集します エディターが開きます。エディターには次のフィールドが順番に含まれます:
メトリックソース(Metric Source):
Kernel、Inference Framework、Prometheusのいずれかを選択します。メトリック名(Metric Name):
KernelおよびInference Frameworkの場合、メトリック名を入力します。Kernelでは、cpu_util、mem、net_rx、net_txなどの一般的なメトリックがオートコンプリートの候補として提案され、カスタム名を自由に入力することもできます。メトリック名プリセット(Metric Name (Prometheus Preset)): メトリックソースが
Prometheusの場合のみ表示されます。ドロップダウンからプリセットを選択すると、プリセットのメトリック名、クエリテンプレート、および(定義されている場合)クールダウン秒(Cooldown Sec.)が自動的に入力されます。セレクタの下にある現在の値(Current value)プレビューは、プリセットが返す最新の値を更新ボタンとともに表示します。複数のシリーズが返される場合、プレビューにはシリーズの件数と最新の値が表示されます。利用可能なデータがない場合は、データがありません(No data available)と表示されます。コンディション(Condition): スケーリング方向を選択するセグメントコントロールです。3 つのオプションがあります。
- Scale In: メトリックがしきい値を下回るとレプリカを減らします。
Metric < [しきい値]の条件を設定します。 - Scale Out: メトリックがしきい値を上回るとレプリカを増やします。
Metric > [しきい値]の条件を設定します。 - Scale In & Out: メトリックが設定した範囲のどちら側を超えたかに応じて、自動的に縮小または拡張します。
Metric < Min ThresholdまたはMetric > Max Thresholdの条件を設定します。
- Scale In: メトリックがしきい値を下回るとレプリカを減らします。

ステップサイズ(Step Size): スケーリングイベントごとに追加または削除するレプリカ数を指定する正の整数です。選択したコンディション(Scale In / Scale Out / Scale In & Out)に応じて
-、+、±の符号が自動的に表示されます。- 最小しきい値のみ設定:
[metric] < [minThreshold]条件になるとスケールイン(Scale In)されます(メトリックがしきい値を下回るとレプリカが減少します)。 - 最大しきい値のみ設定:
[metric] > [maxThreshold]条件になるとスケールアウト(Scale Out)されます(メトリックがしきい値を上回るとレプリカが増加します)。 - 両方設定: メトリックがどちらの境界を超えたかに応じてスケールインまたはスケールアウトされます(
[minThreshold] < [metric] < [maxThreshold]が正常稼働範囲です)。
- 最小しきい値のみ設定:
クールダウン秒(Cooldown Sec.): スケーリングイベント後、次の評価まで待機する時間(秒単位)です。
最小レプリカ(Min Replicas)および最大レプリカ(Max Replicas): 自動スケーリングがレプリカ数に対して強制する下限と上限です。自動スケーリングは、レプリカ数を最小レプリカより下げたり、最大レプリカより上げたりすることはありません。
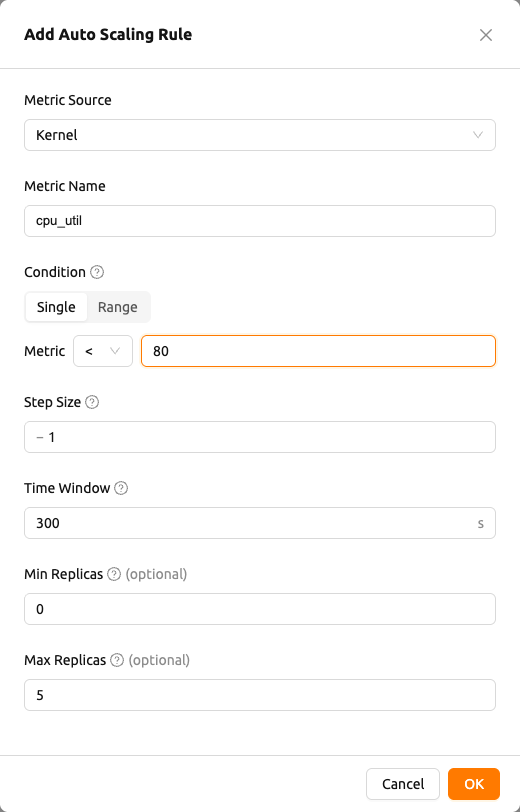
メトリックソース(Metric Source)が Prometheus に設定されている場合、エディターにはプリセットセレクタとライブの現在の値(Current value)プレビューが表示されます。
トークンの生成#
モデルサービスが正常に実行されると、ステータスが
HEALTHYに設定されます。サービング一覧で対応するエンドポイント名をクリックして、
詳細情報を表示できます。ルーティング情報でサービスエンドポイントを確認できます。
サービス作成時にOpen To Publicオプションが
有効になっている場合、エンドポイントは別途トークンなしで
公開アクセス可能です。
ただし、無効になっている場合は、以下に説明するようにトークンを発行して、
サービスが正しく実行されていることを確認できます。
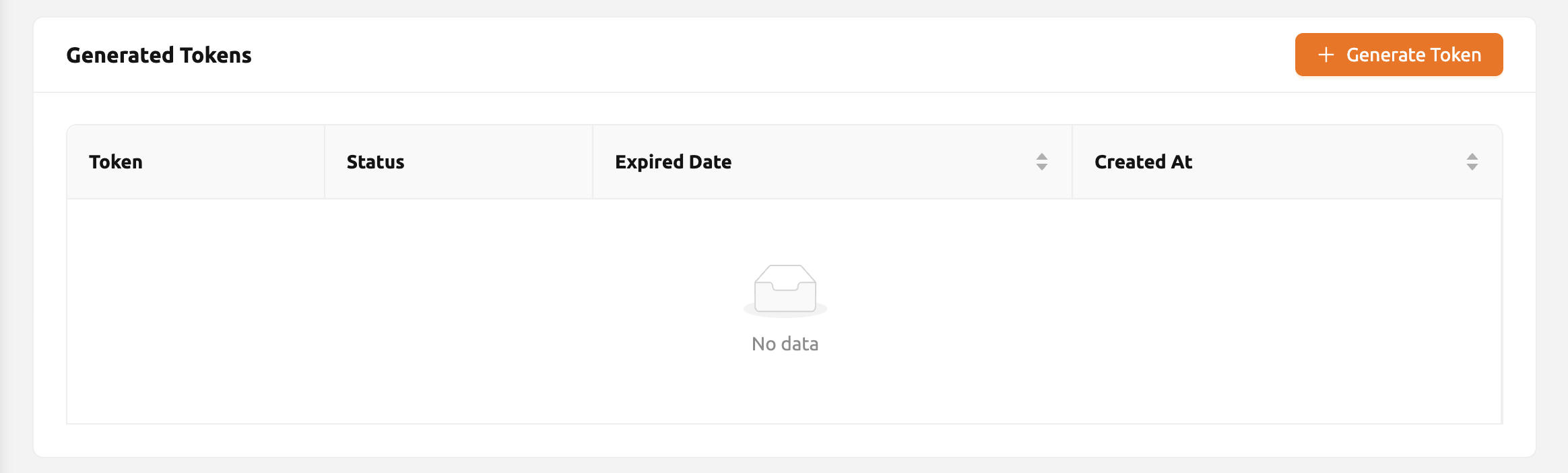
生成されたトークン一覧の右側にあるGenerate Tokenボタンを
クリックします。表示されるモーダルで有効期限を入力します。
発行されたトークンは生成されたトークン一覧に追加されます。各トークンにはステータス(有効または期限切れ)、有効期限、作成日が表示されます。トークン
項目のcopyボタンをクリックしてトークンをコピーし、以下のキーの値として追加します。
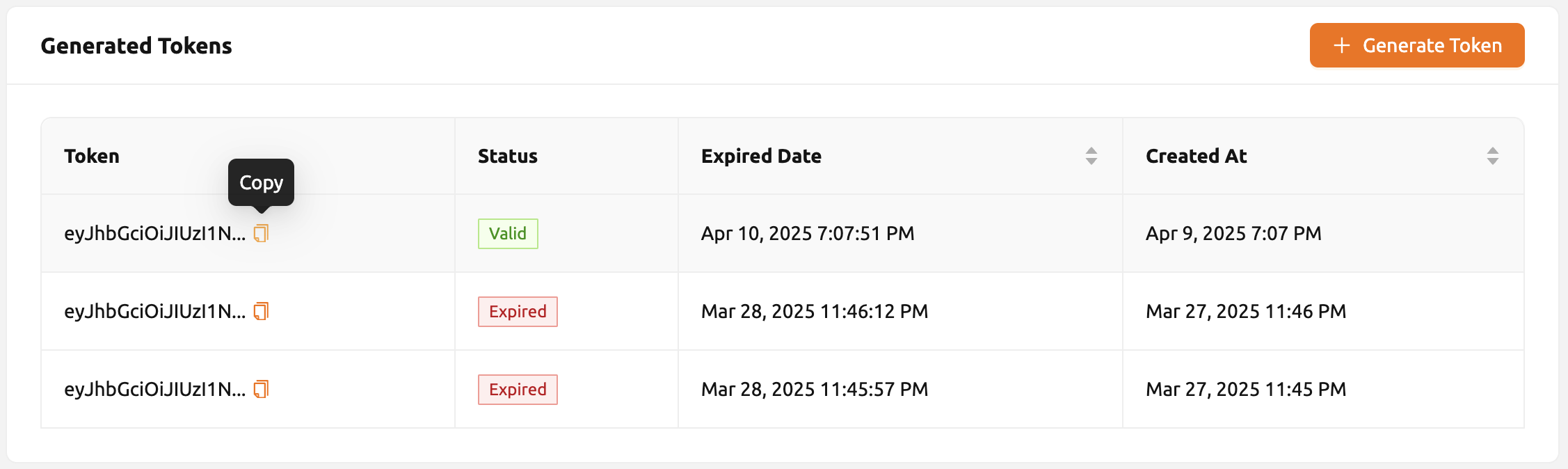
| Key | Value |
|---|---|
| Content-Type | application/json |
| Authorization | BackendAI |
ルート情報#
ルート情報カードは、モデルサービスのルーティングステータスを表示します。以下の基準でルートをフィルタリングできます:
- Running / Finished: アクティブなルートノードと完了したルートノードを切り替えます。
- プロパティフィルター: ヘルスステータスおよびトラフィックステータスでフィルタリングします。
ルートノードをクリックするとセッション詳細ドロワーが開き、個別のセッション詳細を表示できます。
ルートにエラーが発生した場合、ルート行のエラーインジケーターをクリックすると、そのルートの生のエラーデータを表示するJSONビューアーモーダルが開きます。これは、個々のルートノードの問題を診断するのに役立ちます。
サービスの変更#
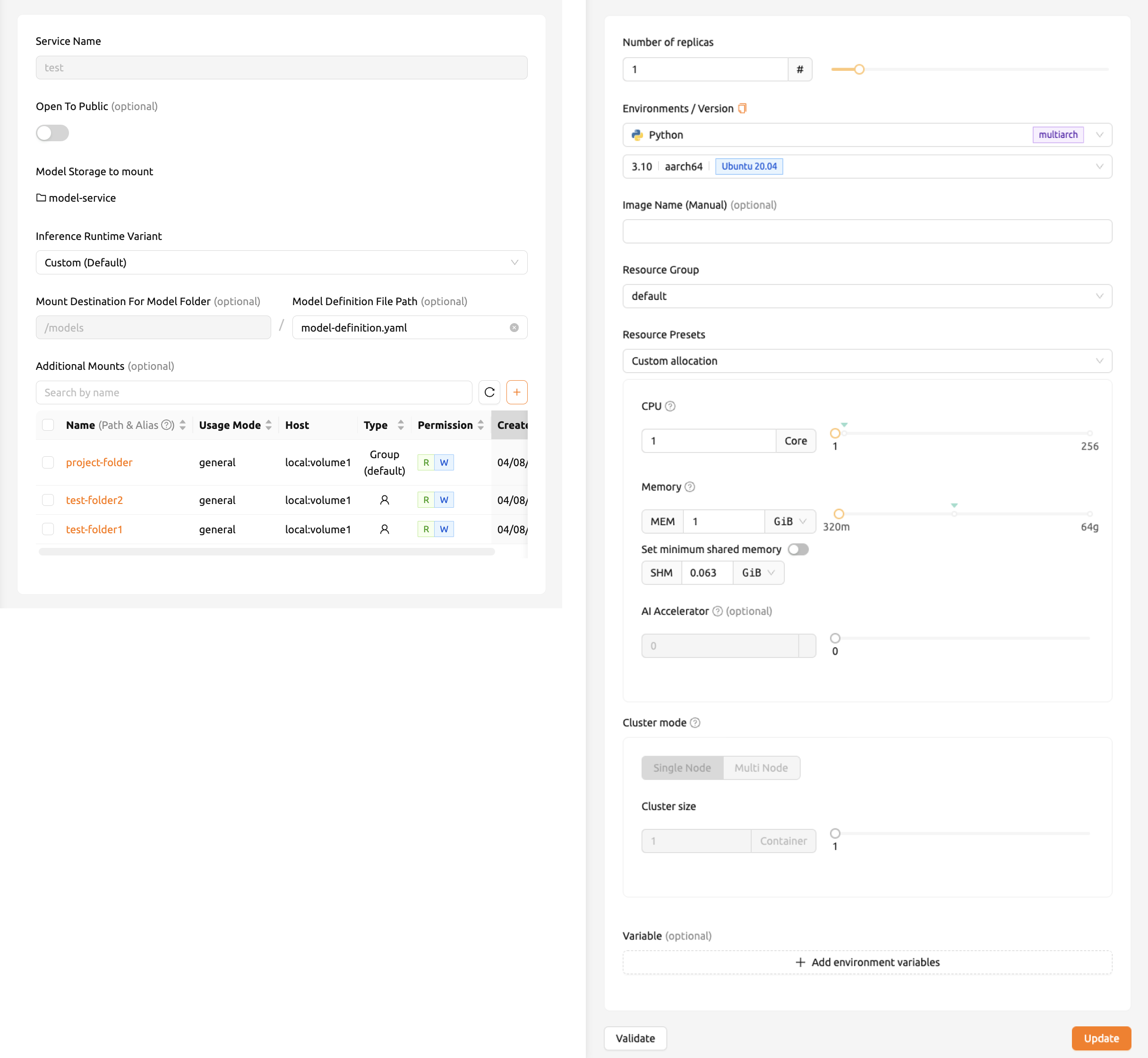
エンドポイント詳細ページのEditボタンをクリックして、モデルサービスを変更します。以前に入力したフィールドが入力された状態でサービスランチャーが開きます。変更したいフィールドのみを選択的に変更できます。フィールドを変更した後、Updateをクリックして変更を適用します。
サービスの終了#
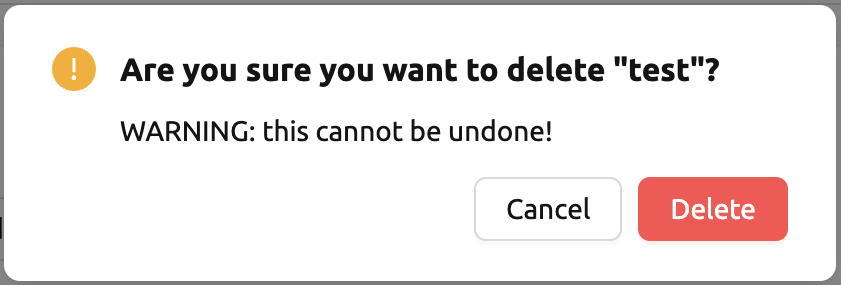
モデルサービスは、目的のセッション数に合わせてルーティング数を調整するために、定期的にスケジューラーを実行します。ただし、これはBackend.AIスケジューラーに負担をかけます。そのため、不要になったモデルサービスは終了することを推奨します。モデルサービスを終了するには、Controls列のDeleteボタンをクリックします。モデルサービスを終了するかどうかの確認モーダルが表示されます。Deleteをクリックするとモデルサービスが終了します。終了したモデルサービスはDestroyedフィルタービューに表示されます。
サービスエンドポイントへのアクセス#
APIリクエストの送信#
モデルサービングを完了するには、実際のエンドユーザーと情報を共有して、モデルサービスが実行されているサーバーにアクセスできるようにする必要があります。サービス作成時にOpen To Publicオプションが有効になっている場合、エンドポイント詳細ページからサービスエンドポイントの値を共有できます。オプションが無効の状態でサービスが作成された場合は、以前に生成したトークンとともにサービスエンドポイントの値を共有できます。
以下は、モデルサービングエンドポイントへのリクエスト送信が正しく機能しているかどうかを確認するcurlコマンドの簡単な例です:
$ export API_TOKEN="<token>"
$ curl -H "Content-Type: application/json" -X GET -H "Authorization: BackendAI $API_TOKEN" <model-service-endpoint>デフォルトでは、エンドユーザーはエンドポイントにアクセスできるネットワーク上にいる必要があります。 サービスがクローズドネットワークで作成された場合、そのクローズドネットワーク内にアクセスできる エンドユーザーのみがサービスにアクセスできます。
LLMチャットテスト#
大規模言語モデル(LLM)サービスを作成した場合、リアルタイムでLLMをテストできます。
エンドポイント詳細ページのサービスエンドポイントセクションにあるLLM Chat Testボタンをクリックします。

作成したモデルが自動的に選択されたChatページにリダイレクトされます。 Chatページで提供されるチャットインターフェースを使用して、LLMモデルをテストできます。 チャット機能の詳細については、Chatページを参照してください。
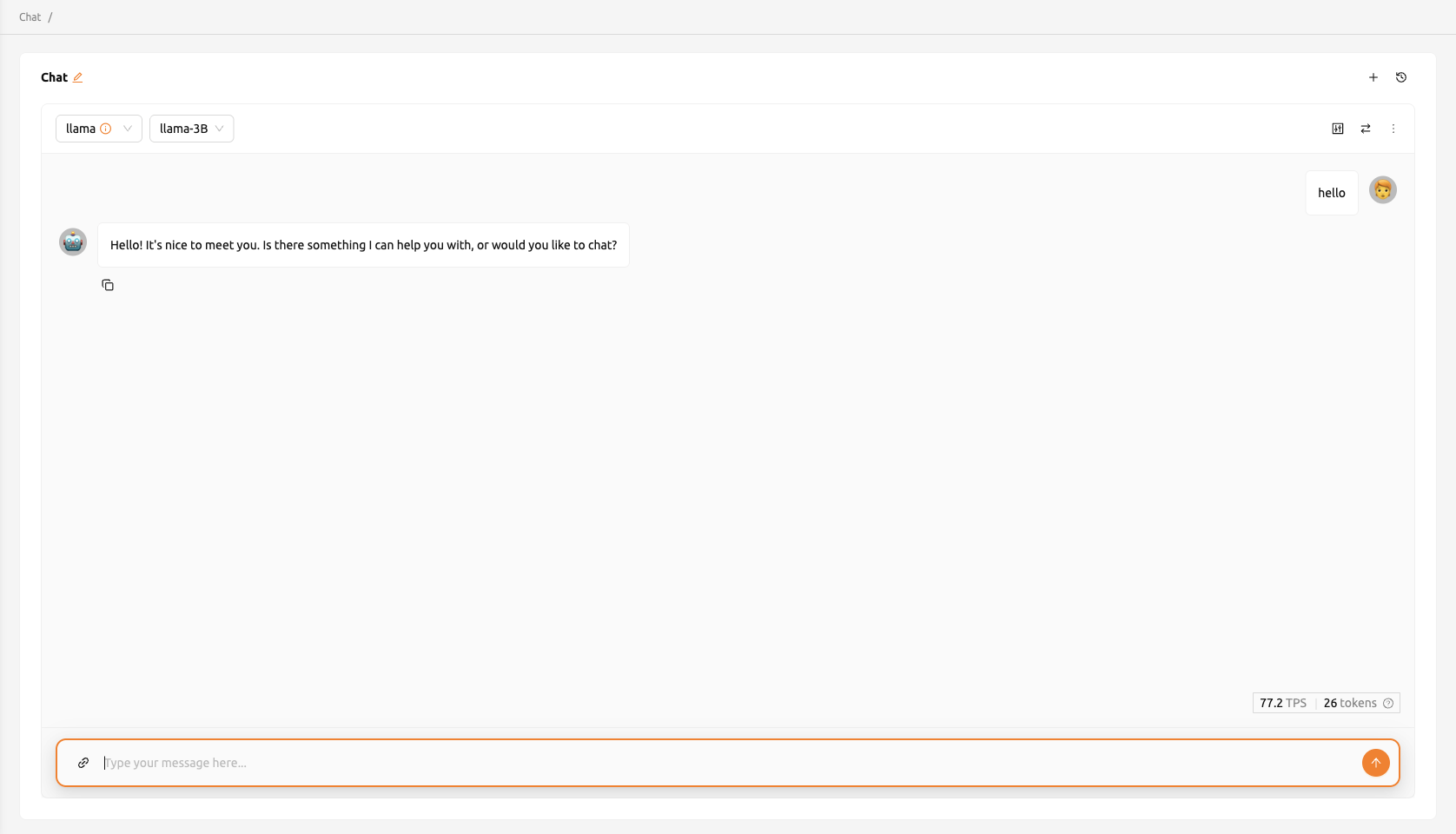
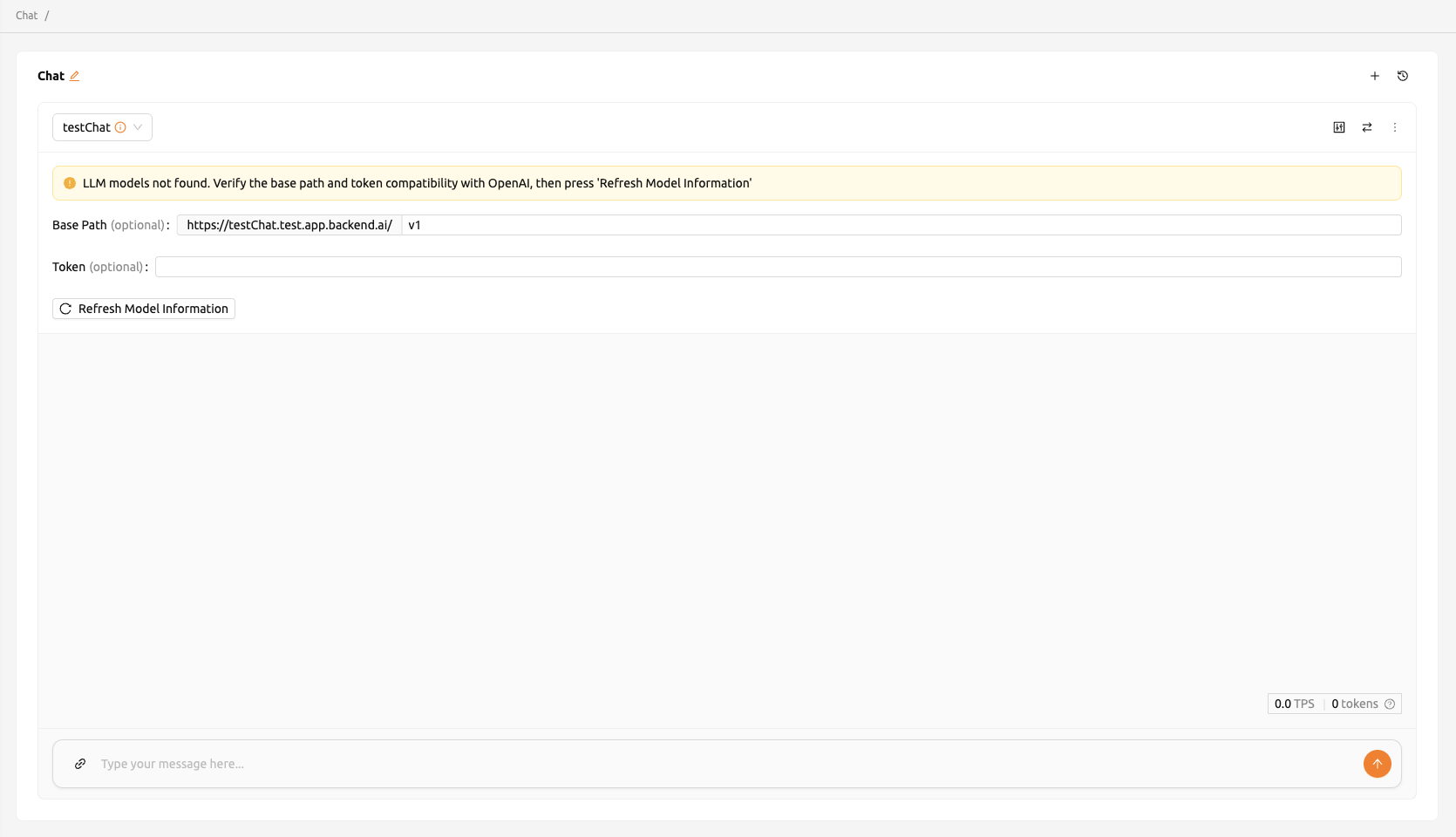
API接続に問題が発生した場合、Chatページにモデル設定を手動で構成できるオプションが表示されます。 モデルを使用するには、以下の情報が必要です:
- baseURL(オプション): モデルが配置されているサーバーのベースURLです。 バージョン情報を含めてください。 例えば、OpenAI APIを使用する場合は、https://api.openai.com/v1 を入力してください。
- Token(オプション): モデルサービスにアクセスするための認証キーです。トークンは Backend.AIだけでなく、さまざまなサービスから生成できます。形式と生成プロセスは サービスによって異なる場合があります。詳細については、常に特定のサービスのガイドを参照してください。 例えば、Backend.AIで生成されたサービスを使用する場合は、 トークンの生成方法についてはトークンの生成セクションを参照してください。
モデルストア#
モデルストア(Model Store)は、事前構成されたモデルを閲覧、検索、デプロイできるカードベースのギャラリーを提供します。サイドバーメニューからモデルストアにアクセスできます。
モデルの閲覧と検索#
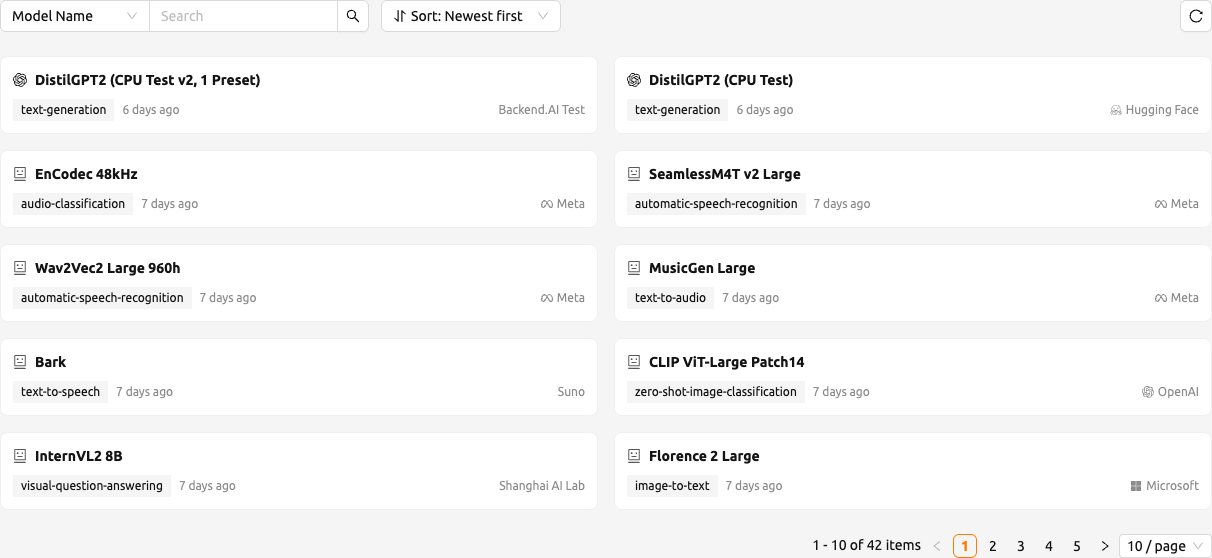
ページ上部には検索と並べ替えのレイアウトが使用されています:
- モデルの検索(Search Models): 名前でフィルタリング(Filter By Name)プロパティフィルターを使用して、モデルカードを名前で検索します。
- 並べ替え(Sort): 結果の並び順を選択します。使用可能なオプションは、
名前 (A→Z)、名前 (Z→A)、古い順、新しい順です。 - 更新(Refresh): 更新ボタンをクリックしてカード一覧を再読み込みします。
各カードには、モデルブランドのアイコン、タイトル(タイトルが設定されていない場合は名前)、タスクタグ、相対作成時刻、およびアイコン付きの著者(Author)が表示されます。現在のプロジェクトに互換性のあるプリセットがないカードは不透明度 50 % で表示されます。そのようなカードを開いて詳細を表示することは可能ですが、デプロイ(Deploy) ボタンは無効化され、ドロワーに 互換性のあるプリセットがありません。このモデルはデプロイできません。 というエラーアラートが表示されます。
サーバーで MODEL_STORE プロジェクトが設定されていない場合、ページには管理者に問い合わせるようにとの案内とともに モデルストアプロジェクトが見つかりません というメッセージが表示されます。フィルターに一致するモデルカードがない場合は モデルが見つかりません と表示されます。
一覧はページ下部でページネーションされます。ページサイズは 10、20、50 件の中から変更できます。
モデルカードの詳細#
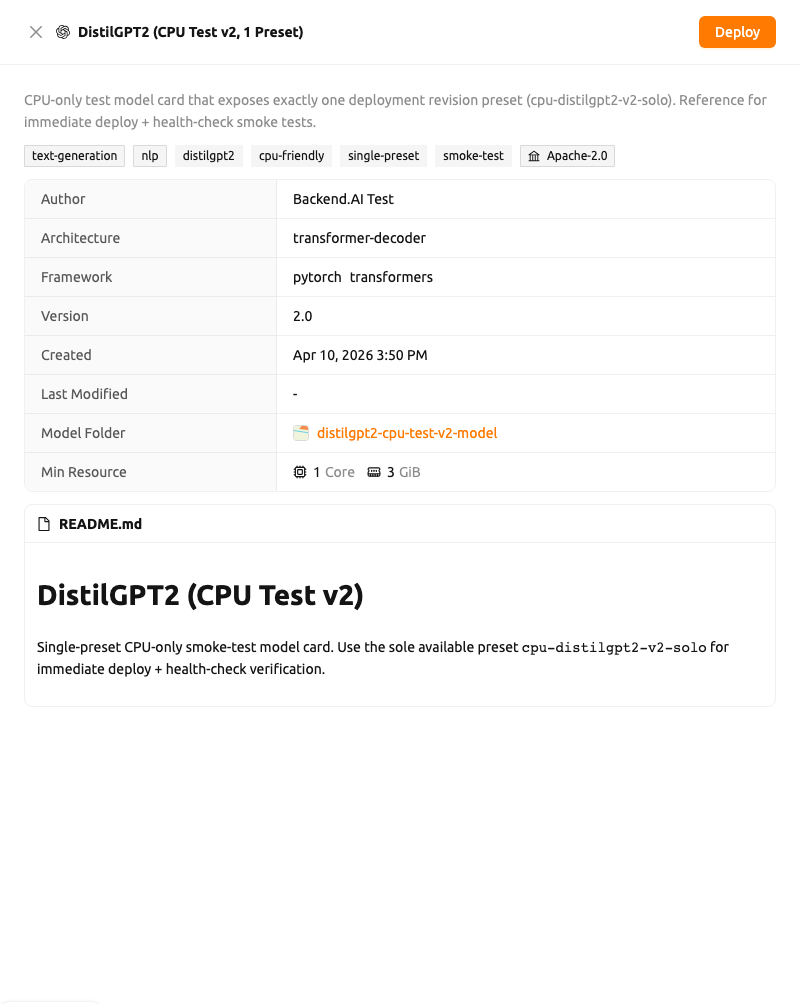
カードをクリックすると、ページの右側にモデルカードのドロワーが開きます。ドロワーの上部にはモデルのタイトルと説明が表示され、次にタスク、カテゴリ、ラベル、ライセンスのタグが続き、その後に次の項目を含む詳細一覧が表示されます:
- 著者(Author)
- アーキテクチャ(Architecture)
- フレームワーク(Framework)(各フレームワークはアイコン付きで表示)
- バージョン(Version)
- 作成日時(Created) および 最終更新日時(Last Modified) のタイムスタンプ
- モデルフォルダ(Model Folder): モデルストレージフォルダのフォルダエクスプローラを開くクリック可能なリンク
- 最小リソース(Min Resource): 最小リソース要件(CPU、メモリ、GPU)
モデルカードに README が含まれている場合は、ドロワーの下部に README.md カードとしてレンダリングされます。
モデルのデプロイ#
ドロワーヘッダーの デプロイ(Deploy) ボタンをクリックすると、モデルがサービスとしてデプロイされます。デプロイフローは次の 2 通りのいずれかで動作します:
自動デプロイ: モデルに使用可能なプリセットがちょうど 1 つあり、現在のプロジェクトにアクセス可能なリソースグループがちょうど 1 つある場合、モーダルを表示せずにデプロイが静かに作成されます。エンドポイントがクエリ可能になった後、そのエンドポイント詳細ページに遷移します。
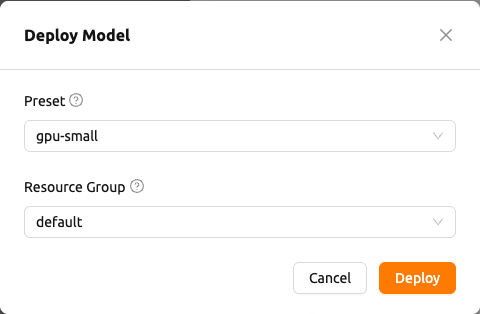
モデルのデプロイモーダル(Deploy Model): それ以外の場合、モデルのデプロイモーダルが次の必須フィールドとともに開きます。
- プリセット(Preset): 使用可能なリソースプリセットのグループ化されたドロップダウンです。プリセットが複数のランタイムバリアントにまたがる場合、オプションはランタイムバリアント名ごとにグループ化されます。それ以外の場合は、フラットなリストとして表示されます。
- リソースグループ(Resource Group): サービスが実行されるリソースグループです。
モーダルの
デプロイ(Deploy)ボタンをクリックしてデプロイを開始します。モデルがデプロイされたことを確認する成功トーストが表示され、エンドポイント詳細ページに遷移します。
選択したモデルに現在のプロジェクトと互換性のあるプリセットがない場合、ドロワーの
デプロイ(Deploy) ボタンは無効化され、互換性のあるプリセットが利用可能になるまで
デプロイはブロックされます。