모델 서빙#
모델 서비스#
이 기능은 엔터프라이즈 전용 기능입니다.
Backend.AI는 모델 학습 단계에서 개발 환경 구축과 리소스 관리를 지원할 뿐만 아니라, 23.09 버전부터 모델 서비스 기능도 지원합니다. 이 기능을 통해 엔드 유저(AI 기반 모바일 앱 및 웹 서비스 백엔드 등)는 완성된 모델을 추론 서비스로 배포하고자 할 때 추론 API 호출을 수행할 수 있습니다.
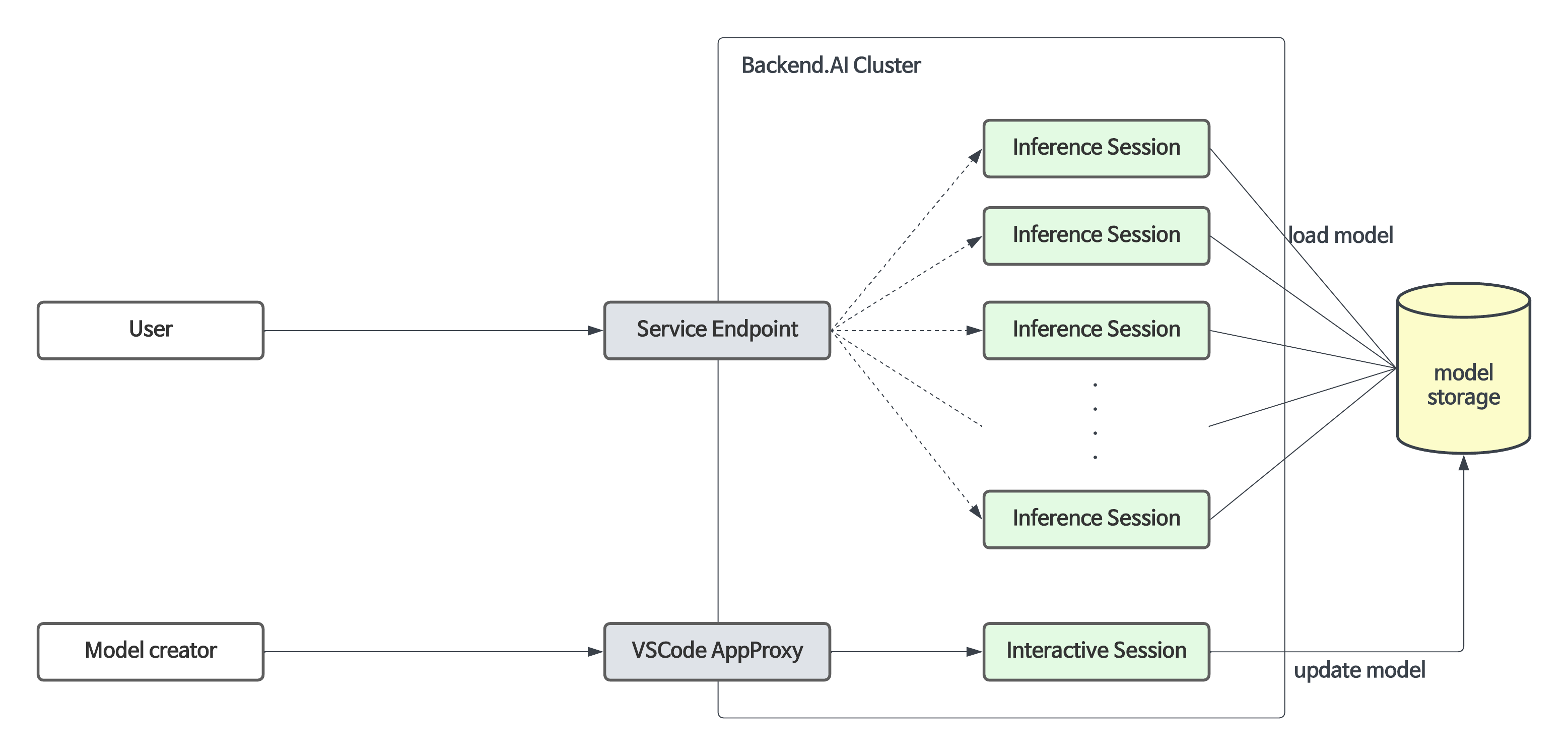
모델 서비스는 기존의 학습용 연산 세션 기능을 확장하여, 자동화된 유지·보수 및 스케일링을 가능하게 하고 프로덕션 서비스를 위한 영구적인 포트 및 엔드포인트 주소 매핑을 제공합니다. 개발자나 관리자가 연산 세션을 수동으로 생성·삭제할 필요 없이 모델 서비스에 필요한 스케일링 파라미터를 지정해 주기만 하면 됩니다.
모델 서비스를 사용하기 위한 단계 안내#
26.4.0 버전부터는 별도의 설정 파일 없이도 모델 서비스를 간편하게 배포할 수 있습니다.
빠른 배포 (권장): 모델 스토어에서 사전 구성된 모델을 탐색하고 배포(Deploy) 버튼을 클릭하면 바로 배포할 수 있습니다.
서비스 런처를 통한 배포: 서빙 페이지에서 Start Service 버튼을 클릭하여 서비스 런처를 열고, vLLM, SGLang 등의 런타임 변형을 선택하면 별도의 모델 정의 파일 없이 모델 서비스를 생성할 수 있습니다.
일반적인 워크플로우는 다음과 같습니다:
- 서비스 런처에서 모델 서비스를 생성합니다.
- (모델 서비스가 공개되지 않은 경우) 토큰을 발급합니다.
- (엔드 유저용) 서비스 엔드포인트에 접속하여 서비스를 확인합니다.
- (필요한 경우) 모델 서비스를 수정합니다.
- (필요한 경우) 모델 서비스를 종료합니다.
고급: 모델 정의 파일 및 서비스 정의 파일 사용하기 (Custom 런타임)
Custom 런타임 변형을 사용하거나 더 세밀한 제어가 필요한 경우, 모델 정의 파일과 서비스 정의 파일을 직접 생성하여 사용할 수 있습니다:
- 모델 정의 파일을 생성합니다.
- 서비스 정의 파일을 생성합니다.
- 정의 파일들을 모델 타입 폴더에 업로드합니다.
- 서비스 런처에서
Custom런타임을 선택하여 모델 서비스를 생성/유효성 검사합니다.
자세한 내용은 아래의 모델 정의 파일 생성하기 및 서비스 정의 파일 생성 섹션을 참조하세요.
모델 정의 파일 생성하기#
24.03 버전부터 모델 정의 파일 이름을 구성할 수 있습니다. 모델 정의 파일 경로에
다른 입력 필드를 입력하지 않으면 시스템은 model-definition.yml 또는
model-definition.yaml로 간주합니다.
모델 정의 파일은 Backend.AI 시스템이 추론용 세션을 자동으로 시작, 초기화하고 필요에 따라 스케일링할 때 필요한 설정 정보를 담고 있는 파일입니다. 이 파일을 추론 서비스 엔진을 담고 있는 컨테이너 이미지와는 독립적으로 모델 타입 폴더에 저장합니다. 이를 통해 모델을 실행하는 엔진이 다양한 모델을 필요에 따라 바꿔가며 서비스할 수 있도록 하며, 모델이 변경될 때마다 컨테이너 이미지를 새로 빌드 및 배포하지 않아도 되도록 해줍니다. 네트워크 스토리지에서 직접 모델 정의와 모델 데이터를 불러오므로, 자동 스케일링 시 배포 과정을 더 단순화 및 효율화할 수 있습니다.
모델 정의 파일은 다음과 같은 형식을 따릅니다.
models:
- name: "simple-http-server"
model_path: "/models"
service:
start_command:
- python
- -m
- http.server
- --directory
- /home/work
- "8000"
port: 8000
health_check:
path: /
interval: 10.0
max_retries: 10
max_wait_time: 15.0
expected_status_code: 200
initial_delay: 60.0모델 정의 파일에 대한 키-값 설명
"(필수)" 표시가 없는 필드는 선택사항입니다.
name(필수): 모델의 이름을 정의합니다.model_path(필수): 모델이 정의된 경로를 지정합니다.service: 서비스될 파일들에 대한 정보를 구성하는 항목입니다 (명령 스크립트 및 코드 포함).pre_start_actions:start_command이전에 실행되는 작업입니다. 이러한 작업들은 구성 파일 생성, 디렉토리 설정, 초기화 스크립트 실행 등을 통해 환경을 준비합니다. 작업은 정의된 순서대로 순차적으로 실행됩니다.action: 수행할 작업 유형입니다. 사용 가능한 작업 유형과 해당 매개변수는 사전 시작 작업을 참조하세요.args: 작업별 매개변수입니다. 각 작업 유형마다 다른 필수 인수가 있습니다.
start_command(필수): 모델 서빙에서 실행될 명령을 지정합니다. 문자열 또는 문자열 목록으로 지정할 수 있습니다.port(필수): 모델 서비스를 위한 컨테이너 포트입니다 (예:8000,8080).health_check: 모델 서비스의 주기적인 상태 모니터링을 위한 구성입니다. 이 설정이 구성되면, 시스템은 자동으로 서비스가 올바르게 응답하는지 확인하고 비정상 인스턴스를 트래픽 라우팅에서 제거합니다.path(필수): 상태 확인 요청을 위한 HTTP 엔드포인트 경로입니다 (예:/health,/v1/health).interval(기본값:10.0): 연속적인 상태 확인 간의 시간(초 단위)입니다.max_retries(기본값:10): 서비스를UNHEALTHY로 표시하기 전에 허용되는 연속 실패 횟수입니다. 이 임계값을 초과하기 전까지 서비스는 계속 트래픽을 받습니다.max_wait_time(기본값:15.0): 각 상태 확인 HTTP 요청의 타임아웃 시간(초 단위)입니다. 이 시간 내에 응답이 없으면 확인은 실패로 간주됩니다.expected_status_code(기본값:200): 정상 응답을 나타내는 HTTP 상태 코드입니다. 일반적인 값:200(OK),204(No Content).initial_delay(기본값:60.0): 컨테이너 생성 후 상태 확인을 시작하기 전에 대기하는 시간(초 단위)입니다. 이는 모델 로딩, GPU 초기화 및 서비스 워밍업에 시간을 제공합니다. 대형 모델의 경우 더 높은 값을 설정하세요 (예: 70B+ LLM의 경우300.0).
상태 확인 동작 이해하기
상태 확인 시스템은 개별 모델 서비스 컨테이너를 모니터링하고, 상태에 따라 트래픽 라우팅을 자동으로 관리합니다.
① AppProxy: 트래픽 라우팅 제어

② Manager: 상태 관리 및 eviction

내부 상태 정보(트래픽 라우팅에 사용됨)는 사용자 인터페이스에 표시되는 상태와 즉시 동기화되지 않을 수 있습니다.
UNHEALTHY가 되기까지의 시간:
초기 시작 시:
initial_delay + interval × (max_retries + 1)기본값 예시: 60 + 10 × 11 = 170초 (약 3분)
운영 중(정상 상태 이후):
interval × (max_retries + 1)기본값 예시: 10 × 11 = 110초 (약 2분)
Backend.AI 모델 서빙에서 지원되는 서비스 작업 설명
write_file: 지정된 파일 이름으로 파일을 생성하고 내용을 추가하는 작업입니다. 기본 액세스 권한은644입니다.arg/filename: 파일 이름 지정body: 파일에 추가할 내용 지정mode: 파일의 액세스 권한 지정append: 파일 내용의 덮어쓰기 또는 추가를True또는False로 설정
write_tempfile: 임시 파일 이름(.py)으로 파일을 생성하고 내용을 추가하는 작업입니다. 모드 값이 지정되지 않은 경우 기본 액세스 권한은644입니다.body: 파일에 추가할 내용 지정mode: 파일의 액세스 권한 지정
run_command: 명령을 실행한 결과가 오류를 포함하여 다음 형식으로 반환됩니다 (out: 명령 실행 출력,err: 명령 실행 중 오류 발생 시 오류 메시지)args/command: 실행할 명령을 배열로 지정 (예:python3 -m http.server 8080명령은 ["python3", "-m", "http.server", "8080"]이 됩니다)
mkdir: 입력 경로로 디렉토리를 생성하는 작업입니다args/path: 디렉토리를 생성할 경로 지정
log: 입력 메시지로 로그를 출력하는 작업입니다args/message: 로그에 표시할 메시지 지정debug: 디버그 모드인 경우True, 그렇지 않으면False로 설정
모델 정의 파일을 모델 타입 폴더에 업로드#
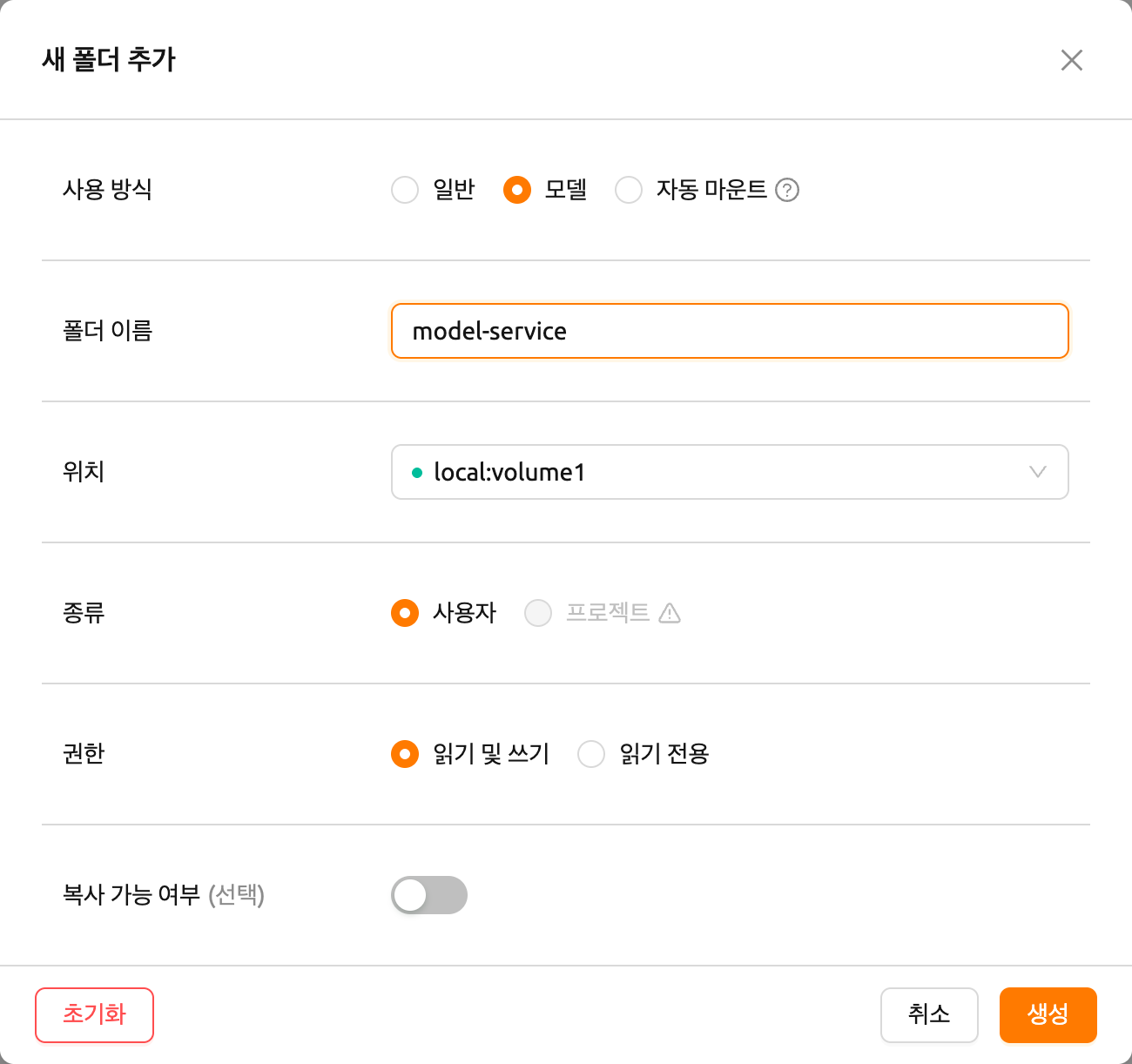
모델 정의 파일(model-definition.yml)을 모델 타입 폴더에 업로드하려면
가상 폴더를 생성해야 합니다. 가상 폴더를 생성할 때 기본 general 타입 대신
model 타입을 선택하세요. 폴더 생성 방법에 대한 지침은 데이터 페이지의
스토리지 폴더 생성 섹션을 참조하세요.
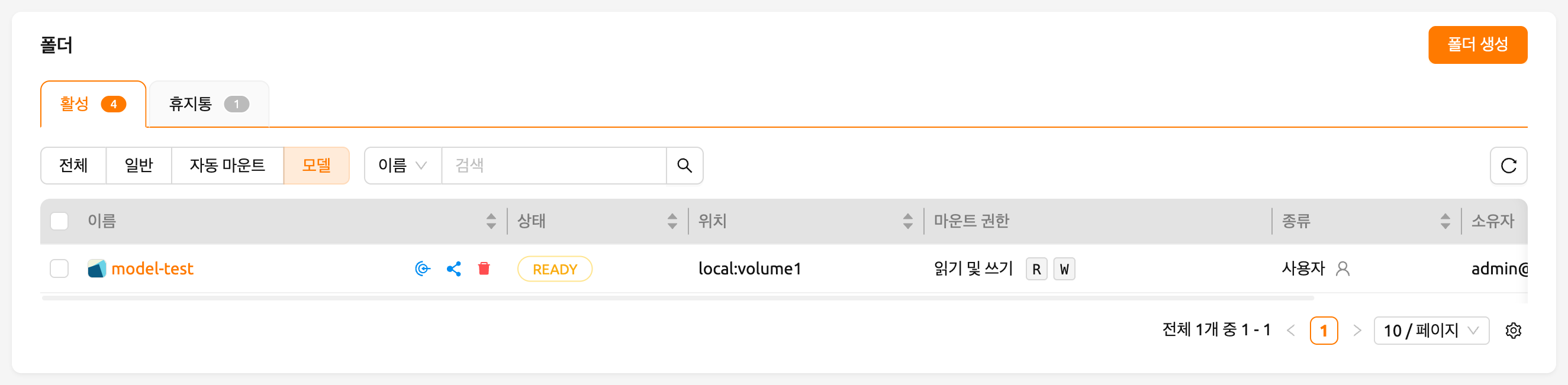
폴더를 생성한 후, 데이터 페이지에서 'MODELS' 탭을 선택하고 최근에 생성한 모델 타입 폴더 아이콘을 클릭하여 폴더 탐색기를 열고 모델 정의 파일을 업로드합니다. 폴더 탐색기 사용 방법에 대한 자세한 내용은 폴더 탐색 섹션을 참조하세요.
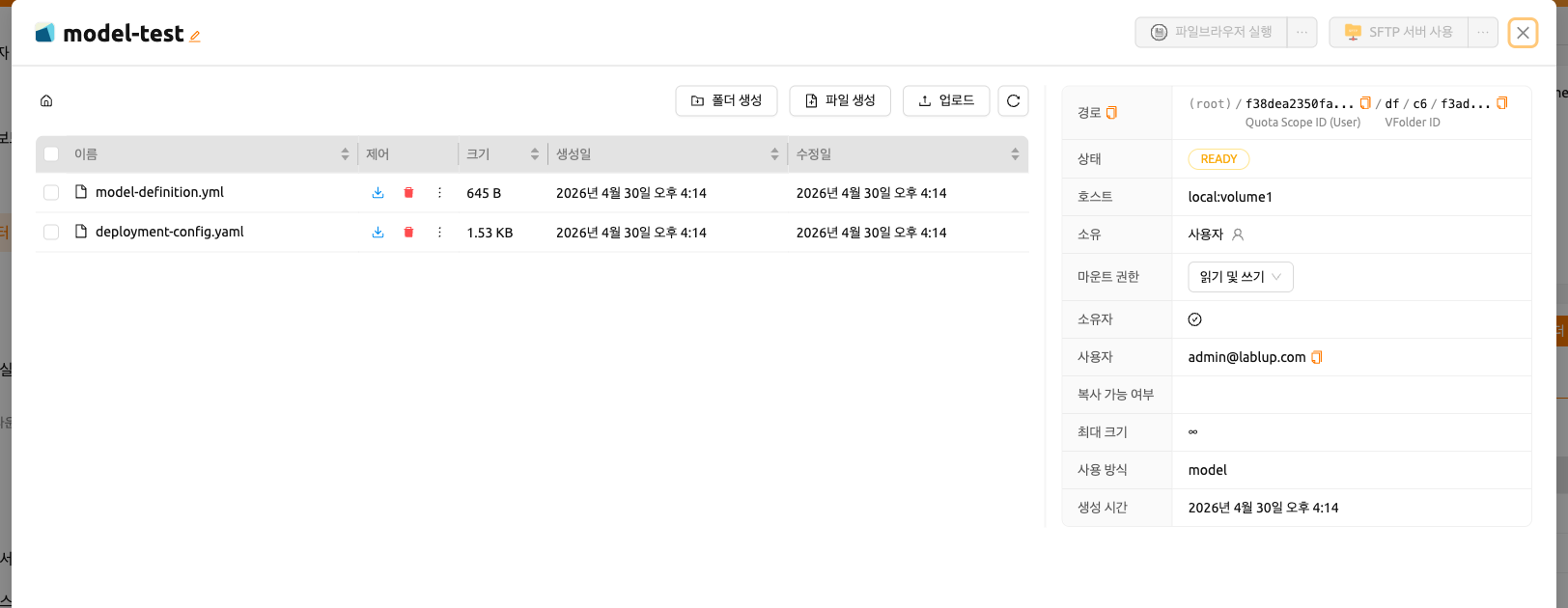
서비스 정의 파일 생성#
서비스 정의 파일(service-definition.toml)을 사용하면 관리자가 모델 서비스에 필요한 리소스, 환경 및 런타임 설정을 미리 구성할 수 있습니다. 이 파일이 모델 폴더에 있으면, 시스템은 서비스를 생성할 때 이러한 설정을 기본값으로 사용합니다.
model-definition.yaml과 service-definition.toml 모두 모델 폴더에 있어야
모델 스토어 페이지에서 배포(Deploy) 버튼이 활성화됩니다. 이 두 파일은 함께
작동합니다: 모델 정의는 모델과 추론 서버 구성을 지정하고, 서비스 정의는 런타임
환경, 리소스 할당 및 환경 변수를 지정합니다.
서비스 정의 파일은 런타임 변형별로 섹션이 구성된 TOML 형식을 따릅니다. 각 섹션은 서비스의 특정 측면을 구성합니다.
[vllm.environment]
image = "example.com/model-server:latest"
architecture = "x86_64"
[vllm.resource_slots]
cpu = 1
mem = "8gb"
"cuda.shares" = "0.5"
[vllm.environ]
MODEL_NAME = "example-model-name"서비스 정의 파일의 키-값 설명
[{runtime}.environment]: 모델 서비스의 컨테이너 이미지와 아키텍처를 지정합니다.image(필수): 추론 서비스에 사용할 컨테이너 이미지의 전체 경로 (예:example.com/model-server:latest).architecture(필수): 컨테이너 이미지의 CPU 아키텍처 (예:x86_64,aarch64).
[{runtime}.resource_slots]: 모델 서비스에 할당할 컴퓨트 리소스를 정의합니다.cpu: 할당할 CPU 코어 수 (예:1,2,4).mem: 할당할 메모리 양. 단위 접미사 지원 (예:"8gb","16gb")."cuda.shares": 할당할 분할 GPU(fGPU) 공유 (예:"0.5","1.0"). 키에 점이 포함되어 있으므로 이 값은 따옴표로 묶습니다.
[{runtime}.environ]: 추론 서비스 컨테이너에 전달되는 환경 변수를 설정합니다.- 런타임에서 필요한 모든 환경 변수를 정의할 수 있습니다. 예를 들어,
MODEL_NAME은 일반적으로 로드할 모델을 지정하는 데 사용됩니다.
- 런타임에서 필요한 모든 환경 변수를 정의할 수 있습니다. 예를 들어,
각 섹션 헤더의 {runtime} 접두사는 런타임 변형 이름
(예: vllm, nim, custom)에 해당합니다. 시스템은 서비스를 생성할 때
선택한 런타임 변형과 이 접두사를 매칭합니다.
배포(Deploy) 버튼을 사용하여 모델 스토어에서 서비스를 생성하면
service-definition.toml의 설정이 자동으로 적용됩니다. 나중에 리소스 할당을
조정해야 하는 경우, 모델 서빙 페이지를 통해 서비스를 수정할 수 있습니다.
서빙 페이지 개요#
서빙 페이지는 현재 프로젝트의 모든 모델 서비스 엔드포인트 목록을 표시합니다. 사이드바 메뉴에서 모델 서빙을 클릭하여 접근할 수 있습니다.
페이지 상단에서 라이프사이클 단계별로 엔드포인트를 필터링할 수 있습니다:
- Active: 현재 실행 중이거나 생성 중인 엔드포인트를 표시합니다. 기본 보기입니다.
- Destroyed: 종료된 엔드포인트를 표시합니다.
또한 속성 필터 바를 사용하여 엔드포인트 이름, 서비스 엔드포인트 URL, 또는 소유자(관리자 및 슈퍼관리자에게 제공)별로 엔드포인트를 검색할 수 있습니다.
Start Service 버튼을 클릭하여 서비스 런처를 열고 새 모델 서비스를 생성합니다.
모델 서비스 생성#
서비스 런처#
서빙 페이지에서 Start Service 버튼을 클릭하여 서비스 런처를 엽니다.
서비스 이름 및 기본 설정#
먼저 서비스 이름을 입력합니다. 다음 필드를 사용할 수 있습니다:
- 서비스 이름: 엔드포인트를 구분하는 고유 이름입니다.
- 앱을 외부에 공개: 별도의 토큰 없이 모델 서비스에 액세스할 수 있도록 허용합니다. 기본적으로 비활성화되어 있습니다.
- 마운트할 모델 스토리지 폴더: 모델 파일이 포함된 스토리지 폴더를 선택합니다.
- 인퍼런스 런타임 종류: 모델 서비스의 런타임 변형을 선택합니다. 사용 가능한 변형은 백엔드에서 동적으로 로드되며, 설치에 따라
vLLM,SGLang,NVIDIA NIM,Modular MAX,Custom등이 포함될 수 있습니다. - 실행 환경 / 버전: 모델 서비스의 실행 환경을 구성합니다. 런타임 변형을 선택하면 환경 이미지가 자동으로 필터링됩니다.
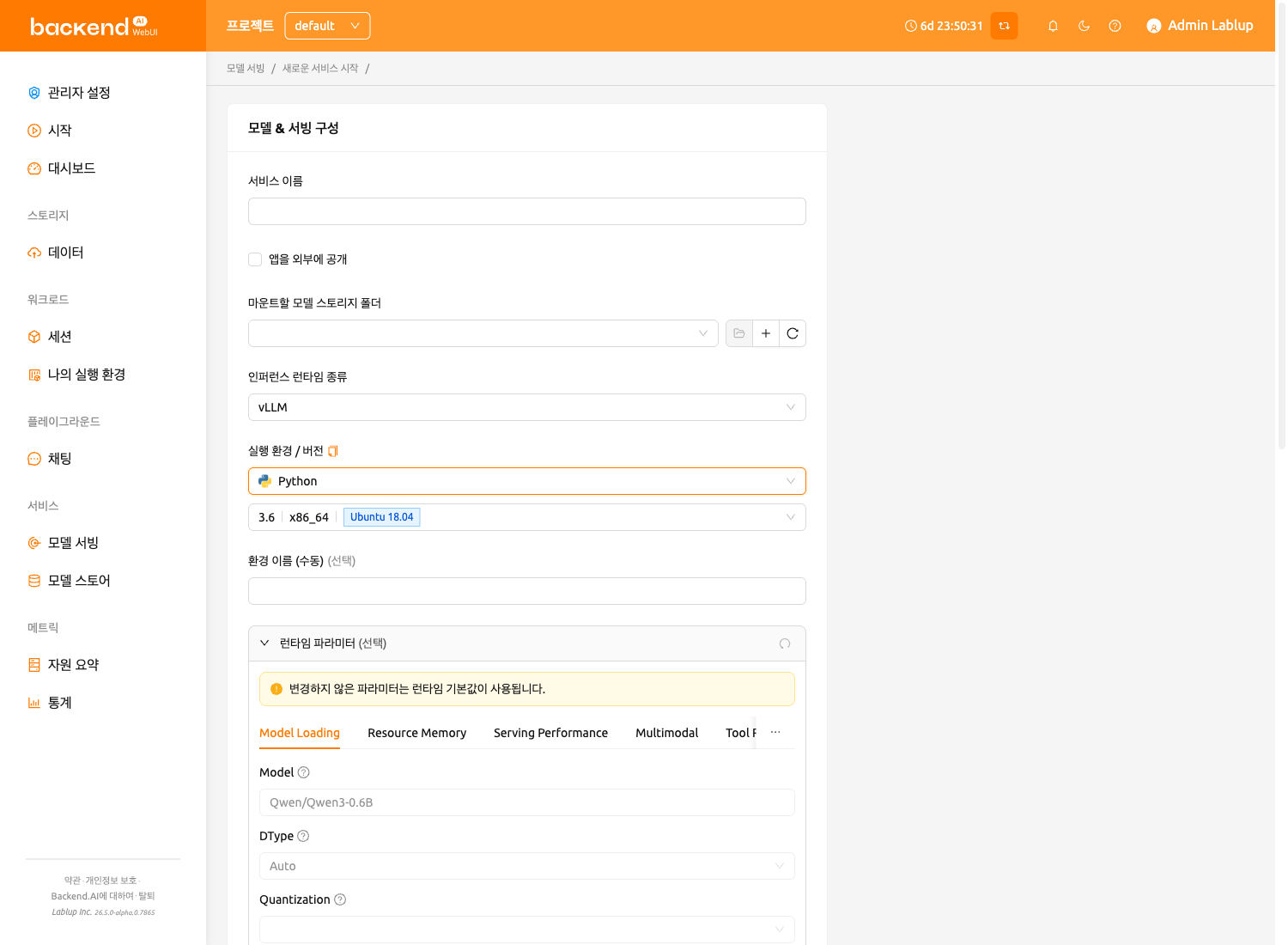
vLLM, SGLang, NVIDIA NIM, Modular MAX 등의 런타임 변형을 선택하면, 모델 폴더에 model-definition 파일을 구성할 필요가 없습니다. 대신 선택한 변형에 따라 시스템이 모델 구성을 자동으로 처리합니다.

모델 정의 모드 (Custom 런타임 전용)#
Custom 런타임 변형을 선택하면, 모델 서비스를 정의하는 두 가지 모드를 선택할 수 있습니다:
명령어 입력 모드#
명령어 입력을 선택하여 CLI 명령어를 직접 붙여넣을 수 있습니다. 예를 들어:
vllm serve /models/my-model --tp 2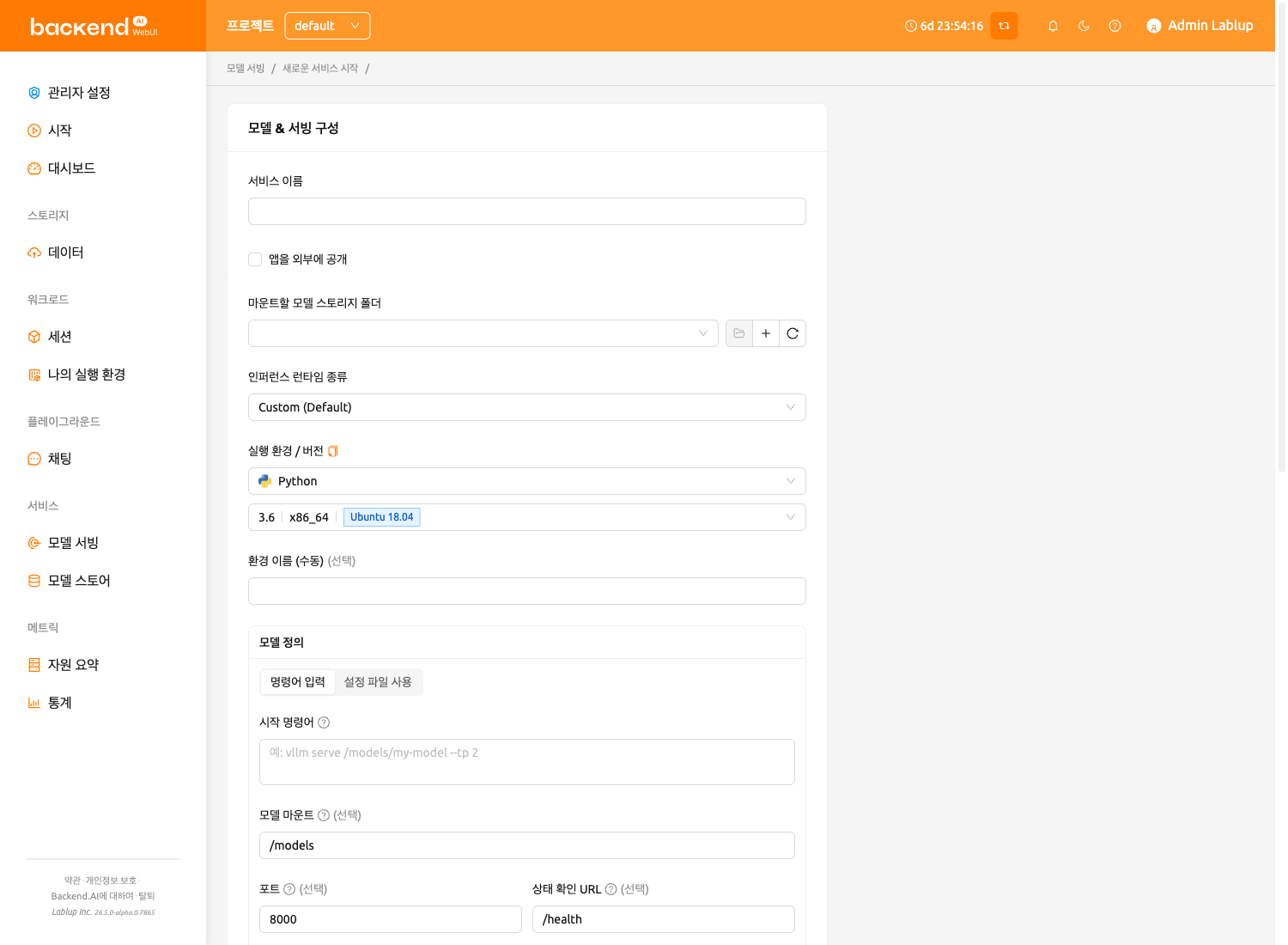
시스템이 자동으로 명령어를 분석하여 다음 필드를 채웁니다:
- 시작 명령어: 모델 서빙에서 실행될 명령어를 직접 입력합니다.
- 모델 마운트: 컨테이너 내에서 모델 스토리지 폴더가 마운트되는 경로입니다 (기본값
/models). - 포트(Port): 명령어에서 자동 감지됩니다 (기본값
8000). 모델 서빙 프로세스가 수신하는 포트 번호입니다. - 상태 확인 URL: 명령어에서 자동 감지됩니다 (기본값
/health). 서비스 헬스 체크 시 호출되는 HTTP 엔드포인트 경로입니다. - 초기 지연 시간: 서비스 시작 후 첫 번째 상태 확인까지 대기하는 시간(초)입니다 (기본값
60.0). - 최대 재시도 횟수: 서비스가 실패로 판단되기 전까지의 최대 상태 확인 시도 횟수입니다 (기본값
10).
명령어가 멀티 GPU 사용을 암시하는 경우(예: --tp 2), 올바른 수의 GPU 리소스를
할당하는 데 도움이 되는 GPU 힌트가 표시됩니다.
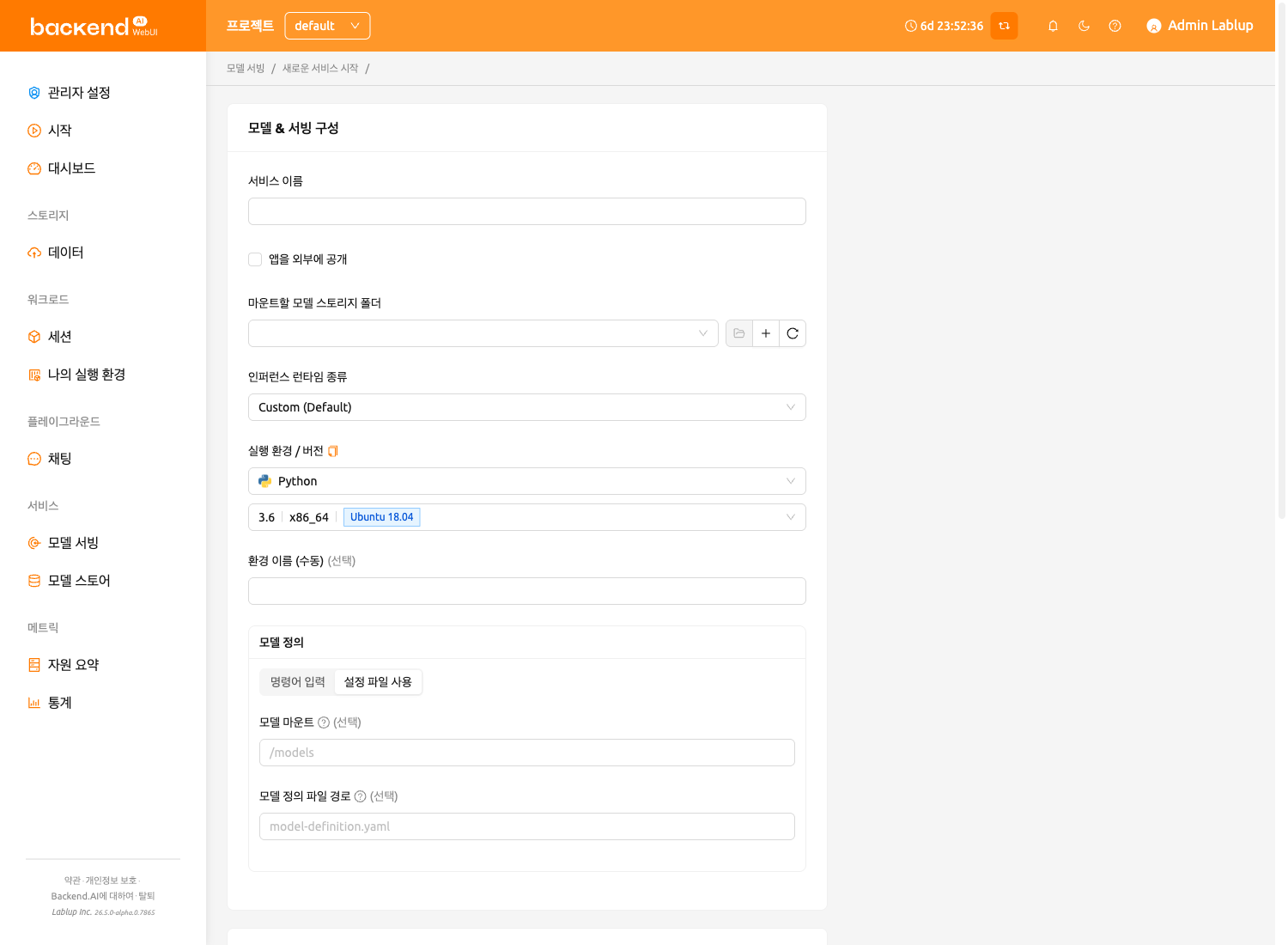
설정 파일 사용 모드#
설정 파일 사용을 선택하여 기존의 model-definition.yaml 방식을 사용합니다. 이 모드에서는 다음을 설정할 수 있습니다:
- 모델 폴더의 마운트 대상: 세션에서 모델 스토리지가 마운트되는 경로입니다. 기본값은
/models입니다. - 모델 정의 파일 경로: 업로드한 모델 정의 파일의 경로입니다. 기본값은
model-definition.yaml입니다. - 추가 마운트: 추가 스토리지 폴더를 마운트할 수 있습니다. 추가 모델 폴더가 아닌 일반/데이터 사용 모드 폴더만 마운트할 수 있다는 점에 유의하세요.
런타임 파라미터 (vLLM / SGLang)#
vLLM 또는 SGLang 런타임 변형을 선택하면 런타임 파라미터 섹션이 나타납니다. 이 섹션에서는 구성 파일을 수동으로 편집하지 않고도 모델 서빙 동작을 미세 조정할 수 있습니다.
파라미터는 탭으로 구분된 카테고리별로 구성됩니다. 탭 목록은 런타임 변형에 따라 다릅니다.
변경하지 않은 파라미터는 런타임 기본값이 사용됩니다.
vLLM 런타임 파라미터
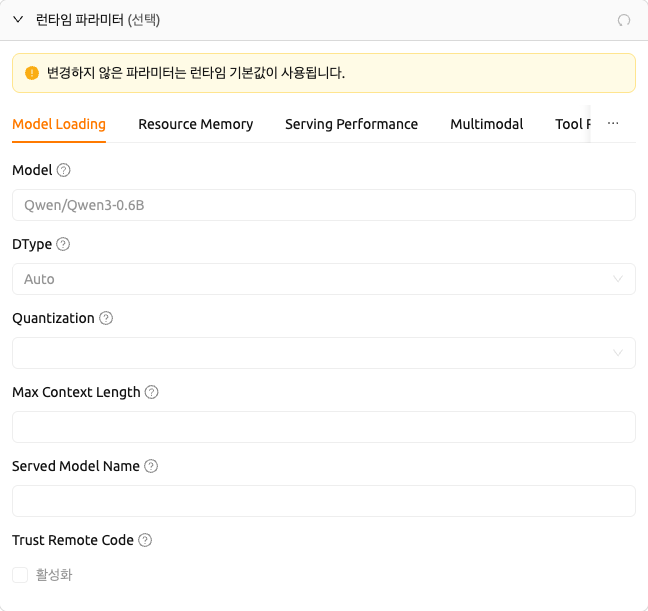
vLLM은 다음 탭을 제공합니다: Model Loading, Resource Memory, Serving Performance, Multimodal, Tool Reasoning 등.
Model Loading 탭의 주요 필드:
- Model: 사용할 모델의 이름 또는 경로입니다.
- DType: 모델 가중치 및 연산의 데이터 타입입니다 (예:
Auto,float16,bfloat16). - Quantization: 모델 양자화 방식입니다 (예:
awq,gptq,fp8). - Max Model Length: 모델이 처리할 수 있는 최대 컨텍스트 길이(토큰 수)입니다.
- Served Model Name: API 엔드포인트에서 노출할 모델 이름입니다.
- Trust Remote Code: 모델 저장소의 커스텀 모델 코드 실행을 허용합니다.
SGLang 런타임 파라미터

SGLang은 다음 탭을 제공합니다: Model Loading, Resource Memory, Serving Performance, Tool Reasoning 등.
Model Loading 탭의 주요 필드:
- Model: 사용할 모델의 이름 또는 경로입니다.
- DType: 모델 가중치 및 연산의 데이터 타입입니다 (예:
Auto,float16,bfloat16). - Quantization: 모델 양자화 방식입니다 (예:
awq,gptq,fp8). - Context Length: 모델이 처리할 수 있는 최대 컨텍스트 길이입니다.
- Served Model Name: API 엔드포인트에서 노출할 모델 이름입니다.
- Trust Remote Code: 모델 저장소의 커스텀 모델 코드 실행을 허용합니다.
런타임 파라미터 외에도, vLLM 및 SGLang 런타임 변형은 서비스 런처의 환경 변수 섹션에서 특정 환경 변수를 제공합니다:
- vLLM:
BACKEND_MODEL_NAME,VLLM_QUANTIZATION,VLLM_TP_SIZE(텐서 병렬화),VLLM_PP_SIZE(파이프라인 병렬화),VLLM_EXTRA_ARGS(추가 CLI 인자) - SGLang:
BACKEND_MODEL_NAME,SGLANG_QUANTIZATION,SGLANG_TP_SIZE(텐서 병렬화),SGLANG_PP_SIZE(파이프라인 병렬화),SGLANG_EXTRA_ARGS(추가 CLI 인자)
이러한 환경 변수는 런타임 파라미터 섹션이 아닌 런처의 환경 변수 섹션에 나타납니다. 각 런타임 변형에 특화된 추가 구성 옵션을 제공합니다.
런타임 변형 비교#
다음 표는 세 가지 주요 런타임 변형 간의 주요 차이점을 요약합니다:
| 기능 | Custom | vLLM | SGLang |
|---|---|---|---|
| 런타임 파라미터 섹션 | 없음 | 있음 | 있음 |
| 명령어 입력 / 설정 파일 사용 전환 | 있음 | 없음 | 없음 |
| 환경 변수 프리셋 | 수동 입력만 | VLLM_* 프리셋 |
SGLANG_* 프리셋 |
| 편집 시 폼 사전 채우기 | 있음 (최신 리비전 기준) | 없음 | 없음 |
환경 및 리소스#
레플리카 수를 설정하고 환경 및 자원 그룹을 선택합니다.
- 레플리카 수: 서비스에 대해 유지할 라우팅 세션 수를 결정합니다. 이 값을 변경하면 매니저가 레플리카 세션을 생성하거나 종료합니다.
- 환경 / 버전: 모델 서비스의 실행 환경을 구성합니다. vLLM 등의 런타임 변형을 선택하면 환경 이미지가 자동으로 필터링되어 관련 이미지가 표시됩니다.
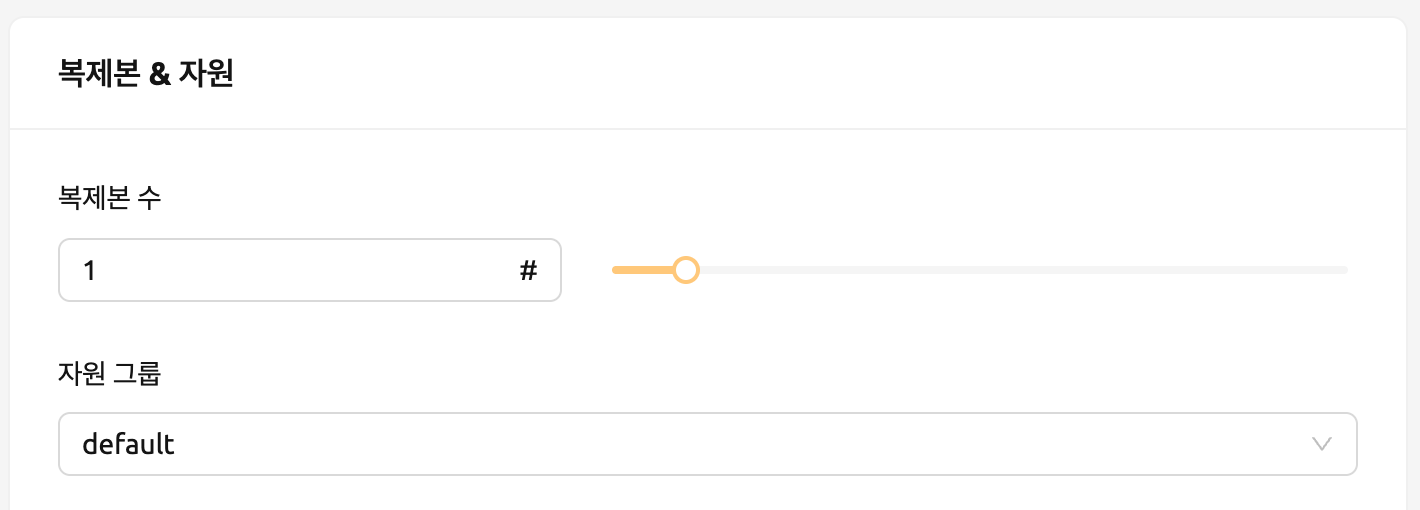
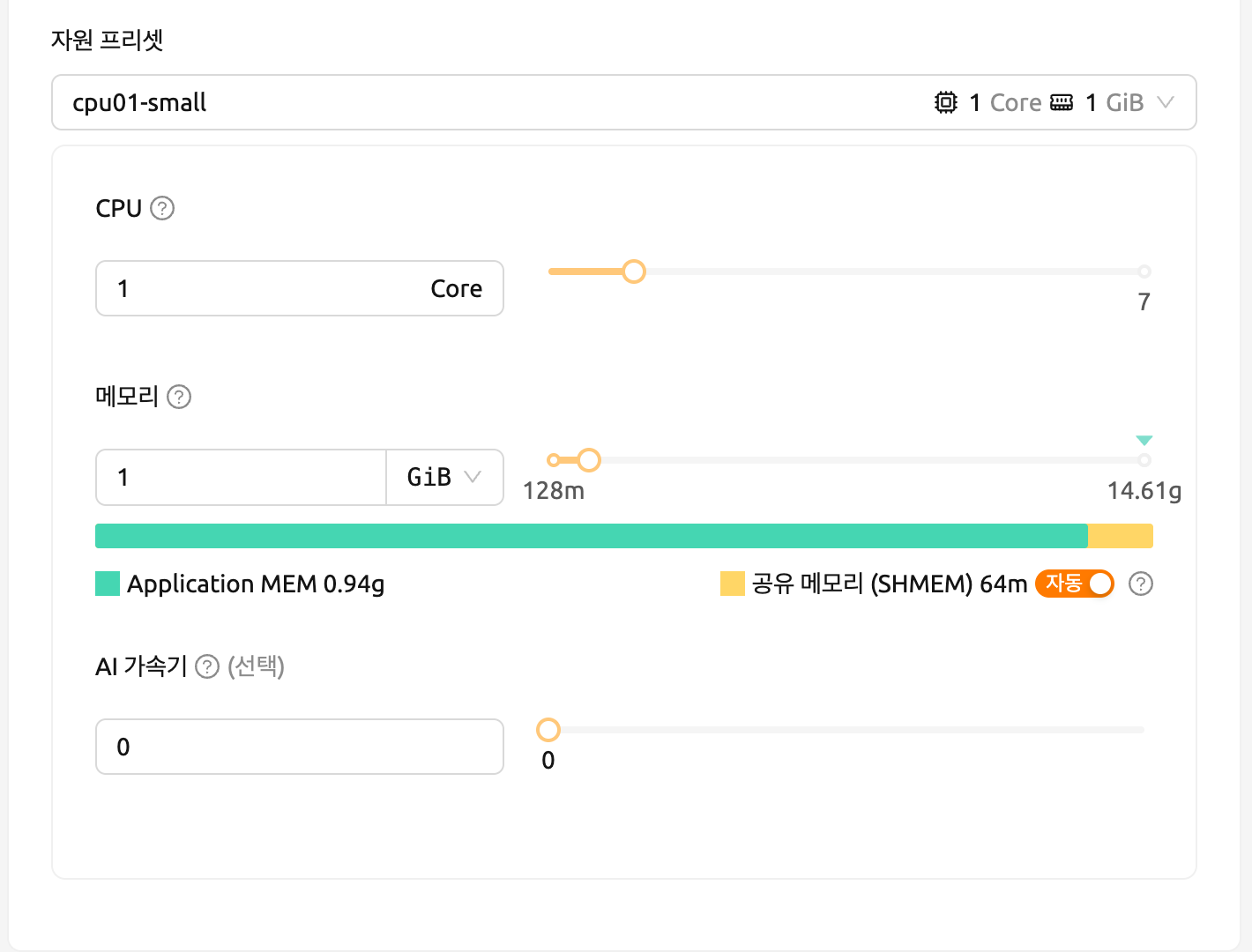
- 리소스 프리셋: 할당할 리소스 양을 선택합니다. 리소스에는 CPU, RAM 및 GPU가 포함됩니다.
클러스터 모드 및 환경 변수#
- Single Node: 세션 실행 시, 관리 노드와 워커 노드가 단일 물리 노드 또는 가상 머신에 배치됩니다.
- Multi Node: 하나의 관리 노드와 하나 이상의 워커 노드가 여러 물리 노드 또는 가상 머신에 분산됩니다.
- Variable: 모델 서비스를 시작할 때 환경 변수를 설정할 수 있습니다. 런타임 변형을 사용하여 모델 서비스를 생성할 때 유용합니다.

서비스 유효성 검사#
모델 서비스를 생성하기 전에, Backend.AI는 실행 가능 여부를 확인하는 유효성 검사 기능을 지원합니다.
서비스 런처의 왼쪽 하단에 있는 Validate 버튼을 클릭하면,
유효성 검사 이벤트를 확인하는 새 팝업이 나타납니다. 팝업 모달에서
컨테이너 로그를 통해 상태를 확인할 수 있습니다. 결과가
Finished로 설정되면 유효성 검사가 완료된 것입니다.
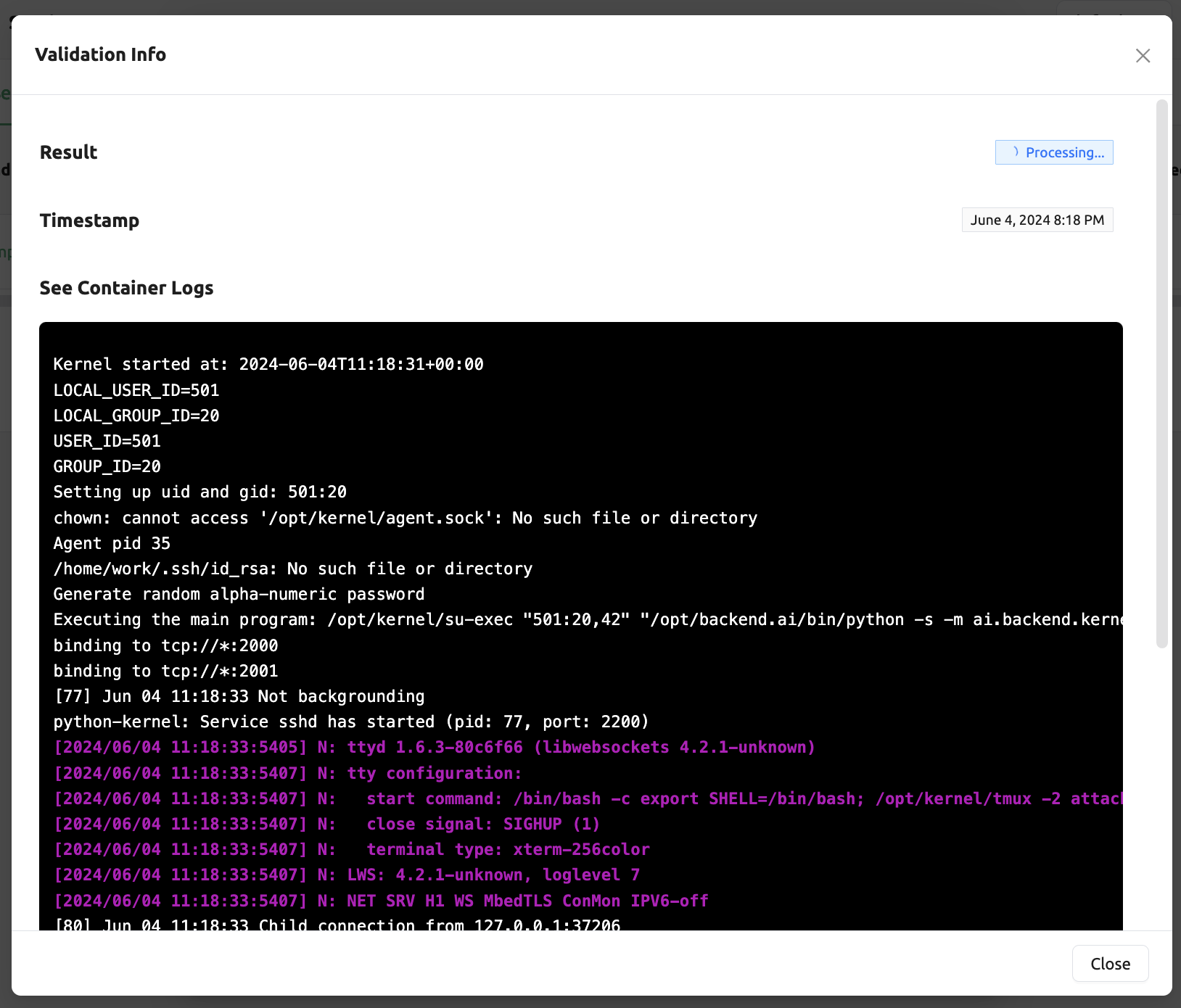
결과가 Finished라고 해서 실행이 성공적으로 완료되었다는 것을 보장하지는 않습니다.
대신 컨테이너 로그를 확인하세요.
실패한 모델 서비스 생성 처리#
모델 서비스의 상태가 UNHEALTHY로 유지되면,
모델 서비스가 제대로 실행될 수 없음을 나타냅니다.
생성 실패의 일반적인 원인과 해결 방법은 다음과 같습니다:
모델 서비스를 생성할 때 라우팅에 할당된 리소스가 부족함
- 해결 방법: 문제가 있는 서비스를 종료하고 이전 설정보다 더 충분한 리소스를 할당하여 다시 생성합니다.
모델 정의 파일(
model-definition.yml)의 형식이 잘못됨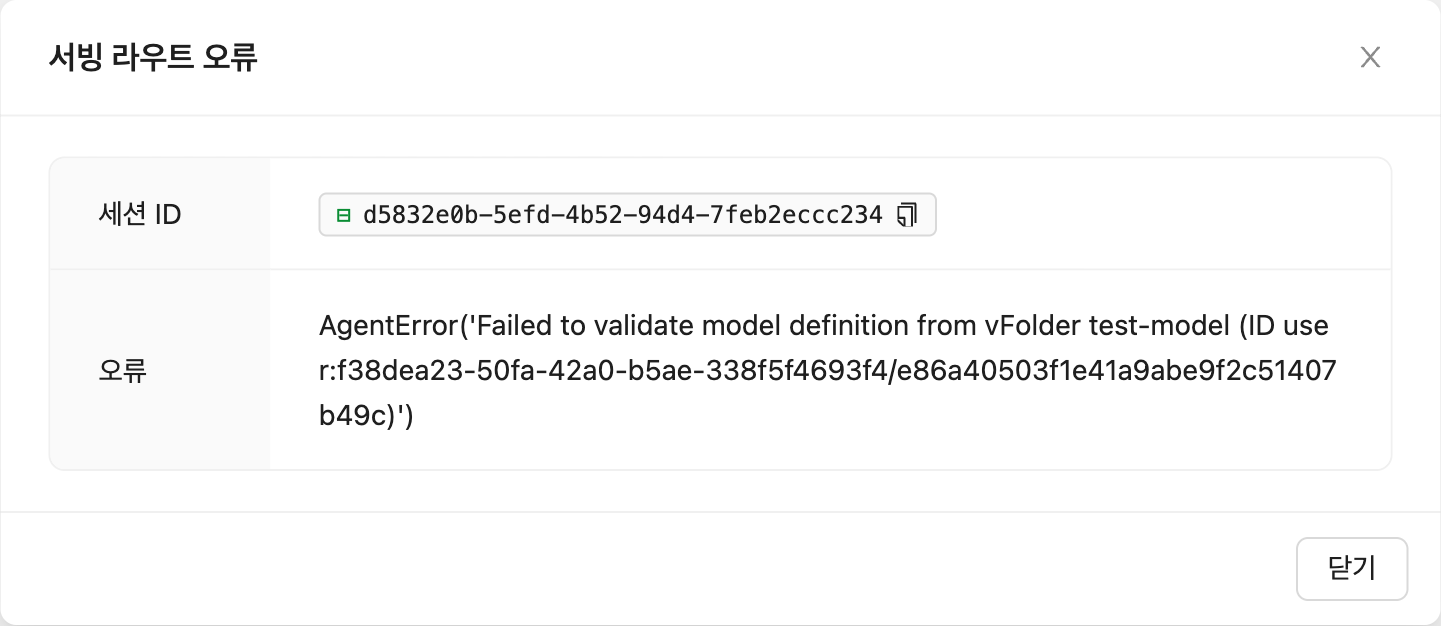
그림 13.18 - 해결 방법: 모델 정의 파일의 형식을 확인하고
키-값 쌍이 잘못된 경우 수정한 다음 저장된 위치에 파일을 덮어씁니다.
그런 다음
Clear error and retry버튼을 클릭하여 라우트 정보 테이블에 쌓인 모든 오류를 제거하고 모델 서비스의 라우팅이 올바르게 설정되었는지 확인합니다.
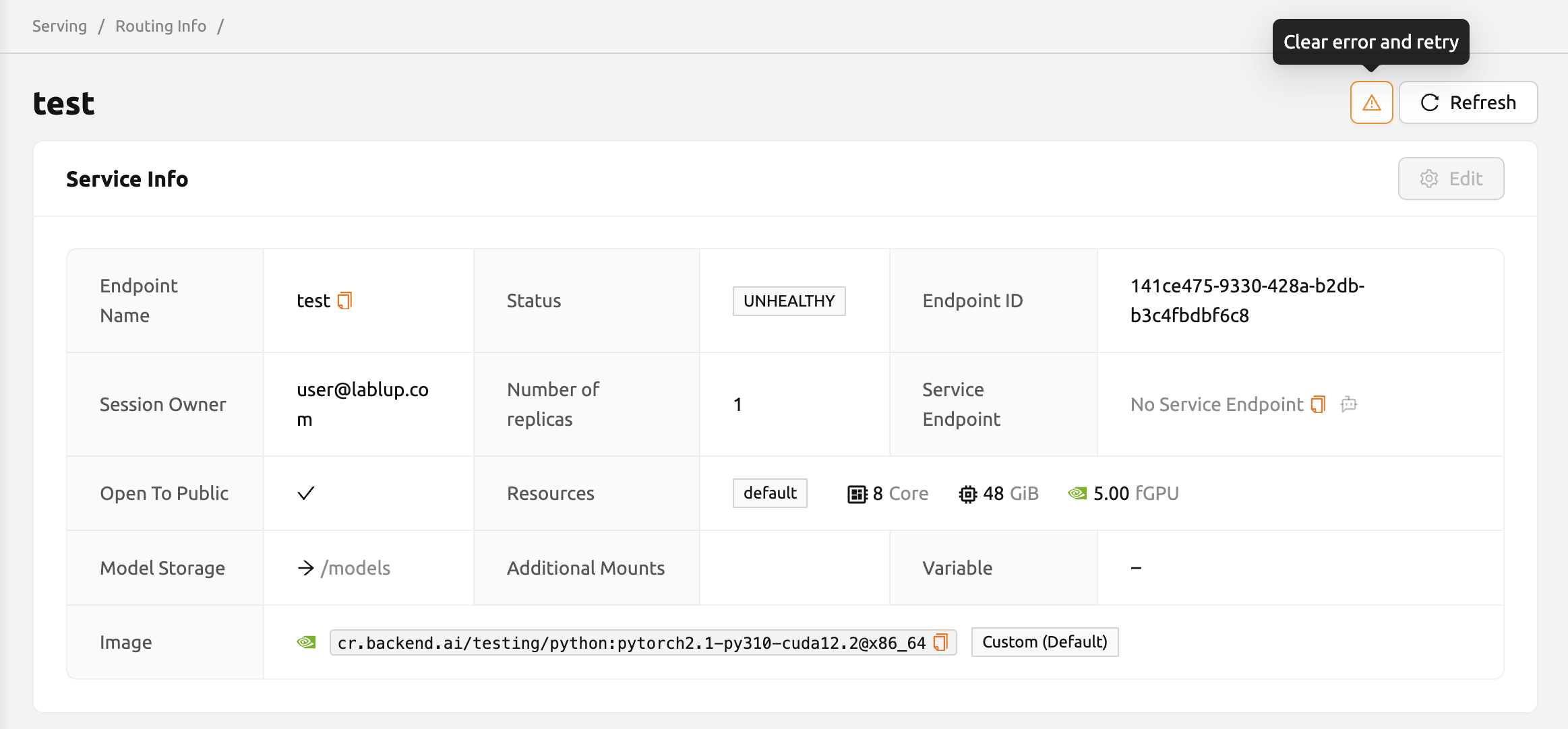
그림 13.19 - 해결 방법: 모델 정의 파일의 형식을 확인하고
키-값 쌍이 잘못된 경우 수정한 다음 저장된 위치에 파일을 덮어씁니다.
그런 다음
엔드포인트 상세 페이지#
서빙 목록에서 엔드포인트 이름을 클릭하면 모델 서비스에 대한 상세 정보를 볼 수 있습니다.
서비스 정보#
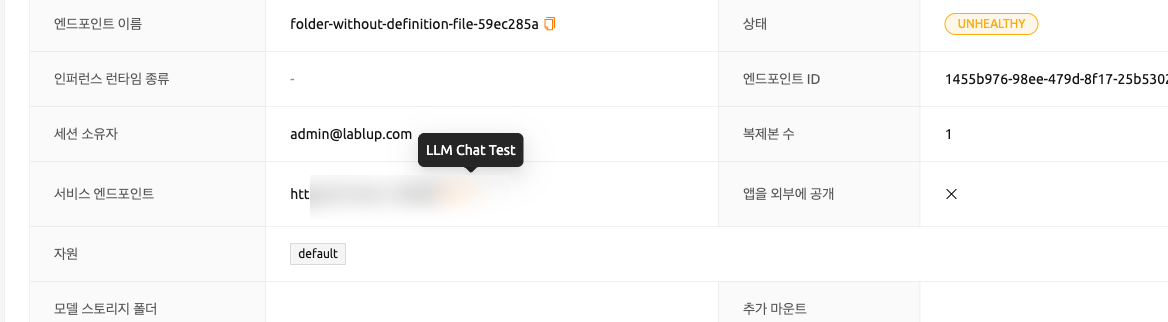
서비스 정보 카드에는 다음 세부 사항이 표시됩니다:
- 엔드포인트 이름 및 상태
- 엔드포인트 ID 및 세션 소유자
- 레플리카 수
- 서비스 엔드포인트: 모델 서비스에 액세스하기 위한 URL입니다. LLM 서비스의 경우
LLM Chat Test버튼이 제공됩니다. - Open To Public: 서비스가 공개적으로 액세스 가능한지 여부입니다.
- 리소스: 자원 그룹 및 할당된 CPU/메모리/GPU입니다.
- 모델 스토리지: 마운트된 모델 스토리지 폴더와 마운트 대상입니다.
- 추가 마운트: 마운트된 추가 스토리지 폴더입니다.
- 환경 변수: 코드 블록으로 표시됩니다.
- 이미지: 서비스에 사용되는 컨테이너 이미지입니다.
서비스 정보 카드에서 수정 버튼을 클릭하면 업데이트 런처로 이동하여 서비스 설정을 수정할 수 있습니다.
엔드포인트 상세 페이지는 서비스의 현재 상태에 따라 페이지 상단에 상황별 알림 배너를 표시합니다:
서비스를 준비하고 있습니다: 서비스가 배포 중이거나 상태 전환 중일 때 표시됩니다. 서비스가 아직 요청을 처리할 준비가 되지 않았음을 나타냅니다.
서비스가 준비되었습니다: 서비스 상태가
HEALTHY일 때 표시됩니다. 이 배너에는 LLM 채팅 테스트 인터페이스로의 바로가기를 제공하는 채팅 시작 버튼이 포함됩니다.이 모델 서비스는 다른 프로젝트에 속해 있습니다: 엔드포인트가 현재 선택된 프로젝트와 다른 프로젝트에 속할 때 표시됩니다. 이 알림이 표시되는 동안
수정버튼은 비활성화됩니다. 알림의 프로젝트 전환 버튼을 클릭하여 올바른 프로젝트로 전환하고 엔드포인트를 관리할 수 있습니다.
리비전 정보#
리비전 정보 카드는 서버가 Model Card v2를 지원하는 경우 (Backend.AI 버전 26.4.0 이상)에 사용할 수 있습니다.
엔드포인트 상세 페이지의 리비전 정보 카드는 최신 리비전 — 다음에 적용될 예정인 리비전의 구성을 표시합니다. 이는 현재 서비스에서 실행 중인 리비전과 다를 수 있습니다.
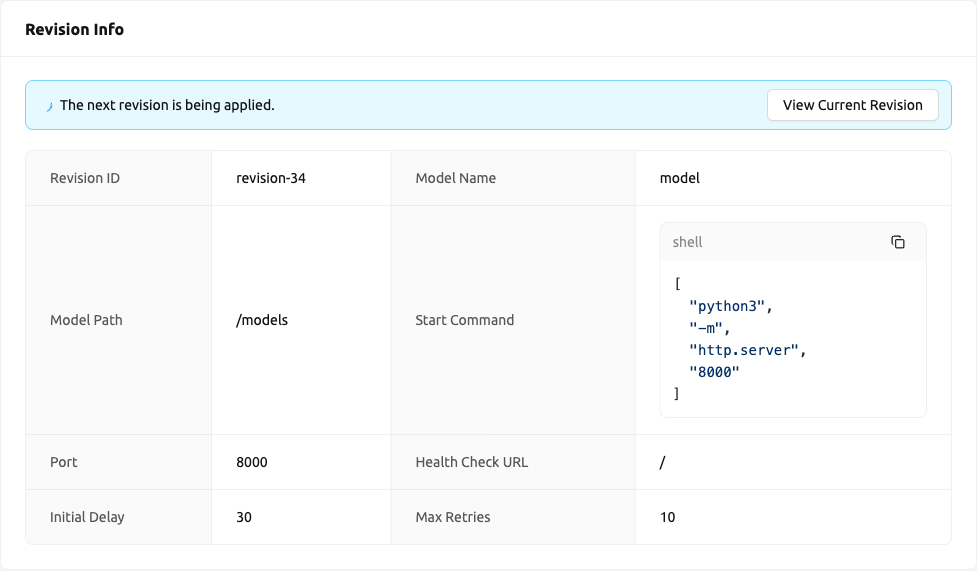
카드에는 다음 필드가 표시됩니다:
- Revision ID: 최신 리비전의 식별자입니다.
- Model Name: 모델 정의에서 정의된 모델 이름입니다.
- Model Path: 모델이 마운트된 경로입니다.
- Start Command: 추론 서버를 시작하는 데 사용되는 명령어입니다.
- Port: 모델 서비스를 위한 컨테이너 포트입니다.
- Health Check Path: 상태 확인을 위한 HTTP 엔드포인트 경로입니다.
- Initial Delay: 첫 번째 상태 확인 전 대기 시간(초)입니다.
- Max Retries: 허용되는 최대 연속 상태 확인 실패 횟수입니다.
리비전 불일치 상태#
새 리비전이 대기열에 추가되었지만 서비스가 여전히 이전 리비전에서 실행 중인 경우, 리비전 정보 카드에 "다음 리비전을 적용 중입니다." 알림이 표시됩니다. 이는 카드에 표시된 최신 리비전 값이 현재 실행 중인 구성과 아직 일치하지 않음을 나타냅니다.

현재 리비전 보기 버튼을 클릭하면 현재 실행 중인 리비전의 모델 정의를 보여주는 모달이 열립니다. 이를 통해 예정된 리비전(리비전 정보 카드에 표시됨)과 현재 활성 리비전(모달에 표시됨)을 비교할 수 있습니다.
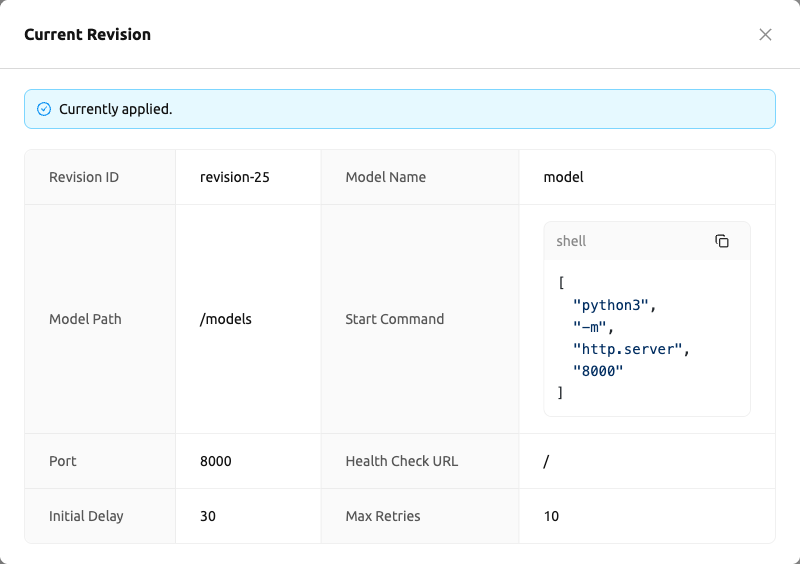
요약하면: 리비전 정보 카드는 항상 최신/예정된 리비전 값을 표시하고, 현재 리비전 보기 모달은 현재 실행 중인 리비전 값을 표시합니다.
리비전을 활용한 편집 동작 (Custom 변형 전용)#
Custom 런타임 변형을 사용하는 서비스에서 서비스 정보 패널의 수정 버튼을 클릭하면, 서비스 런처 폼에 최신 리비전의 모델 정의 값이 기본값으로 미리 채워집니다. 이를 통해 모든 필드를 다시 입력하지 않고도 설정을 점진적으로 조정할 수 있습니다.
이 모델 정의 값의 사전 채우기 동작은 Custom 런타임 변형에만 적용됩니다.
vLLM 및 SGLang 변형은 모델 정의 필드를 사용하지 않으며, 대신 프레임워크별 설정을 위한
런타임 파라미터 섹션(inference_runtime_config)을 제공합니다.
모델 정의와 런타임 파라미터는 리비전에 별도로 저장되는 서로 다른 개념입니다.
자동 스케일링 규칙#
자동 스케일링 규칙(Auto Scaling Rules)은 실시간 메트릭을 기반으로 모델 서비스의 레플리카 수를 자동으로 증감시킵니다. 이를 통해 낮은 사용량일 때는 리소스를 절약하고, 높은 사용량일 때는 요청 지연이나 실패를 방지할 수 있습니다.
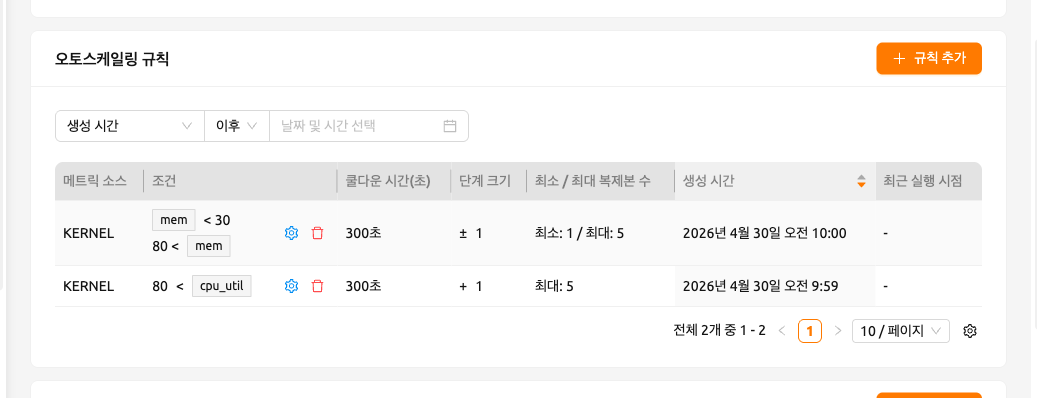
규칙 목록에서는 다음을 제공합니다:
- 생성 시간(Created At)과 최근 실행 시점(Last Triggered) 날짜-시간 범위로 규칙을 필터링할 수 있는 속성 필터 바.
- 서버 측 페이지네이션.
- 메트릭 소스(Metric Source), 조건(Condition), 쿨다운 초(Cooldown Sec.), 단계 크기(Step Size), 최소 / 최대 복제본 수(Min / Max Replicas), 생성 시간(Created At), 최근 실행 시점(Last Triggered) 컬럼. 단계 크기 컬럼은 설정한 조건에 따라
+,−,±부호가 자동으로 표시되므로, Scale Out 또는 Scale In을 명시적으로 선택할 필요가 없습니다. - 각 행의 조건 요약 옆에 표시되는 행별 편집 및 삭제 아이콘.
Add Rules 버튼을 클릭하면 오토스케일링 규칙 추가 편집기가 열립니다. 기존 규칙을 수정하려면 해당 행의 편집 아이콘을 클릭하세요. 규칙 값이 미리 채워진 상태로 오토스케일링 규칙 수정 편집기가 열립니다. 편집기에는 다음 필드가 순서대로 포함됩니다:
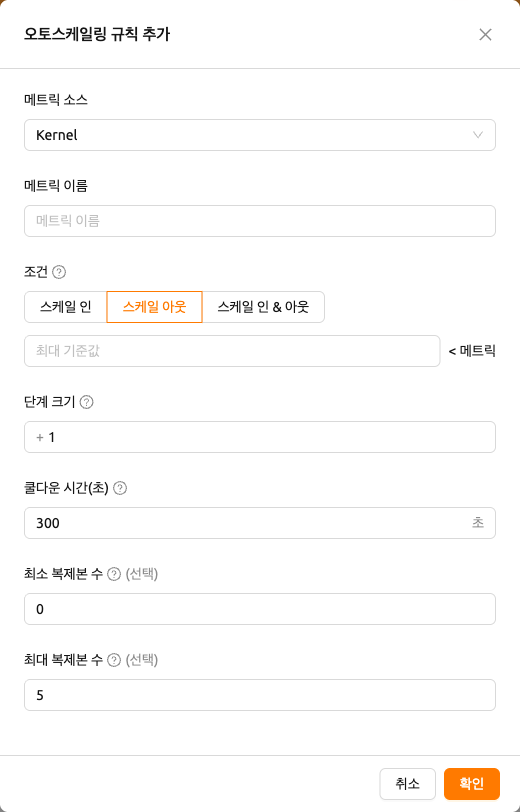
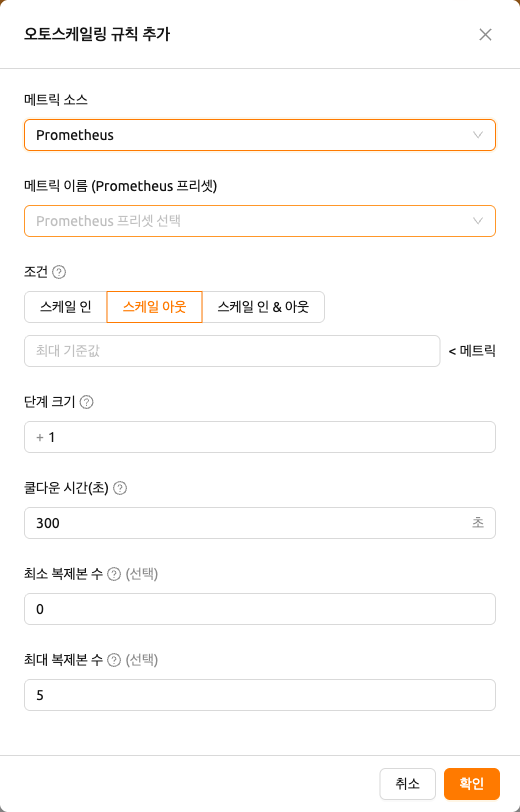
메트릭 소스(Metric Source):
Kernel,Inference Framework,Prometheus중 하나를 선택합니다.메트릭 이름(Metric Name):
Kernel과Inference Framework의 경우 메트릭 이름을 입력합니다.Kernel에서는cpu_util,mem,net_rx,net_tx와 같은 일반적인 메트릭이 자동 완성 제안으로 제공되며, 사용자 정의 이름을 자유롭게 입력할 수도 있습니다.메트릭 이름 프리셋(Metric Name (Prometheus Preset)): 메트릭 소스가
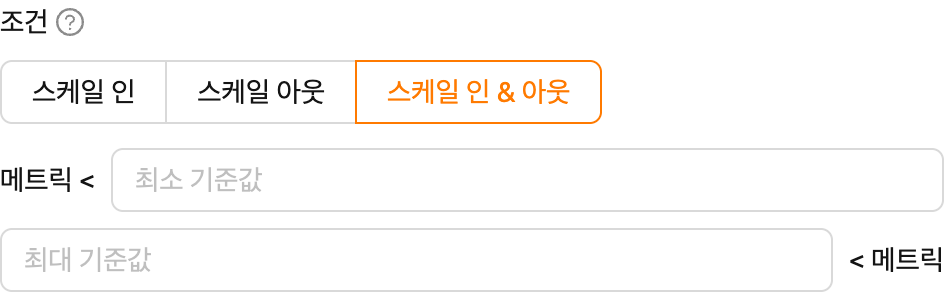
Prometheus일 때만 표시됩니다. 드롭다운에서 프리셋을 선택하면 프리셋의 메트릭 이름, 쿼리 템플릿, 그리고 (정의된 경우) 쿨다운 초(Cooldown Sec.)가 자동으로 채워집니다. 선택기 아래의 현재 값(Current value) 미리보기는 프리셋이 반환하는 최신 값을 새로 고침 버튼과 함께 표시합니다. 여러 시리즈가 반환되는 경우 미리보기에는 시리즈 수와 가장 최근 값이 표시되며, 사용 가능한 데이터가 없으면 사용 가능한 데이터가 없습니다(No data available)라고 표시됩니다.조건(Condition): 스케일링 방향을 선택하는 세그먼트 컨트롤입니다. 세 가지 옵션이 있습니다.
- Scale In: 메트릭이 임계값 아래로 떨어지면 복제본을 줄입니다.
Metric < [임계값]조건을 설정합니다. - Scale Out: 메트릭이 임계값 위로 올라가면 복제본을 늘립니다.
Metric > [임계값]조건을 설정합니다. - Scale In & Out: 메트릭이 설정한 범위를 벗어나는 방향에 따라 자동으로 축소 또는 확장합니다.
Metric < Min Threshold또는Metric > Max Threshold조건을 설정합니다.
- Scale In: 메트릭이 임계값 아래로 떨어지면 복제본을 줄입니다.
단계 크기(Step Size): 스케일링 이벤트마다 추가하거나 제거할 복제본 수를 지정하는 양의 정수입니다. 선택한 조건(Scale In / Scale Out / Scale In & Out)에 따라
-,+,±부호가 자동으로 표시됩니다.- 최솟값 임계값만 설정:
[metric] < [minThreshold]조건이 되면 스케일 인(Scale In)됩니다. - 최댓값 임계값만 설정:
[metric] > [maxThreshold]조건이 되면 스케일 아웃(Scale Out)됩니다. - 둘 다 설정:
[minThreshold] < [metric] < [maxThreshold]범위를 벗어나는 방향에 따라 스케일 인 또는 스케일 아웃됩니다.
- 최솟값 임계값만 설정:
쿨다운 초(Cooldown Sec.): 스케일링 이벤트 이후 다음 평가까지 대기하는 시간(초 단위)입니다.
최소 복제본 수(Min Replicas) 및 최대 복제본 수(Max Replicas): 자동 스케일링이 복제본 수에 대해 강제하는 하한과 상한입니다. 자동 스케일링은 복제본 수를 최소 복제본 수 아래로 줄이거나 최대 복제본 수 위로 늘리지 않습니다.
메트릭 소스(Metric Source)가 Prometheus로 설정되면 편집기에 프리셋 선택기와 실시간 현재 값(Current value) 미리보기가 표시됩니다.
토큰 생성#
모델 서비스가 성공적으로 실행되면 상태가
HEALTHY로 설정됩니다. 서빙 목록에서 해당 엔드포인트 이름을 클릭하여
상세 정보를 볼 수 있습니다. 라우팅 정보에서 서비스 엔드포인트를 확인할 수 있습니다.
서비스가 생성될 때 Open To Public 옵션이
활성화되면, 엔드포인트는 별도의 토큰 없이 공개적으로
액세스할 수 있습니다.
그러나 비활성화된 경우, 아래 설명된 대로 토큰을 발급하여
서비스가 제대로 실행되고 있는지 확인할 수 있습니다.
생성된 토큰 목록 오른쪽에 있는 Generate Token 버튼을
클릭합니다. 나타나는 모달에서
만료 날짜를 입력합니다.
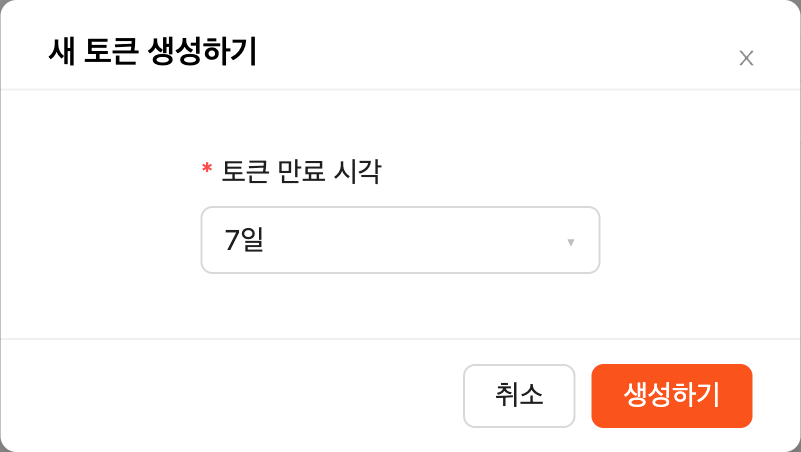
발급된 토큰은 생성된 토큰 목록에 추가됩니다. 각 토큰에는 상태(유효 또는 만료됨), 만료 날짜 및 생성 날짜가 표시됩니다. 토큰
항목에서 copy 버튼을 클릭하여 토큰을 복사하고, 다음 키의 값으로 추가합니다.

| Key | Value |
|---|---|
| Content-Type | application/json |
| Authorization | BackendAI |
라우트 정보#
라우트 정보 카드는 모델 서비스의 라우팅 상태를 보여줍니다. 다음 기준으로 라우트를 필터링할 수 있습니다:
- Running / Finished: 활성 라우트 노드와 완료된 라우트 노드 간 전환합니다.
- 속성 필터: 건강 상태 및 트래픽 상태로 필터링합니다.
라우트 노드를 클릭하면 세션 상세 드로어가 열리며, 개별 세션 세부 정보를 볼 수 있습니다.
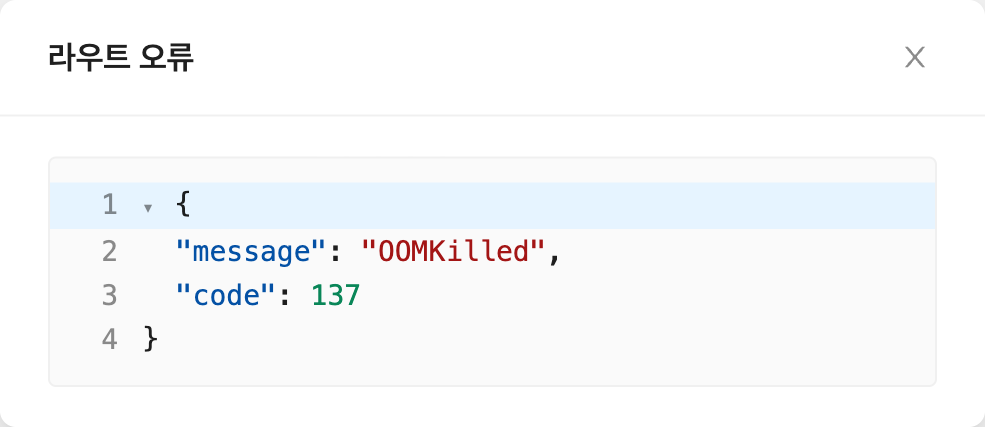
라우트에 오류가 발생한 경우, 라우트 행의 오류 표시기를 클릭하면 해당 라우트의 원시 오류 데이터를 표시하는 JSON 뷰어 모달이 열립니다. 이는 개별 라우트 노드의 문제를 진단하는 데 유용합니다.
서비스 수정#
엔드포인트 상세 페이지에서 수정 버튼을 클릭하여 모델 서비스를 수정합니다. 이전에 입력한 필드가 채워진 상태로 서비스 런처가 열립니다. 변경하려는 필드만 선택적으로 수정할 수 있습니다. 필드를 수정한 후 업데이트 버튼을 클릭하여 변경 사항을 적용합니다.
서비스 종료#
모델 서비스는 원하는 세션 수와 일치하도록 라우팅
수를 조정하기 위해 주기적으로 스케줄러를 실행합니다. 그러나 이것은
Backend.AI 스케줄러에 부담을 줍니다. 따라서 더 이상 필요하지 않은 경우
모델 서비스를 종료하는 것이 좋습니다. 모델 서비스를 종료하려면,
Controls 열에서 Delete 버튼을 클릭합니다. 모델 서비스를 종료할지
확인하는 모달이 나타납니다. Delete를
클릭하면 모델 서비스가 종료됩니다. 종료된 모델 서비스는
Destroyed 필터 뷰에 표시됩니다.
서비스 엔드포인트 접속#
API 요청 보내기#
모델 서빙을 완료하려면, 실제 엔드 유저와 정보를 공유하여 모델 서비스가 실행 중인 서버에 액세스할 수 있도록 해야 합니다. 서비스가 생성될 때 Open To Public 옵션이 활성화되면, 엔드포인트 상세 페이지에서 서비스 엔드포인트 값을 공유할 수 있습니다. 옵션이 비활성화된 상태로 서비스가 생성된 경우, 이전에 생성된 토큰과 함께 서비스 엔드포인트 값을 공유할 수 있습니다.
다음은 모델 서빙 엔드포인트로 요청을 보내는 것이 제대로 작동하는지 확인하는
curl 명령을 사용한 간단한 예시입니다:
export API_TOKEN="<token>"
export MODEL_SERVICE_ENDPOINT="<model-service-endpoint>"
curl -H "Content-Type: application/json" -X GET -H "Authorization: BackendAI $API_TOKEN" "$MODEL_SERVICE_ENDPOINT"기본적으로, 엔드 유저는 엔드포인트에 액세스할 수 있는 네트워크에 있어야 합니다. 서비스가 폐쇄된 네트워크에서 생성된 경우, 해당 폐쇄된 네트워크 내에서 액세스할 수 있는 엔드 유저만 서비스에 액세스할 수 있습니다.
LLM 채팅 테스트#
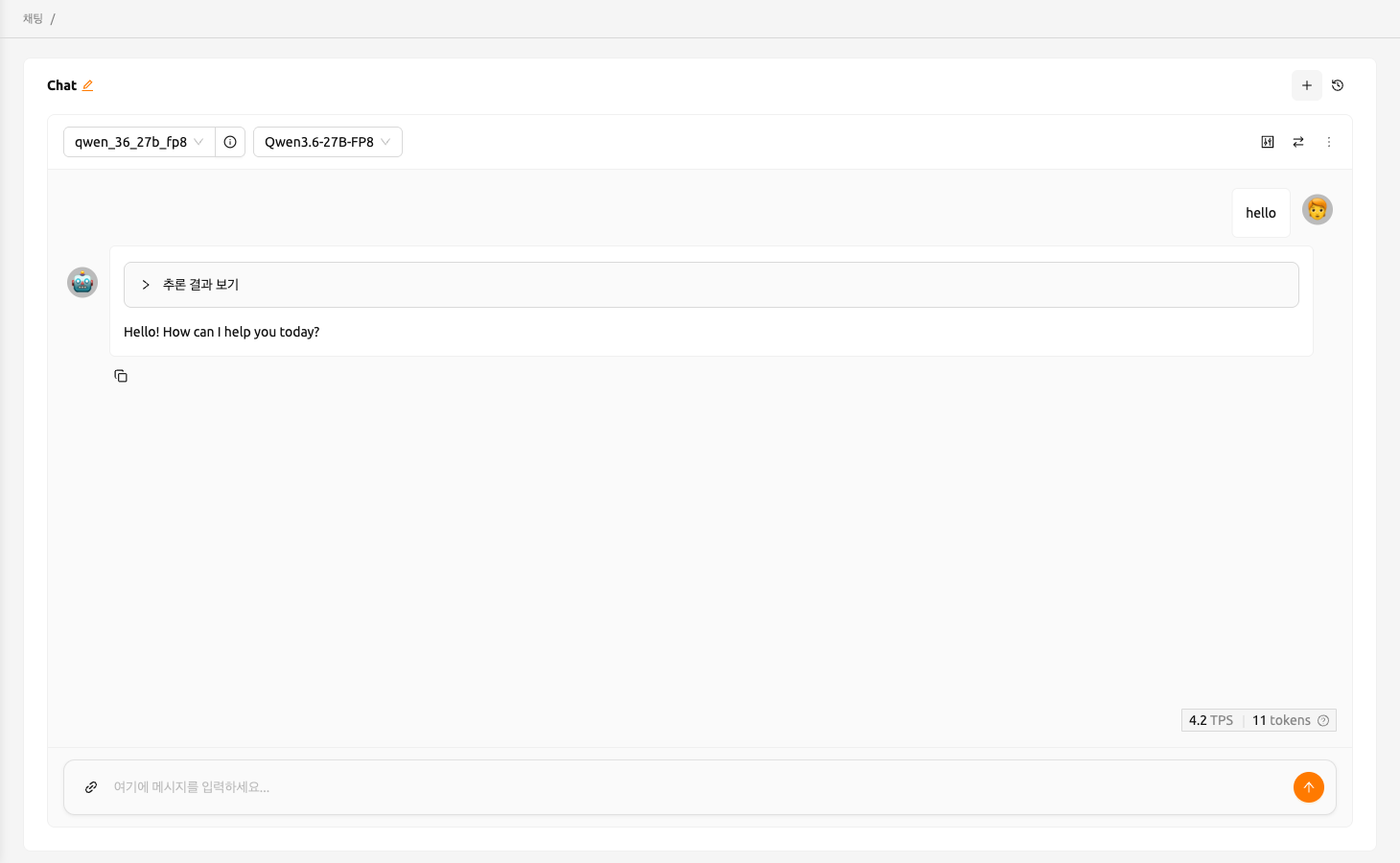
대형 언어 모델(LLM) 서비스를 생성한 경우, 실시간으로 LLM을 테스트할 수 있습니다.
엔드포인트 상세 페이지의 서비스 엔드포인트 섹션에 있는 LLM Chat Test 버튼을 클릭합니다.
생성한 모델이 자동으로 선택된 Chat 페이지로 리디렉션됩니다. Chat 페이지에서 제공되는 채팅 인터페이스를 사용하여 LLM 모델을 테스트할 수 있습니다. 채팅 기능에 대한 자세한 내용은 Chat 페이지를 참조하세요.
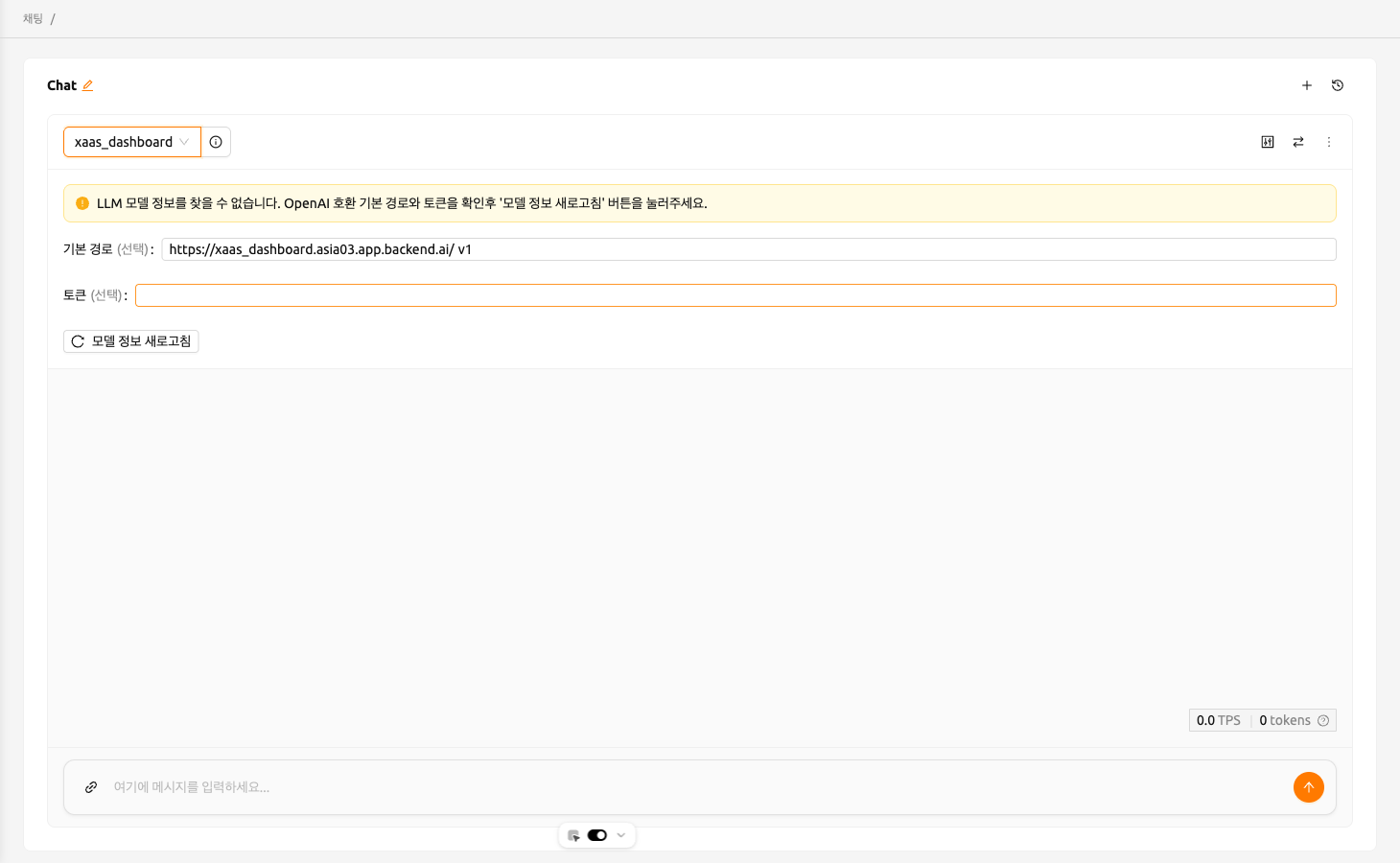
API 연결에 문제가 발생하면, Chat 페이지에 모델 설정을 수동으로 구성할 수 있는 옵션이 표시됩니다. 모델을 사용하려면 다음 정보가 필요합니다:
- baseURL (선택사항): 모델이 위치한 서버의 기본 URL입니다. 버전 정보를 포함해야 합니다. 예를 들어, OpenAI API를 사용할 때는 https://api.openai.com/v1을 입력해야 합니다.
- Token (선택사항): 모델 서비스에 액세스하기 위한 인증 키입니다. 토큰은 Backend.AI뿐만 아니라 다양한 서비스에서 생성할 수 있습니다. 형식과 생성 프로세스는 서비스에 따라 다를 수 있습니다. 자세한 내용은 항상 특정 서비스의 가이드를 참조하세요. 예를 들어, Backend.AI에서 생성된 서비스를 사용할 때는 토큰 생성 방법에 대한 지침은 토큰 생성 섹션을 참조하세요.
모델 스토어#
모델 스토어(Model Store)는 사전 구성된 모델을 탐색, 검색 및 배포할 수 있는 카드 기반 갤러리를 제공합니다. 사이드바 메뉴에서 모델 스토어에 접근할 수 있습니다.
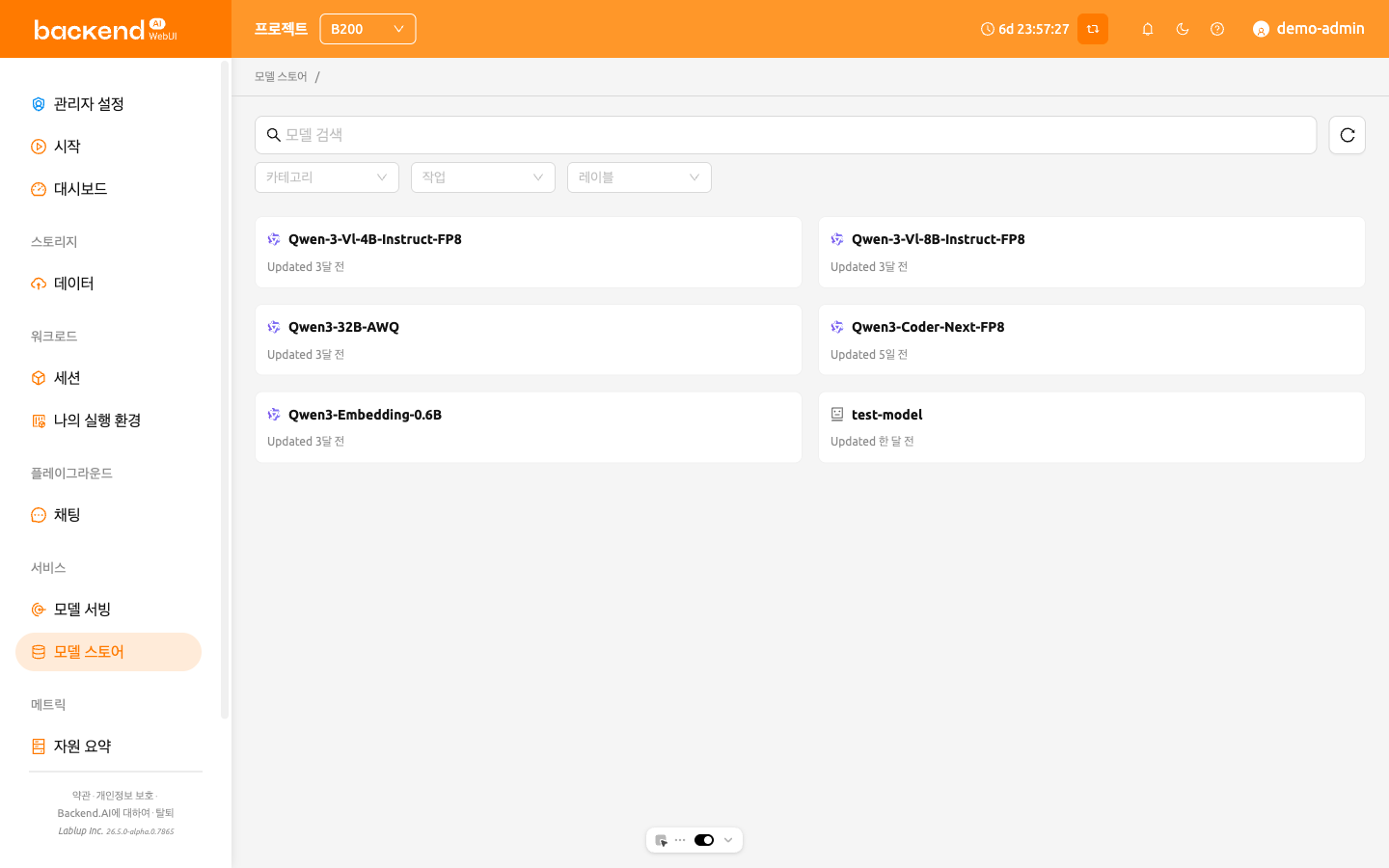
모델 탐색 및 검색#
페이지 상단은 검색 및 정렬 레이아웃을 사용합니다:
- 모델 검색(Search Models): 이름으로 필터링(Filter By Name) 속성 필터를 사용하여 이름으로 모델 카드를 검색합니다.
- 정렬(Sort): 결과 정렬 방식을 선택합니다. 사용 가능한 옵션은
이름 (A→Z),이름 (Z→A),오래된 순,최신 순입니다. - 새로 고침(Refresh): 새로 고침 버튼을 클릭하여 카드 목록을 다시 로드합니다.
각 카드에는 모델 브랜드 아이콘, 제목(제목이 설정되지 않은 경우 이름), 태스크(Task) 태그, 상대 생성 시간, 그리고 아이콘과 함께 작가(Author)가 표시됩니다. 현재 프로젝트에 호환 가능한 프리셋이 없는 카드는 50% 투명도로 표시됩니다. 이러한 카드를 열어 상세 정보를 볼 수는 있지만, 배포(Deploy) 버튼은 비활성화되고 Drawer에 호환 가능한 프리셋이 없습니다. 이 모델은 배포할 수 없습니다. 라는 오류 알림이 표시됩니다.
서버에 MODEL_STORE 프로젝트가 설정되어 있지 않으면, 페이지에는 관리자에게 문의하라는 안내와 함께 모델 스토어 프로젝트를 찾을 수 없습니다 메시지가 표시됩니다. 필터와 일치하는 모델 카드가 없으면 모델을 찾을 수 없습니다라고 표시됩니다.
목록은 하단에서 페이지네이션됩니다. 페이지 크기는 10, 20, 50개 항목 중에서 변경할 수 있습니다.
모델 카드 상세 정보#
카드를 클릭하면 페이지 오른쪽에 모델 카드 Drawer가 열립니다. Drawer 상단에는 모델 제목과 설명이 표시되고, 그 다음 태스크, 카테고리, 라벨, 라이선스 태그가 이어지며, 다음 항목을 포함한 상세 목록이 표시됩니다:
- 작가(Author)
- 아키텍처(Architecture)
- 프레임워크(Framework) (각 프레임워크는 아이콘과 함께 표시)
- 버전(Version)
- 생성 시간(Created) 및 마지막 수정(Last Modified) 타임스탬프
- 모델 폴더(Model Folder): 모델 스토리지 폴더의 폴더 탐색기를 여는 클릭 가능한 링크
- 최소 리소스(Min Resource): 최소 리소스 요구 사항(CPU, 메모리, GPU)
모델 카드에 README가 포함된 경우, Drawer 하단에 README.md 카드로 렌더링됩니다.
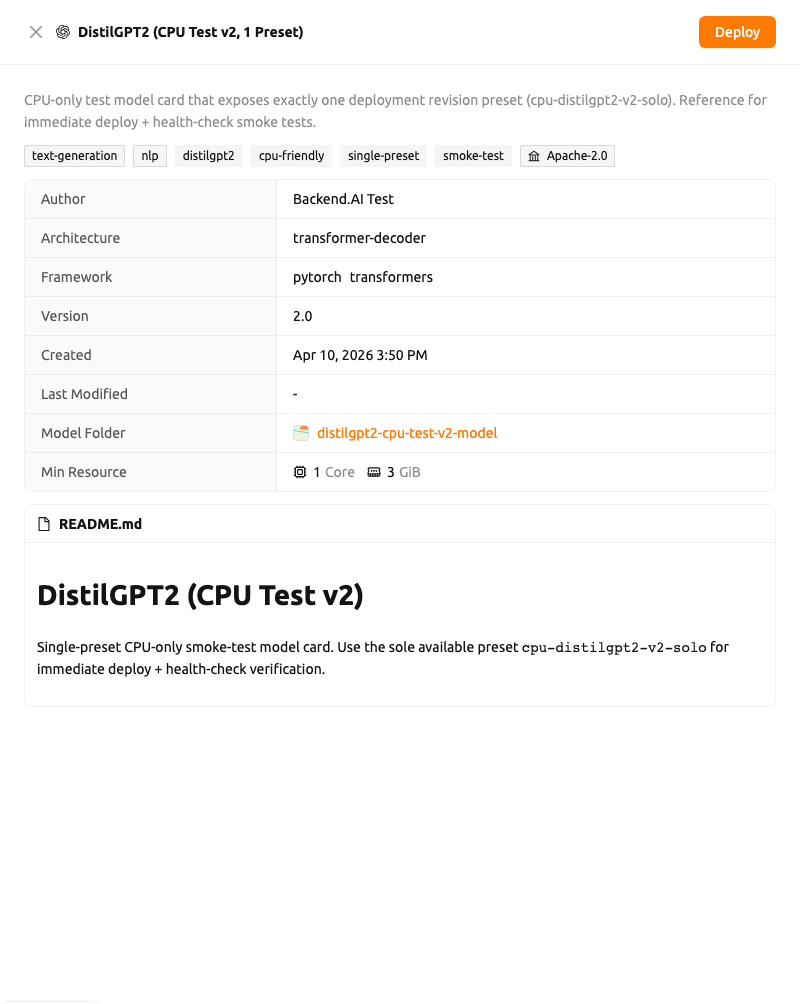
모델 배포#
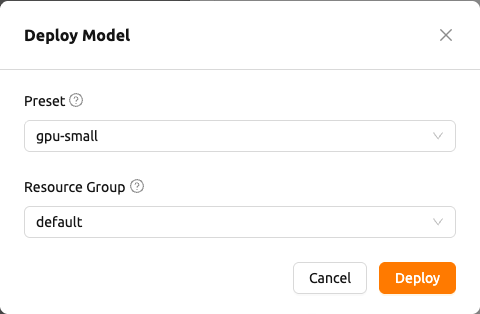
Drawer 헤더의 배포(Deploy) 버튼을 클릭하여 모델을 서비스로 배포합니다. 배포 흐름은 다음 두 가지 방식 중 하나로 동작합니다:
자동 배포: 모델에 사용 가능한 프리셋이 정확히 하나 있고 현재 프로젝트에 접근 가능한 자원 그룹이 정확히 하나 있으면, 모달을 표시하지 않고 배포가 조용히 생성됩니다. 엔드포인트가 쿼리 가능해진 후 해당 엔드포인트 상세 페이지로 이동합니다.
모델 배포 모달(Deploy Model): 그렇지 않은 경우, 모델 배포 모달이 다음 필수 필드와 함께 열립니다.
- 프리셋(Preset): 사용 가능한 자원 프리셋의 그룹화된 드롭다운입니다. 프리셋이 여러 런타임 변형에 걸쳐 있는 경우 옵션은 런타임 변형 이름별로 그룹화되고, 그렇지 않은 경우 평면 목록으로 표시됩니다.
- 자원 그룹(Resource Group): 서비스가 실행될 자원 그룹입니다.
모달의
배포(Deploy)버튼을 클릭하여 배포를 시작합니다. 모델이 배포되었음을 확인하는 성공 토스트가 표시되고, 엔드포인트 상세 페이지로 이동합니다.
선택한 모델에 현재 프로젝트와 호환되는 프리셋이 없으면 Drawer의 배포(Deploy) 버튼이
비활성화되며, 호환되는 프리셋이 제공될 때까지 배포가 차단됩니다.